PfSense Crashed (2nd time in 3 weeks) - Hardware or Software?
-
Ok so for the 2nd time in 3 weeks my pfSense box was crashed and I had no internet at the house.
First time I'm pretty sure was my fault, I was installing and tinkering with packages like Snort, Suricata, pfBlockNG and the like. I was also running off USB sticks, and it's possible I was logging a bunch of stuff (so potentially killed the drives).
But this time, it has happened after I reverted to a more basic configuration and replaced the drives with USED SSDs I pulled out of a working computer, and turned off almost everything. My goal is to get to a VERY stable platform, then save that configuration before I start tinkering.
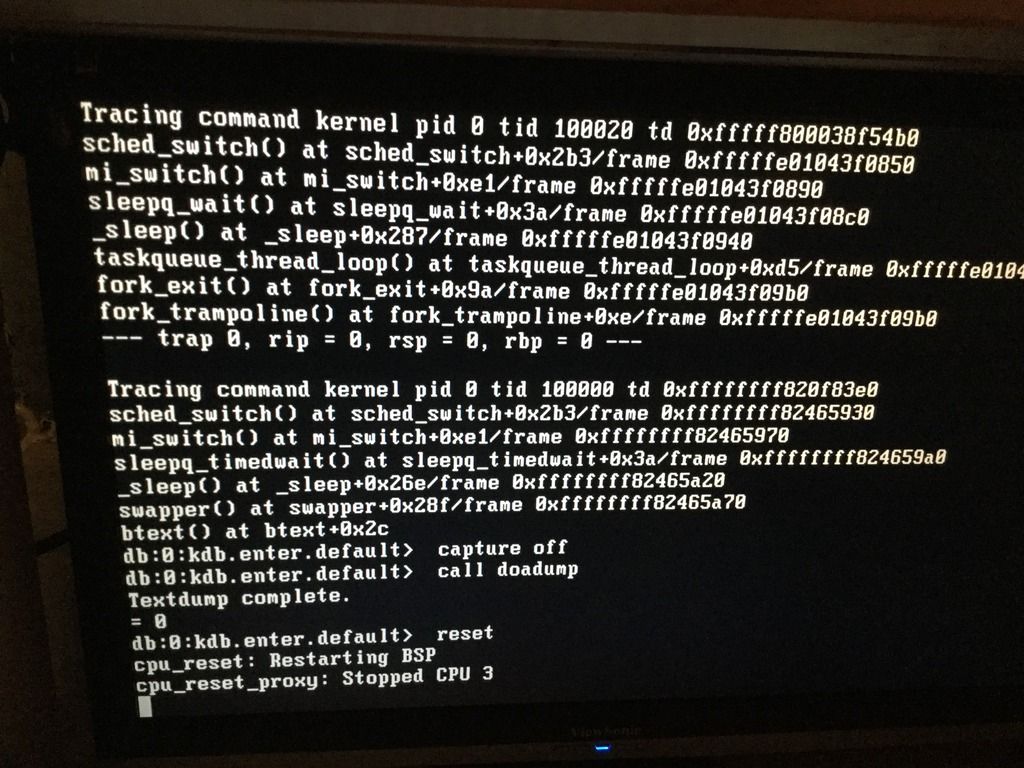
Here's the dump that was onscreen, a reset seemed to fix the appliance back up (but I noticed the GEOM mirror went into rebuilding state).
-
Ooop another important details, here's the version of pfSense I have running.
2.3.4-RELEASE (amd64)
built on Wed May 03 15:13:29 CDT 2017
FreeBSD 10.3-RELEASE-p19 -
You're asking HW or SW, but there's no details of any steps you've taken to check these out or narrow it down.
What hardware are you running and what's your take on its solidity?
What if any hardware checks have you done? For example, there are burn-in and stress tests to verify RAM (memtest86+), HDD+SSD tests (3rd party stress tests/reporting, and manufacturer tests), CPU, heat production and handling, which are the main ones you'd expect to hit on a router like this (unless you have specialised hardware like PCI devices, 10G, crypto cards or for some reason a 3 way graphics setup ;-) ).
