NTPD losing contact with servers: "Unexpected origin timestamp"
-
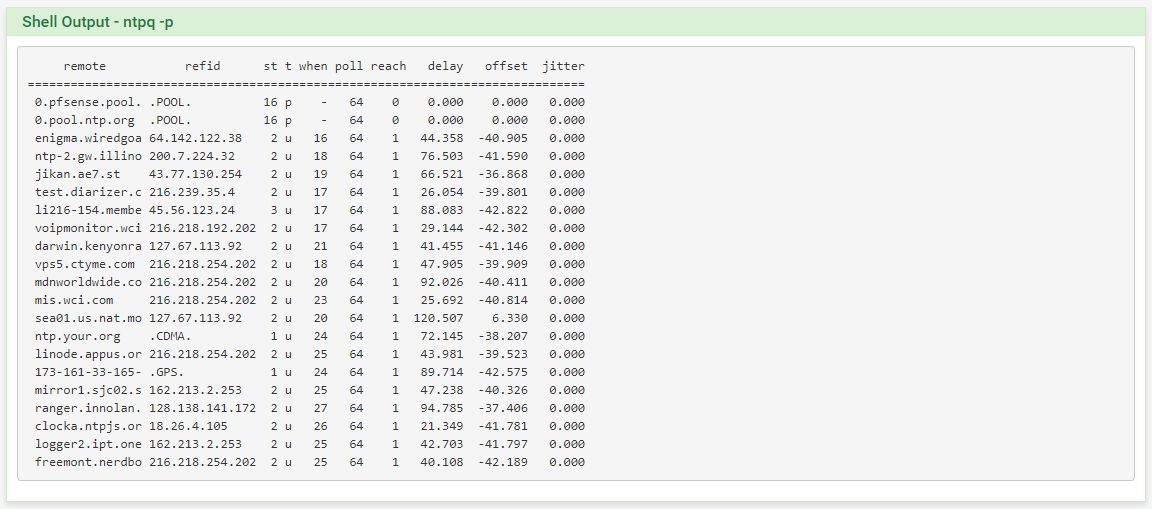
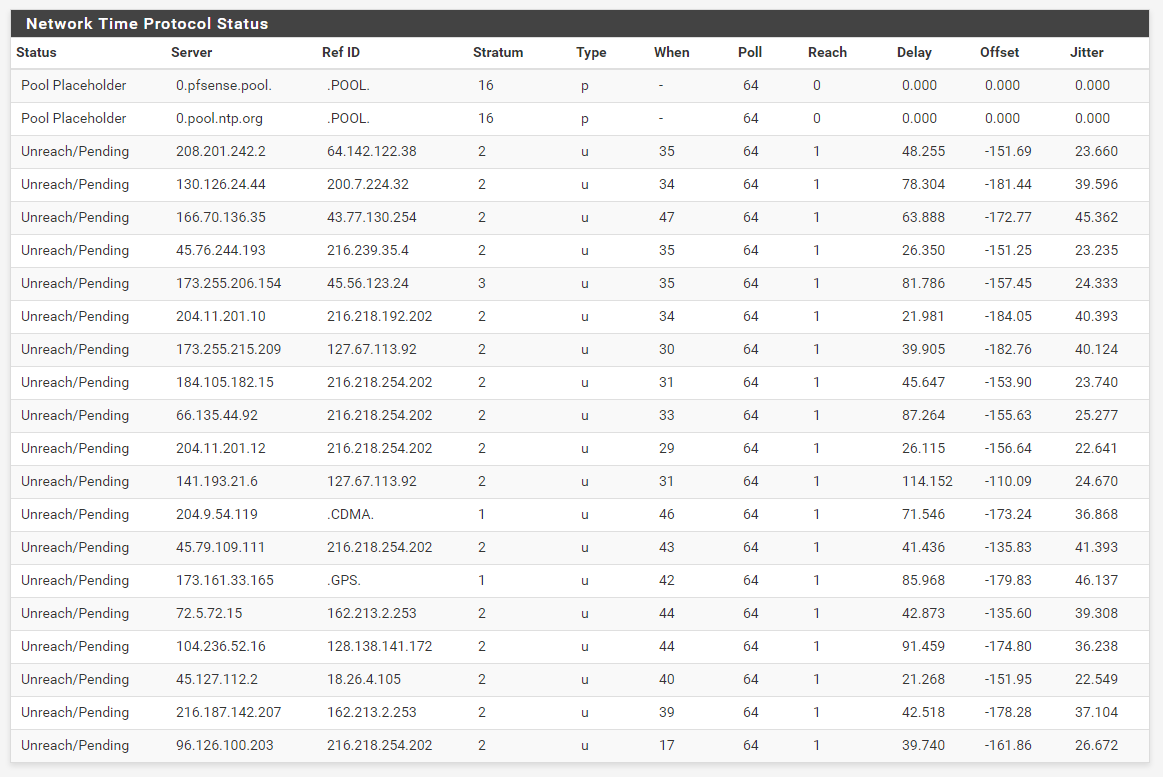
I've been struggling to get NTP to sync up and stay connected to its servers. It seems no matter how I configure it, it connects to the configured pools and servers, soon gets to reach "377" on everything, and then after a while loses contact with everything, going to status "Unreach/Pending". When I look in the log, I see several error messages like this:
