Playing with fq_codel in 2.4
-
@uptownvagrant The limit value has now also been reset to the default of 10240, the only tuned value in my rules now is basically quantum and the masks been reversed. Thanks for your help.
Also I do agree that tuning can most definitely make things worse, the enqueue stuff that appears in logs is caused by the limit value been set too low, which is probably why it has a high default. The bufferbloat website suggests reducing it when speed is below 100mbit, but I tested their recommendation and it generated lots of enqueue over limit warnings, which as muppet pointed if too many of them appear it can bring down the OS.
-
I was able to test Steam distributed downloads using your config minus the masks. I was not able to recreate your findings and I'm still wondering if the interactive flow drops, SSH session, were due to something upsteam from you or there was a very low probability hash collision. If it was consistent then a hash collision is highly improbable.
Notes:
- My testing with Flent and netperf actually pushes more pps and more flows then what I saw with Steam.
- The bandwidths configured to your values are a very small percentage of what my lab upstream up/down limits are so those were not a factor in my testing.
- ICMP and HTTPS webUI traffic was not passing through the limiter. All other traffic was set to be placed in the limiter queues.
Limiters: 00001: 18.779 Mbit/s 0 ms burst 0 q131073 50 sl. 0 flows (1 buckets) sched 65537 weight 0 lmax 0 pri 0 droptail sched 65537 type FIFO flags 0x0 0 buckets 0 active 00002: 69.246 Mbit/s 0 ms burst 0 q131074 50 sl. 0 flows (1 buckets) sched 65538 weight 0 lmax 0 pri 0 droptail sched 65538 type FIFO flags 0x0 0 buckets 0 active Schedulers: 00001: 18.779 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 1 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 1 BKT Prot ___Source IP/port____ ____Dest. IP/port____ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0.0.0.0/0 0.0.0.0/0 193 9082 0 0 0 00002: 69.246 Mbit/s 0 ms burst 0 q65538 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail sched 2 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 2 0 ip 0.0.0.0/0 0.0.0.0/0 51106 76002641 29 43500 1209 Queues: q00001 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail q00002 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail
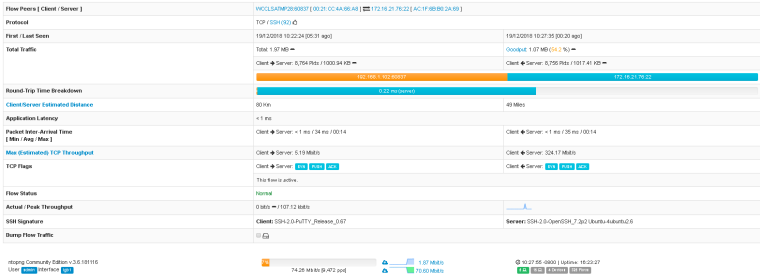
The RTT for almost all of these Steam servers was under 8 ms.
There were no drops associated with the SSH session I had from inside the LAN to outside the WAN.
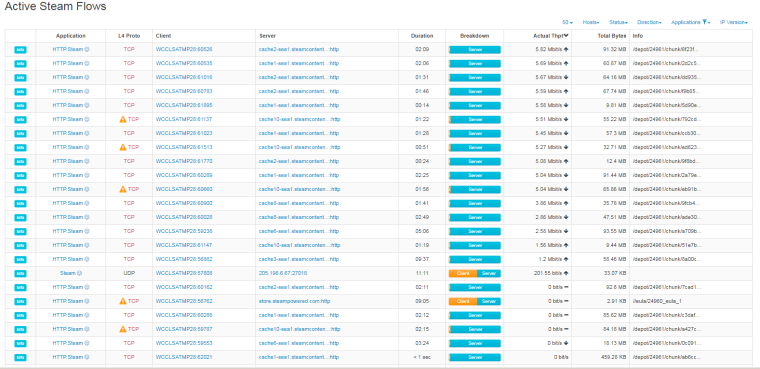
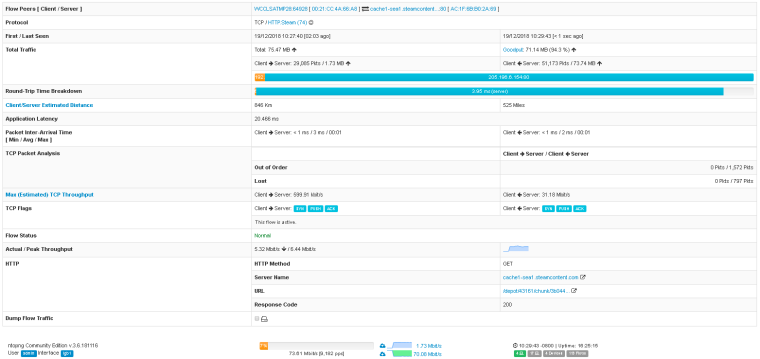
Here is a Steam download flow where you see many drops associated.