Have you set any of those up and left them running a day, to see what they report? Have you swapped out hardware such as cables, storage (HDD/SSD/USB) and HDD/SSD ports? What about the PSU - do you have a way to swap that if need be, or to check if voltage and current stability are good?
Knowing zero about your system, I'd say, let's have the hw list first, and also a note of any alternate hardware you could swap for testing, to narrow down issues if it is hardware - even an extra USB stick or a temp drive from a laptop might be helpful if you can spare it for a couple of days.
Spare parts are cheap on EBay, so go there if you need to, for any of this stuff.
Initial comment
I'd suspect a hardware fault more than software initially, just because the system is pretty stable, and shouldn't be doing that. I've had uptimes of 3-12 months for years, running pfSense on old Core2 generation S775 hardware from the 2007-2008 era, and P4 from 2003 - 2005, running more than you're describing. The Core2s are still running my main platform, the P4s retired a year ago only because they didn't take the PCIe-era NICs I wanted (so much for "USED" hardware :) ) That's the sort of reliability I'd expect to see, virtually "set and forget". So as I said, my suspicion if you clean-installed and didn't mod it, is towards the hardware. The same thing about age applies to your SSD - I wouldn't worry initially about the age of things or new/used, like the SSD per se. For SSDs the brand and quality of SSDs is often a better indicator of expected reliability than whether it's used or new - I'm running Samsung, Intel 320s and 2 old OCZ vertex 3s, all good brands when bought, all 4-8 years old, on multiple servers, all still with pretty high I/O rates and not one's died yet (fingers crossed).
Back to your setup. Knowing nothing, and no idea about your technical knowhow, I'd start troubleshooting this way: Check the basics. Check heat, check your CPU and motherboard temperatures. Check the BIOS battery is good and you aren't losing BIOS settings of config (corrupt CMOS can result causing obscure errors). Check dust, fans, and connectors are firmly in. Check your power connectors. If you have a "known good" other PSU, consider swapping it afterwards if that doesn't get you anywhere. Move the SSD to a different sata port (or whatever it uses) and perhaps even a different cable or a spare SSD. pfSense doesn't need to access the SSD much, as long as you aren't low on RAM. If you disable RRD data (graphing) and other disk intensive functions like Squid/snort/PFBlocker (if present) you could probably run off USB for testing, although most SSDs are more reliable than most USBs.
I'd start by checking the obvious things - especially physical, connectors, ports etc - and swap the SSD if you have a spare, I'd test two things first - how that bunch of changes works for you, and what happens when you run memtest86+(memtest.org) for 24 hours or so. A couple of nights and the day in between anyway. A single red line any time in the run, and you've found unacceptable memory issues.
I'd also check your BIOS/EFI settings. DIsable sleep states, if it's a board that has them, look for settings related to voltage regulation and spread spectrum that impact stability. Generally spread spectrum should be disabled, and voltage stability medium or medium-high if settings allow (but this will impact heat production a lot, so ensure decent cooling or exposure to air). The BIOS manual usually covers these things well.
If the motherboard or PSU are old and you know how, look visually for exploded capacitors, which can lead to hw errors too. They're surprisingly infrequent, but just sometimes….. (But aim to find them mainly via stability tests like memtest and heat production tests, which will also pick up errors you can't find visually.)
Then come back and post an update.
When you've done that, a lot depends on your hardware and comments and what you find. Next steps might be to run a test/burn-in suite of some kind on it. Either one item at a time, or an "all in one" Linux boot CD or the Intel extreme burn-in suite. Some of these might be easy to do in BSD, some might need Linux, some might need you to temporarily plug in a blank disk, install Windows or Linux and run some GUI test software offline. Anything that comes as an ISO image can be put on USB instead for speed and to save plugging in a CD/DVD device. Your choice, any of those will do the job. Keep track of what you changed, and aim to eliminate some issues and test for others.