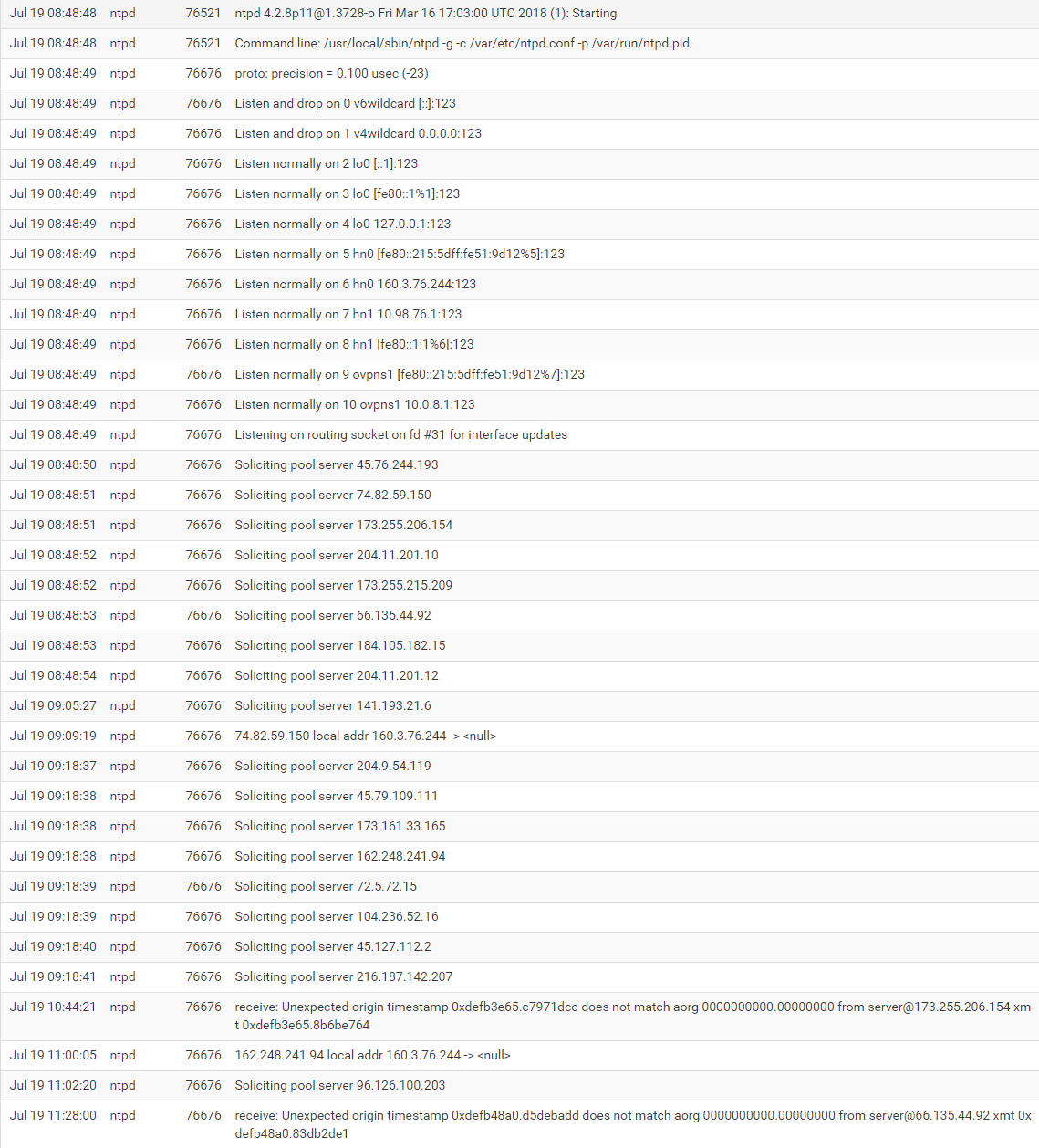
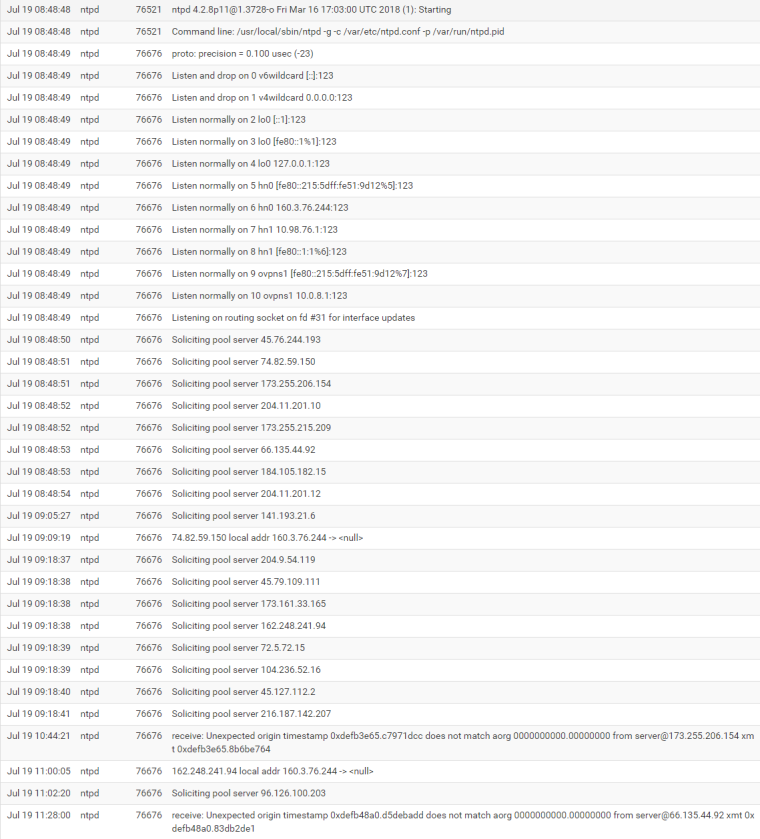
"Jul 19 10:44:21 ntpd 76676 receive: Unexpected origin timestamp 0xdefb3e65.c7971dcc does not match aorg 0000000000.00000000 from server@173.255.206.154 xmt 0xdefb3e65.8b6be764"If I restart ntpd, everything connects again, and some time later (an hour or two, maybe) it loses contact with everything. Sometimes, it seems to start over and connect to everything again. Sometimes it stays stuck in this state, with no contact.
I've seen suggestions that there was a bug in ntpd that caused this a while back, but as far as I can tell, pfSense has a new enough version of ntpd that this should be fixed.
Am I missing something obvious?
I'm running the latest stable 2.4.x version, in a Hyper-V virtual machine on Windows Server 2012, Datacenter Edition. It's configured with two virtual networks, tied to different VLANs, configured in Hyper-V. Everything else appears to be working, and performance is way better than I was getting previously with Untangle NGFW.