-
I wouldnt worry over it too much.
There is too many variables here, Operating System, Hardware used, RTT to download servers, capacity of connection, congestion provider used and so on.
I originally had really bad issues which I detailed earlier in the thread, when I changed the hardware in my pfsense unit it was improved, then it became minor issues only on a few scenarios with steam been one of them, changing the masks so steam downloads have their own dynamic queue made it perfect for me, but because you cannot get the same issue yourself it doesnt mean is a problem, its fine everyone is happy with what they have here. :)
I have also slightly decreased my pipe size a bit further so I can get perfect results on 32 threaded dslreports test as well. It seems it was slightly too high for that.
pfSense CE 2.8.1
-
@uptownVagrant may I know what is this rule for? I tried to enable this rule only, but it only bypass the limiters. What's the difference between this rule #3 and rule #4
3.) Add a match rule for incoming state flows so that they're placed into the FQ-CoDel in/out queues
- Action: Match
- Interface: WAN
- Direction: in
- Address Family: IPv4
- Protocol: Any
- Source: any
- Destination: any
- Description: WAN-In FQ-CoDel queue
- Gateway: Default
- In / Out pipe: fq_codel_in_q / fq_codel_out_q
- Click Save
-
@knowbe4 Floating rule #3 is to match flows that are ingress to the firewall WAN port and a state is created - an example could be traffic destined for a port you are forwarding into your LAN. Floating rule #4 is to match flows that are egress, leaving the WAN port and a state is created.
Rule #3 and #4 explicitly places flows into the limiter queues. If you have configured other floating rules, that are matching after the limiter rules, those may be bypassing the limiter.
-
Forgive me if this was covered here, I tried to read it all and got my fq-codel set up well thanks to this.
However, traceroute will only show 1 hop on windows clients. From the pfsense router cli, it shows the proper hops.
C:\WINDOWS\system32>tracert google.comTracing route to google.com [172.217.3.110]
over a maximum of 30 hops:1 <1 ms <1 ms <1 ms router.lan [192.168.1.1]
2 1 ms 1 ms 1 ms sea09s17-in-f14.1e100.net [172.217.3.110]From router:
traceroute google.com
traceroute to google.com (172.217.3.110), 64 hops max, 40 byte packets
(Hid first 4 hops to not give away location)
5 72.14.208.130 (72.14.208.130) 5.587 ms 5.172 ms 3.809 ms
6 * * *
7 216.239.62.148 (216.239.62.148) 4.472 ms
216.239.62.168 (216.239.62.168) 4.947 ms 4.957 ms
8 209.85.253.189 (209.85.253.189) 2.687 ms 2.850 ms
209.85.244.65 (209.85.244.65) 2.915 ms
9 sea09s17-in-f14.1e100.net (172.217.3.110) 2.524 ms
209.85.254.129 (209.85.254.129) 5.549 ms
216.239.56.17 (216.239.56.17) 4.269 ms -
@robnitro Take a look at the following guide as it should explain the issue you are witnessing and show how to workaround it - hint floating rule #1.
https://forum.netgate.com/post/807490
-
Thanks, I did add that rule for both WAN and LAN.
The only difference is that my setup has the rules based on LAN, because I have FIOS. The cable boxes video on demand VOD, can watch video above my 50mbit limit, they arent part of my QOS (by floating rule for the cable boxes IPs in an alias) because if they were, I would lose my 50mbit data max. Example: HD stream 16 mbit, I still can get 50mbit data. So the boxes are outside codel and/or HSFC.
When I have limiters by WAN, using client IP's in floating rules to not be a part of the limiter doesn't work most of the time. I think it's because the traffic is technically coming into the router WAN ip address and leaving from the WAN ip address... not the local address which only exists on LAN communication.
-
I have two ISP (10Mbps + 15Mbps symmetric) that currently config load balance in pfsense. I did follow your config for fq_codel on both WANs. I think both WANs are working as they are limiting their Download and Upload speed.