-
Fair enough, here's the hardware:
-
ASRock H110M-ITX LGA 1151 Intel H110 HDMI SATA 6Gb/s USB 3.0 Mini ITX
-
Intel Core i3-6100T 35W Processor
-
4GB (1 x 4GB) 288-Pin DDR4 SDRAM DDR4 2133 (PC4 17000)
-
SILVERSTONE SFX Series SST-ST30SF-V2 300W SFX 80 PLUS BRONZE Active PFC PSU
-
Used eBay IBM Intel I340-T4 Quad GB
-
3 - SanDisk 16GB Ultra Fit CZ43 USB 3.0 Flash Drive swapped these when the system stopped booting for used SanDisk 120GB SSD (I'm guessing these are 5+ years old)
Everything with the exception of the I340-T4 and the SSD's is brand new beginning of April-2017. I do understand this could just be early hardware failures, that maybe a burn-in would have found (something more intense than just running 24x7 for a month).
As for doing more testing (memtest etc), I'll have to find a quiet time to do, this thing is the guts of my home network. I'd really like to log the CPU usage and temperature data to my separate syslogd server so I could go back in and know those details after-the-fact. Is there a logging option in FreeBSD or pfSense that could send those details (it's already sending firewall and system logs)?
-
-
Note - I've added a para in the above post, about the BIOS. It's quite relevant since ASROck's normally good on the BIOS that way (one of mine's a Haswell-era ASRock that was a Windows 2012 server before moving it to pfSense, now it's handling some pretty intense traffic). You should find quite a few stability and CPU energy related settings.
The hardware looks good. Setting aside BIOS (if you want me to glance at their user documentation I'll have a look), and assuming you checked the component physical connections, my first point to check is what the case and air exposure/cooling are like? Is it physically safe and sensible to remove the case side/top, or even run a bare motherboard for a bit, to make sure it gets as much cool as possible? It shouldn't overheat on that spec but you never know. You can test the heat by touching the CPU heatsink or the heatsinks of motherboard components (check you're static-safe first of course), Somewhere between "warm" and "a bit too hot to touch" is fine, "could flash-fry a passing cow into carbon ash" isn't ;)
The next simple tests are to swap the disk cable and the port it's plugged into. I'd also test the NICs as best I can, because they can give errors too, try disabling the onboard NIC in BIOS and using the 4-way Intel only. It's good enough and means there is one less item that could cause an issue.
That said, my first guess is RAM (or something to do with memory) or disk (or disk connections). The screen photo says "swapper" - that's a fundamental process related to memory (possibly including virtual/paged memory although I'm not sure what the FreeBSD swapper covers exactly). So something to do with memory or swapping of memory miiiiight be implicated. In light of your description, I'd go there next.
How to do that with a core networking component? Some ideas, but ultimately there's no easy way other than "have spares" or "test on the device itself":
- Have you got anything else you can temporarily put pfsense on, to test your new board+RAM and board+disk?
- If not, disk testing might be less disruptive than RAM testing. At worst a new cable is £1/$1 on EBay, a temp HDD/SSD/USB is cheap too, so you can swap out your disk and cable, see what happens, and test yours separately on another machine.
- Have you got any other HDD (doesn't need to be an SSD) to run pfsense on so you can test the SSD properly on its own? (If not, pick up a £10 / $10 disk off EBay or something, and a spare cable, or turn off RRD/mass logging and use USB for a while. It only has to cope for some hours, up to a day, and pfSense is very fast to reinstall afterwards and restore the config).
- Have you got a spare SATA cable or can you swap the one it's using with another from some machine?
- Can you run memtest overnight or while you're out doing whatever you do?
If it helps, my ASRock was falling over the last week. Similar symptom INCLUDING swapper kernel panics twice, 2 days apart. I replaced the SATA cable, changed the SATA port "in case", and checked the SSD connections as my first steps (cooling/power both being good AFAIK) - no issues since. So it could well be similar. (But might not!)