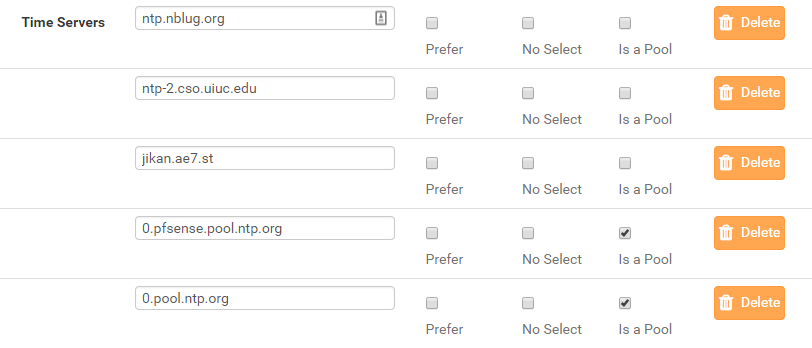
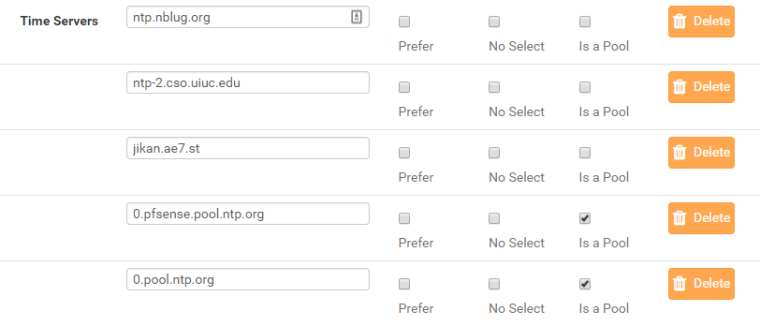
I've tried several combinations of different pools and individual hosts. Right now, this is what I have configured for testing:
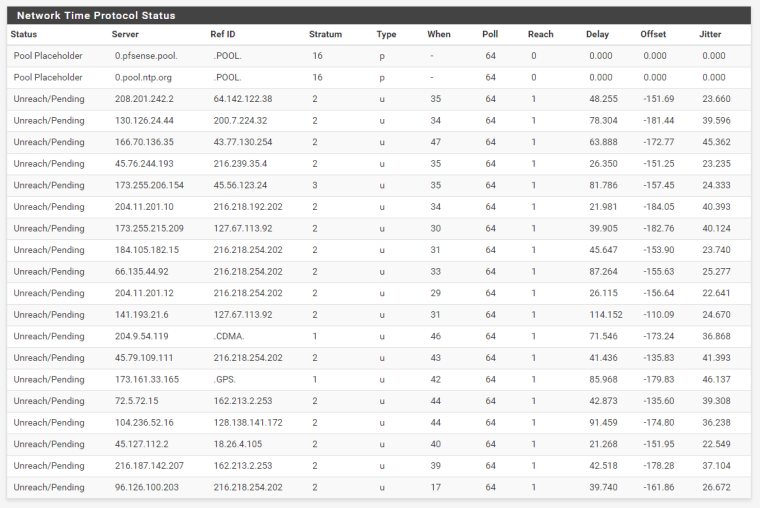
Now, after a couple of hours, everything has gone "Unreach/Pending":
Logs for this time period:
And, for good measure, the actual output of "ntpq -p":
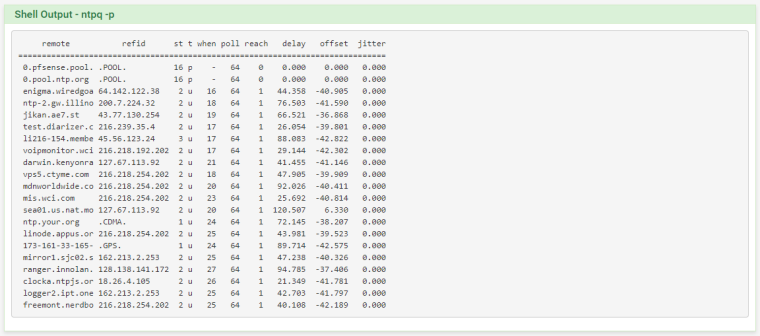
-
I'm still fighting this. I've tried several different server combinations, including a single server, and it doesn't seem to make much difference. The daemon connects and appears to be working. I even saw the poll get up to 512 last night on everything, but when I checked this morniing, reach was back to 1 and the offsets had increased from around 35ms to around 200ms.
It goes from this, which looks kind of okay:
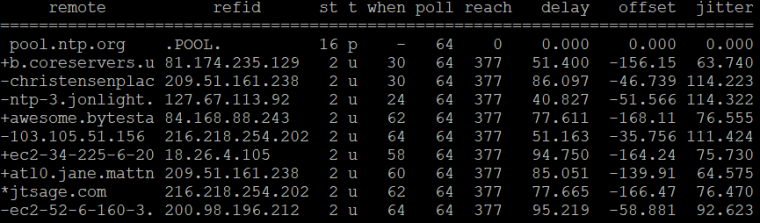
back to this, 30 minutes later:
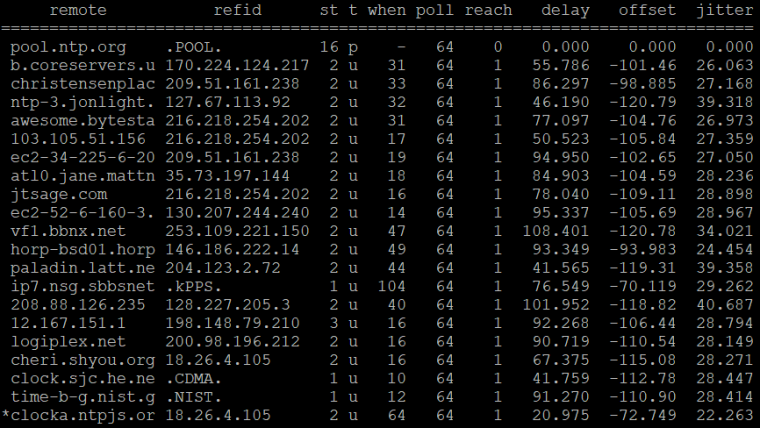
I have Hyper-V time synchronization turned off now, but it doesn't seem to make a ton of difference. I did check, and the system is using the Hyper-V-TSC timecounter. I don't know if this is the issue, or if I should try something else, or if I can even do that with pfSense.