But later I found a problem, when I tried to upload a file to google drive, sometimes it doesn't upload at full speed (10KBps flat), sometimes it does. I'm not quite sure if is related to fq_codel, but when i tried to disable the floating rules that related to fq_codel, it always upload at full speed of my bandwidth.
here's my config;

I hope you can help me with this problem.
Findings that may help:
- When floating rules is enabled, load balancing on download speed is working but on upload is not working. Also all upload traffic always stick on default gateway even load balancing is enabled.

-
I just tried with the floating rules on WAN instead of LAN, omitting the cable boxes (STBs) and my desktop. So, it seems that if a rule is on WAN, you cannot use source or destination IP to omit a client from the queue.
Just to remind, on fios, you can have a 50/50 line but the cable boxes video on demand do not count towards the limit. Example: No limiters: watch a 16 mbit stream on cable box, speed tests will give 50 mbit. But put 50mbit limiter for all- 16 mbit stream, desktop will get 34 mbit.Only LAN based rules seem to work for me to exclude the cable boxes from the limiter.
I also have separate limiters for guest wifi clients that give them 20mbit, and this also has to be done on LAN floating rules, unfortunately.
I wonder if there could be a tiered form of queues that feed into eachother.
Example: main fqc queue 50, guests under that with a simple limiter of 20- instead of needing to have 2 separate queues of 50 and 20 (which traffic is not joined together) -
Can you use the fq_codel in/out limiters in conjunction with the standard traffic shaping?
-
You could, but not on the same interface. WAN with shaper and LAN with limiter would work I think for example.
-
I'm using shapers with the limiters on LAN. Before fqcodel, I was using plain limiters to keep guests on Wi-Fi from hogging connection with their apple updates.
With fq codel, i kept the same limiter speeds just changed the scheduler. I also added a fq codel limiter for those that aren't throttled and excluded the cable boxes as they aren't included in the isp speed limit (fios)
Unfortunately, I cannot use a single fq codel for everyone this way, but it doesn't seem to affect buffer bloat.
Limiters I have:
Schedulers: 00001: 27.000 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 1 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 80ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 1 00002: 28.000 Mbit/s 0 ms burst 0 q65538 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail sched 2 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 80ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 2 00004: 30.000 Mbit/s 0 ms burst 0 q65540 50 sl. 0 flows (1 buckets) sched 4 weight 0 lmax 0 pri 0 droptail sched 4 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 80ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 4 00005: 47.000 Mbit/s 0 ms burst 0 q65541 50 sl. 0 flows (1 buckets) sched 5 weight 0 lmax 0 pri 0 droptail sched 5 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 80ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 5 00006: 48.000 Mbit/s 0 ms burst 0 q65542 50 sl. 0 flows (1 buckets) sched 6 weight 0 lmax 0 pri 0 droptail sched 6 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 80ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 6 00007: 29.000 Mbit/s 0 ms burst 0 q65543 50 sl. 0 flows (1 buckets) sched 7 weight 0 lmax 0 pri 0 droptail sched 7 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 80ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 3 Queues: q00001 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail q00002 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail q00003 50 sl. 0 flows (1 buckets) sched 7 weight 0 lmax 0 pri 0 droptail q00004 50 sl. 0 flows (1 buckets) sched 4 weight 0 lmax 0 pri 0 droptail q00005 50 sl. 0 flows (1 buckets) sched 5 weight 0 lmax 0 pri 0 droptail q00006 50 sl. 0 flows (1 buckets) sched 6 weight 0 lmax 0 pri 0 droptailHSFC traffic shaping limiters