-
I have seen this before caused by one shot timers.
I am not saying that is whats happening here, but you can disable one shot with this command.
'sysctl kern.eventtimer.periodic=1'
-
SMART results from pfsense Diagnostics > SMART Status (just shows how great this tool is, I think I hit the important ones, because my SSD doesn't have the "Life Left" indicator).
ada0
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0002 100 100 000 Old_age Always - 0
9 Power_On_Hours 0x0002 100 100 000 Old_age Always - 3486
12 Power_Cycle_Count 0x0002 100 100 000 Old_age Always - 390
165 Total_Write/Erase_Count 0x0002 100 100 000 Old_age Always - 16235
171 Program_Fail_Count 0x0002 100 100 000 Old_age Always - 0
172 Erase_Fail_Count 0x0002 100 100 000 Old_age Always - 0
173 Avg_Write/Erase_Count 0x0002 100 100 000 Old_age Always - 4
174 Unexpect_Power_Loss_Ct 0x0002 100 100 000 Old_age Always - 49
187 Reported_Uncorrect 0x0002 100 100 000 Old_age Always - 0
194 Temperature_Celsius 0x0022 056 044 000 Old_age Always - 44 (Min/Max 18/56)
230 Perc_Write/Erase_Count 0x0002 100 100 000 Old_age Always - 13
232 Perc_Avail_Resrvd_Space 0x0003 100 100 005 Pre-fail Always - 0
234 Perc_Write/Erase_Ct_BC 0x0002 100 100 000 Old_age Always - 16
241 Total_LBAs_Written 0x0002 100 100 000 Old_age Always - 635049153 (0.3 TB)
242 Total_LBAs_Read 0x0002 100 100 000 Old_age Always - 2835830910ada1
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0002 100 100 000 Old_age Always - 0
9 Power_On_Hours 0x0002 100 100 000 Old_age Always - 3488
12 Power_Cycle_Count 0x0002 100 100 000 Old_age Always - 382
165 Total_Write/Erase_Count 0x0002 100 100 000 Old_age Always - 59570
171 Program_Fail_Count 0x0002 100 100 000 Old_age Always - 0
172 Erase_Fail_Count 0x0002 100 100 000 Old_age Always - 0
173 Avg_Write/Erase_Count 0x0002 100 100 000 Old_age Always - 15
174 Unexpect_Power_Loss_Ct 0x0002 100 100 000 Old_age Always - 38
187 Reported_Uncorrect 0x0002 100 100 000 Old_age Always - 0
194 Temperature_Celsius 0x0022 061 039 000 Old_age Always - 39 (Min/Max 11/72)
230 Perc_Write/Erase_Count 0x0002 100 100 000 Old_age Always - 50
232 Perc_Avail_Resrvd_Space 0x0003 100 100 005 Pre-fail Always - 0
234 Perc_Write/Erase_Ct_BC 0x0002 100 100 000 Old_age Always - 173
241 Total_LBAs_Written 0x0002 100 100 000 Old_age Always - 3098971090 (1.4 TB)
242 Total_LBAs_Read 0x0002 100 100 000 Old_age Always - 4553881299So I am going out on a limb, that hopefully since the top-of-the-line consumer drives have been tested in the 700 TB write capability, and my drives don't have gobs of hours wracked up, I need to look to BIOS and ONE-SHOT timer points made by others, and possibly try replacing the $2 SATA cables next.
I still havent found a way to automatic ally record CPU % and Temp to syslogd, but I would like to.
-
pfSense shutdown during overnight on me again, woke up to find internet down and had to restore it quickly to login for a work meeting.
I have now uninstalled Avahi to see if it helps. Still haven't rebooted into BIOS Setup.