-
I do see a recurring pattern where about half the servers have a small offset (~30ms) and the other half have a very different offset (~-200ms). That seems pretty odd.
I'm wondering if my underlying hardware clock (or the implementation in Hyper-V) is misbehaving.
-
I think I finally figured it out.
It appears that the clock was drifting enough that every half hour (or even more often) the NTP server was stepping the clock and then starting over, contacting the pool and connecting to new servers.
Jitter and offsets were also all over the map. See the jitters above of well over 100ms and a huge spread of offsets.
However another VM (Ubuntu LTS) on the same host with the same settings and the same clock source was working fine.
I ultimately discovered that the ntpd.drift file contained a value well over 600. I cleared the file and restarted ntpd, and everything is working fine now.
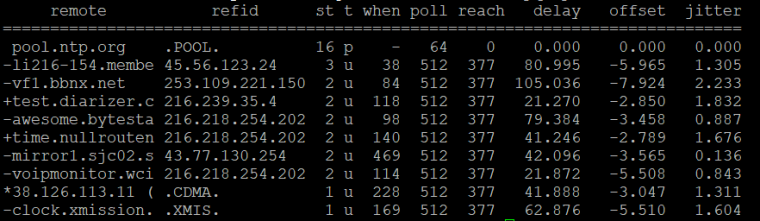
Offsets and jitter are now single digits, and the drift file shows about 25PPM, the same as the other VM.
My theory is that the drift file got screwed up because I was originally running both Hyper-V time synchronization and NTPD. (And the host clock was off by about 20 seconds.) Even after I turned off the Hyper-V time sync, the value in the drift file was causing the crazy issues I was seeing. The value was coming down very slowly (50PPM/day?). Emptying it and letting NTPD start over without the Hyper-V sync solved the problem.
-
Thanks for the great follow up to this - this for sure might help someone in the future!
I am a bit curious to why are you using 2 different pools that really point to the same place. Or did you remove the pfsense vanity/vendor based one and now your using just pool.ntp.org?
Whle your offset are way better now.. Your delay in the 105 its a bit high. What part of the world are you in? You should prob use a pool with clients in your same region. They have them based on country and or region. Or just call out specific ntp servers in your region.. The closer the better trying to min delay and jitter in their responses.
-
I was desperately trying all kinds of things: multiple pools, lists of specific servers, a single server, etc. Right now, I have it set to just pool.ntp.org. It's been running for about 12 hours, and it's looking pretty good:
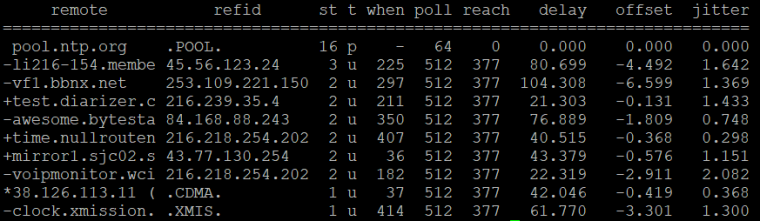
I'm in the US, so I just restarted it with us.pool.ntp.org, but the delays are about the same. About half of the servers are under 45ms. Compared to the crazy time swings I was seeing before, this makes me quite happy. NTP has now fallen into the "seems fine; time to worry about something else" category.
-
Thanks for coming back and reporting on what you found.. The next guy with such an odd issue may love you for it. Yeah running the vm sync to host and ntp on the vm at the same time can cause all kinds of weirdness to be sure.
-
@clough42 said in NTPD losing contact with servers: "Unexpected origin timestamp":
ntpd.drift
have any idea where the ntpd.drift file is located?
-
@ntranx
/var/db