QUEUE BW SCH PRI PKTS BYTES DROP_P DROP_B QLEN BORRO SUSPE P/S B/S root_em0 64M hfsc 0 0 0 0 0 0 0 0 qInternetOUT 48M hfsc 0 0 0 0 0 0 0 qACK 8640K hfsc 12043K 703M 0 0 0 3 215 qP2P 960K hfsc 42429K 45636M 0 0 0 64 83005 qVoIP 512K hfsc 0 0 0 0 0 0 0 qGames 9600K hfsc 3576K 592M 0 0 0 0 0 qOthersHigh 9600K hfsc 2463K 665M 0 0 0 4 811 qOthersLow 2400K hfsc 0 0 0 0 0 0 0 qDefault 7200K hfsc 1815K 1170M 0 0 0 8 975 qNoLimiterSTB 4000K hfsc 0 0 0 0 0 0 0 qLink 640K hfsc 0 0 0 0 0 0 0 root_em1 490M hfsc 0 0 0 0 0 0 0 0 qLink 98M hfsc 0 0 0 0 0 0 0 qInternetIN 47M hfsc 0 0 0 0 0 0 0 qACK 8460K hfsc 838180 106M 0 0 0 6 374 qP2P 940K hfsc 27924K 14986M 0 0 0 24 2656 qVoIP 512K hfsc 0 0 0 0 0 0 0 qGames 9400K hfsc 1334 581495 0 0 0 0 0 qOthersHigh 9400K hfsc 8497K 5911M 0 0 0 4 618 qOthersLow 2350K hfsc 5315K 7804M 0 0 0 0 0 qDefault 7050K hfsc 18785K 17996M 0 0 0 32 6931 qNoLimiterSTB 320M hfsc 55549 78583K 0 0 0 0 0 -
@uptownvagrant Thanks for the guide, it is working perfectly for me on my Cable WAN (very bad bufferbloat). I'm trying to use it for my VDSL WAN as well but running into an odd issue. if I have the out floating rule enabled then my upload speed is exceptionally slow, no matter how the limiter is configured. If I disable the out floating rule and leave only the in one then upload speed is fine (but bufferbloat is back). The in rule works fine and gets rid of the download bufferbloat.
http://www.dslreports.com/speedtest/45277068 - this shows it with the out floating rule enabled
http://www.dslreports.com/speedtest/45277501 - and this is it with it disabled
Any ideas?
TIA
-
@csutcliff Hmm, let's start with this. Can you post the following output from the configuration that's not working with the VDSL circuit?
- Diagnostics / Limiter Info
- Diagnostics / Edit file - /tmp/rules.limiter
- Add something unique to the description of your floating rules, like the word "FQ-CoDel", and then go to Diagnostics / Command Prompt and execute
pfctl -vvsr | grep "FQ-CoDel"You should get something like the following:
@59(1545172581) match in on igb0 inet all label "USER_RULE: FQ-CoDel WAN-IN" dnqueue(1, 2) @60(1545172613) match out on igb0 inet all label "USER_RULE: FQ-CoDel WAN-OUT" dnqueue(2, 1) -
Is this normal? our dnqueue is opposite, I follow your guide.
@109(1546845642) match in on re0 inet all label "USER_RULE: ETPI-In FQ-CoDel queue" dnqueue(2, 1) @110(1546845723) match out on re0 inet all label "USER_RULE: ETPI-Out FQ-CoDel queue" dnqueue(1, 2)Also hope you can help me with my problem, Implementing your configuration on Dual-WAN (Load Balance ) setup on pfSense.
-
Thanks for the reply, here is my limiter info. The 382.375/20.910 Mbit/s ones are my cable WAN, the 62.000/17.500Mbit/s is for my VDSL. First two queues are cable, last two are VDSL.
Limiters: 00001: 382.375 Mbit/s 0 ms burst 0 q131073 50 sl. 0 flows (1 buckets) sched 65537 weight 0 lmax 0 pri 0 droptail sched 65537 type FIFO flags 0x0 0 buckets 0 active 00002: 20.910 Mbit/s 0 ms burst 0 q131074 50 sl. 0 flows (1 buckets) sched 65538 weight 0 lmax 0 pri 0 droptail sched 65538 type FIFO flags 0x0 0 buckets 0 active 00003: 62.000 Mbit/s 0 ms burst 0 q131075 50 sl. 0 flows (1 buckets) sched 65539 weight 0 lmax 0 pri 0 droptail sched 65539 type FIFO flags 0x0 0 buckets 0 active 00004: 17.500 Mbit/s 0 ms burst 0 q131076 50 sl. 0 flows (1 buckets) sched 65540 weight 0 lmax 0 pri 0 droptail sched 65540 type FIFO flags 0x0 0 buckets 0 active Schedulers: 00001: 382.375 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 1 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 300 limit 10240 flows 20480 ECN Children flowsets: 1 BKT Prot ___Source IP/port____ ____Dest. IP/port____ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0.0.0.0/0 0.0.0.0/0 7 470 0 0 0 00002: 20.910 Mbit/s 0 ms burst 0 q65538 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail sched 2 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 300 limit 10240 flows 20480 ECN Children flowsets: 2 0 ip 0.0.0.0/0 