2017-08-01 00:12:48 User.Notice 192.168.33.1 Aug 1 01:14:30 check_reload_status: Linkup starting em0 2017-08-01 00:12:48 Kernel.Notice 192.168.33.1 Aug 1 01:14:30 kernel: em0: link state changed to DOWN 2017-08-01 00:12:49 Daemon.Error 192.168.33.1 Aug 1 01:14:31 php-fpm[96056]: /rc.linkup: DEVD Ethernet detached event for wan 2017-08-01 00:12:49 Daemon.Error 192.168.33.1 Aug 1 01:14:31 dhclient[6160]: connection closed 2017-08-01 00:12:49 Daemon.Critical 192.168.33.1 Aug 1 01:14:31 dhclient[6160]: exiting. 2017-08-01 00:12:50 User.Notice 192.168.33.1 Aug 1 01:14:32 check_reload_status: Reloading filter 2017-08-01 00:12:50 User.Warning 192.168.33.1 Aug 1 01:14:33 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:12:51 User.Warning 192.168.33.1 Aug 1 01:14:33 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:12:51 System2.Info 192.168.33.1 Aug 1 01:14:33 ntpd[32885]: Deleting interface #11 em0, 8.44.xxx.xx#123, interface stats: received=1229, sent=1295, dropped=0, active_time=579106 secs 2017-08-01 00:12:51 System2.Info 192.168.33.1 Aug 1 01:14:33 ntpd[32885]: 97.107.129.217 local addr 8.44.xxx.xx -> <null> 2017-08-01 00:12:51 User.Warning 192.168.33.1 Aug 1 01:14:34 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 .. .. 2017-08-01 00:13:02 User.Warning 192.168.33.1 Aug 1 01:14:45 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:02 User.Warning 192.168.33.1 Aug 1 01:14:45 dpinger: WAN_DHCP 8.44.xxx.xxx: Alarm latency 9973us stddev 7722us loss 22% 2017-08-01 00:13:02 User.Notice 192.168.33.1 Aug 1 01:14:45 check_reload_status: updating dyndns WAN_DHCP 2017-08-01 00:13:02 User.Notice 192.168.33.1 Aug 1 01:14:45 check_reload_status: Restarting ipsec tunnels 2017-08-01 00:13:02 User.Notice 192.168.33.1 Aug 1 01:14:45 check_reload_status: Restarting OpenVPN tunnels/interfaces 2017-08-01 00:13:02 User.Notice 192.168.33.1 Aug 1 01:14:45 check_reload_status: Reloading filter 2017-08-01 00:13:03 User.Warning 192.168.33.1 Aug 1 01:14:45 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:03 User.Warning 192.168.33.1 Aug 1 01:14:46 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:03 Daemon.Error 192.168.33.1 Aug 1 01:14:46 php-fpm[15495]: /rc.dyndns.update: Dynamic DNS () There was an error trying to determine the public IP for interface - wan (em0 ). 2017-08-01 00:13:03 Daemon.Error 192.168.33.1 Aug 1 01:14:46 php-fpm[41838]: /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use WAN_DHCP. 2017-08-01 00:13:04 User.Warning 192.168.33.1 Aug 1 01:14:46 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 .. .. .. 2017-08-01 00:13:22 User.Warning 192.168.33.1 Aug 1 01:15:05 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:23 User.Warning 192.168.33.1 Aug 1 01:15:05 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:23 User.Notice 192.168.33.1 Aug 1 01:15:05 check_reload_status: Linkup starting em0 2017-08-01 00:13:23 Kernel.Notice 192.168.33.1 Aug 1 01:15:05 kernel: em0: link state changed to UP 2017-08-01 00:13:23 User.Warning 192.168.33.1 Aug 1 01:15:06 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:24 User.Warning 192.168.33.1 Aug 1 01:15:06 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:24 Daemon.Error 192.168.33.1 Aug 1 01:15:06 php-fpm[41838]: /rc.linkup: DEVD Ethernet attached event for wan 2017-08-01 