0.0.0.0/0 4 218 0 0 0 00003: 62.000 Mbit/s 0 ms burst 0 q65539 50 sl. 0 flows (1 buckets) sched 3 weight 0 lmax 0 pri 0 droptail sched 3 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 100ms quantum 300 limit 10240 flows 20480 ECN Children flowsets: 3 00004: 17.500 Mbit/s 0 ms burst 0 q00004 50 sl. 0 flows (1 buckets) sched 4 weight 1 lmax 0 pri 0 droptail sched 4 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 100ms quantum 300 limit 10240 flows 20480 ECN Children flowsets: 4 Queues: q00001 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail q00002 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail q00003 50 sl. 0 flows (1 buckets) sched 3 weight 0 lmax 0 pri 0 droptail q00004 50 sl. 0 flows (1 buckets) sched 4 weight 1 lmax 0 pri 0 droptail/tmp/rules.limiter
pipe 1 config bw 382375000b droptail sched 1 config pipe 1 type fq_codel target 5ms interval 100ms quantum 300 limit 10240 flows 20480 ecn queue 1 config pipe 1 droptail pipe 2 config bw 20909500b droptail sched 2 config pipe 2 type fq_codel target 5ms interval 100ms quantum 300 limit 10240 flows 20480 ecn queue 2 config pipe 2 droptail pipe 3 config bw 62000Kb droptail sched 3 config pipe 3 type fq_codel target 5ms interval 100ms quantum 300 limit 10240 flows 20480 ecn queue 3 config pipe 3 droptail pipe 4 config bw 17500Kb droptail sched 4 config pipe 4 type fq_codel target 5ms interval 100ms quantum 300 limit 10240 flows 20480 ecn queue 4 config pipe 4 droptailpfctl -vvsr | grep "FQ-CoDel"
@66(1548714795) match in on igb0 inet all label "USER_RULE: VIRGIN_WAN_DL FQ-CoDel queue" dnqueue(1, 2) @67(1548714885) match out on igb0 inet all label "USER_RULE: VIRGIN_WAN_UL FQ-CoDel queue" dnqueue(2, 1) @71(1548715528) match in on pppoe0 inet all label "USER_RULE: AAISP_WAN_DL FQ-CoDel queue" dnqueue(3, 4) @72(1548722103) match out on pppoe0 inet all label "USER_RULE: AAISP_WAN_UL FQ-CoDel queue" dnqueue(4, 3) -
@csutcliff Hmm, I don't have a VDSL2 PPPoE connection to test with but I'm wondering if the following thread may point you down the correct path.
https://lists.freebsd.org/pipermail/freebsd-ipfw/2016-April/006161.html
Also, why do you have your VDSL limiters set above what you are seeing in the speed test results when you don't have them enabled? Can you try setting both limiters to 80% or 85% of your speed test result and then work up from there - keeping an eye on buffering each subsequent test?
-
@chrcoluk just a quick note after some additional testing. I believe I ran into what you were seeing when the number of active states passing through the limiter queues far exceeded the FQ-CoDel flows value and flows were not being separated any longer. Increasing the FQ-CoDel flows value allowed flow separation to be maintained and interactive flow packets were not being sent to sub-queues where non interactive flow packets were also being sent.
-
@uptownvagrant I'll have a read, thanks.
Regarding the limiters settings, I obviously haven't been able to tune the upstream setting yet (I've got it at just under 95% of the sync speed) but I have tried it set at only 10Mbit/s and it makes no difference.
For the dowstream, my sync is over 65Mbit/s and I've settled on 62Mbit/s after trial an error to see what value eliminated bufferbloat whilst keeping as much bandwidth available as possible. The reason you don't see 65+ on the speed test without the limiters is because my ISP allows me to set the sending rate on the download which I have set to 95% of sync, this is meant to help with bufferbloat and improve VOIP etc because the link is never 100% pegged and in theory stops the wholesale ISP (their supplier) buffers getting involved.
Edit: had a read of the thread you linked. I don't think any of that applies here as I'm using plain PPPoE not PPPoA, I have a full 1500 MTU to the internet thanks to baby jumbo frames (1508 to the modem to account for the PPPoE header) and my upload speed is not restrictive like in the example, in fact it's only a couple of Mbit/s shy of the cable connection that works fine.