00:13:24 Daemon.Error 192.168.33.1 Aug 1 01:15:06 php-fpm[41838]: /rc.linkup: HOTPLUG: Configuring interface wan 2017-08-01 00:13:24 User.Notice 192.168.33.1 Aug 1 01:15:06 dhclient: PREINIT 2017-08-01 00:13:24 Daemon.Info 192.168.33.1 Aug 1 01:15:06 dhclient[44581]: DHCPREQUEST on em0 to 255.255.255.255 port 67 2017-08-01 00:13:24 Daemon.Info 192.168.33.1 Aug 1 01:15:07 dhclient[44581]: DHCPREQUEST on em0 to 255.255.255.255 port 67 2017-08-01 00:13:24 User.Warning 192.168.33.1 Aug 1 01:15:07 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:25 User.Warning 192.168.33.1 Aug 1 01:15:07 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:25 System4.Info 192.168.33.1 Aug 1 01:15:07 kernel: 2017-08-01 00:13:25 System4.Info 192.168.33.1 Aug 1 01:15:07 kernel: pfSense is now shutting down ... 2017-08-01 00:13:25 System4.Info 192.168.33.1 Aug 1 01:15:07 kernel: 2017-08-01 00:13:25 Daemon.Info 192.168.33.1 Aug 1 01:15:08 dhclient[44581]: DHCPREQUEST on em0 to 255.255.255.255 port 67 2017-08-01 00:13:25 User.Warning 192.168.33.1 Aug 1 01:15:08 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:26 User.Warning 192.168.33.1 Aug 1 01:15:08 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:26 User.Warning 192.168.33.1 Aug 1 01:15:09 dpinger: WAN_DHCP 8.44.xxx.xxx: sendto error: 65 2017-08-01 00:13:26 Syslog.Error 192.168.33.1 Aug 1 01:15:09 syslogd: exiting on signal 15</null> -
without a full crash dump it'll be impossible for the devs to give you some clues …
the onscreen dump is incomplete. Doesn't it ask to send the crashdump after reboot?
-
Ooop another important details, here's the version of pfSense I have running.
2.3.4-RELEASE (amd64)
built on Wed May 03 15:13:29 CDT 2017
FreeBSD 10.3-RELEASE-p19Fair enough, here's the hardware:
-
ASRock H110M-ITX LGA 1151 Intel H110 HDMI SATA 6Gb/s USB 3.0 Mini ITX
-
Intel Core i3-6100T 35W Processor
-
4GB (1 x 4GB) 288-Pin DDR4 SDRAM DDR4 2133 (PC4 17000)
-
SILVERSTONE SFX Series SST-ST30SF-V2 300W SFX 80 PLUS BRONZE Active PFC PSU
-
Used eBay IBM Intel I340-T4 Quad GB
-
3 - SanDisk 16GB Ultra Fit CZ43 USB 3.0 Flash Drive swapped these when the system stopped booting for used SanDisk 120GB SSD (I'm guessing these are 5+ years old)
You're answer why your system crashed the first time , is in your description.
2.3.4-RELEASE (amd64)
built on Wed May 03 15:13:29 CDT 2017
FreeBSD 10.3-RELEASE-p19This is the Full version, when you run a Full version on a USB stick, the stick WILL fail due the excessive read/write operations.
If you want to run pfSense from a USB stick, then you must use the Nano version.
The Nano version have limited read/write operations to extend the lifetime of your USB stick.As for now, try to disable devices in the BIOS like audio card.
Update your BIOS
Set the Sata controller to Legacy instead of AHCI
Reinstall pfSense
Also, the I340-T4 Quad Gigabit card can get very hot, the heatsink
of these Quad cards works best, when the card is used on his side, and not flat like in a desktop.
When you use these cards flat, they don't get natural airflow over the heatsink.Grtz
DeLorean -
-
@DeLorean full version on USB should work fine, just make sure to enable memory disk for /tmp and /var.. Anyhow its the only choice going forward with 2.4.. https://forum.pfsense.org/index.php?topic=121255.0
