CARP failover time using bridges
-
Hello.
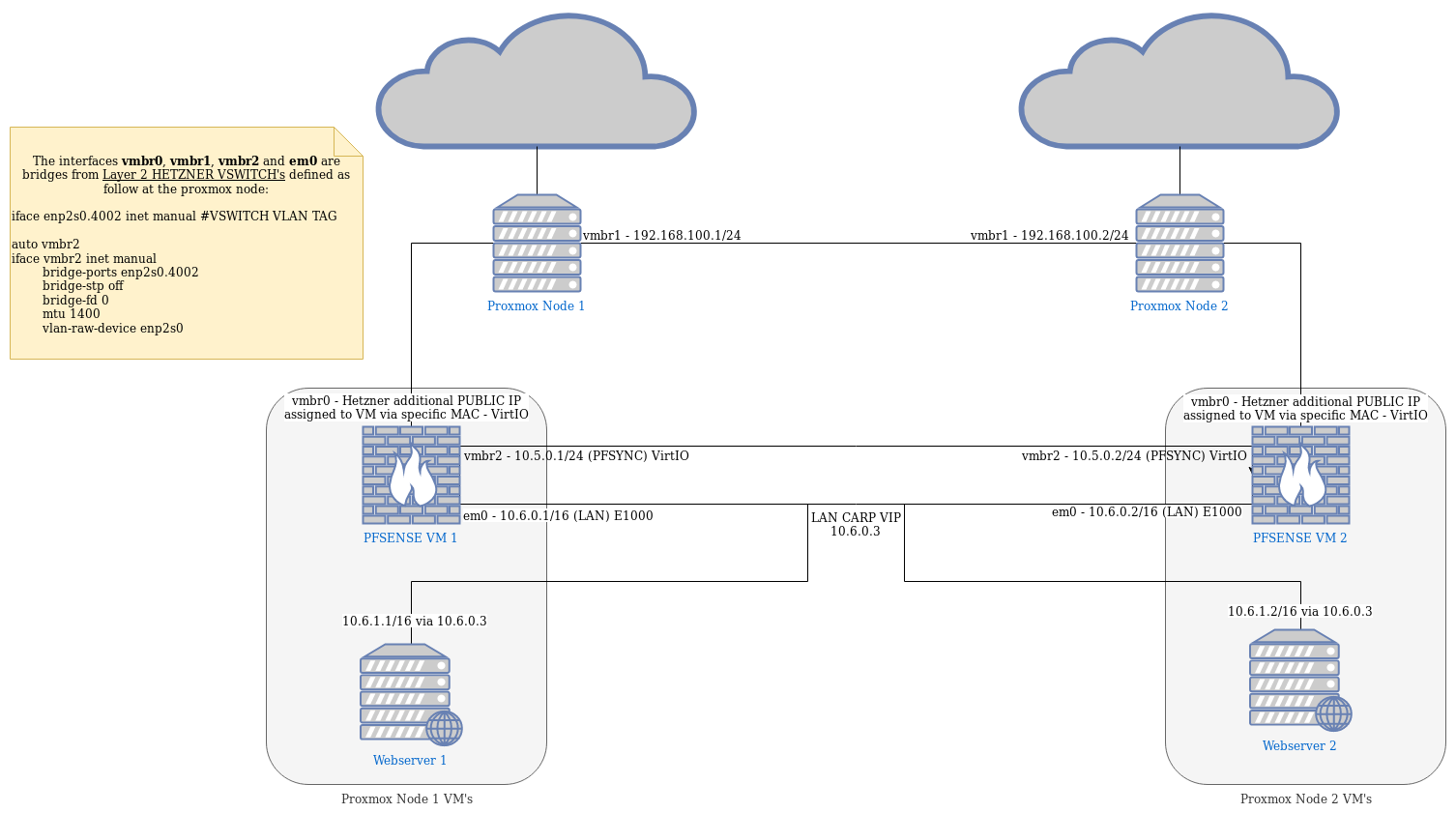
We are trying to make a new proxmox cluster design using pfsense VM's as node gateway/firewall for the entire VM LAN, the idea is making all of this HA.Unfortunately we are running into a problem related to the LAN CARP and the time it's taking to the vm's to find the route out using the backup if their master pfsense dies although the CARP failover detects the failture instantaneously and sets the backup as master.
Also, the vm's don't use the current master pfsense as gateway, they use the one they have in it's proxmox node.We have tried enabling stp but it doesn't work neither.
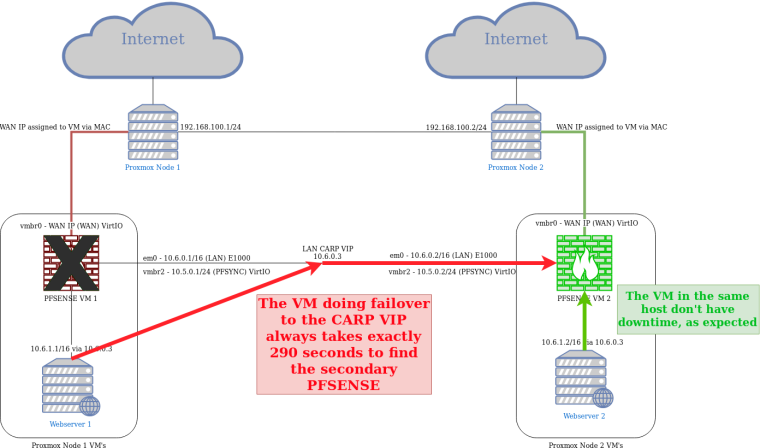
The time it takes a VM to resume the connection to the backup pfsense in other node is exactly 290 seconds, always the same.
After searching the entire forums the only related info i could find is this, but i couldn't find an answer to my specific problem:
https://www.netgate.com/docs/pfsense/highavailability/carp-cluster-with-bridge-troubleshooting.htmlThis is a diagram of the network in it's current state (all working except the previous problems):
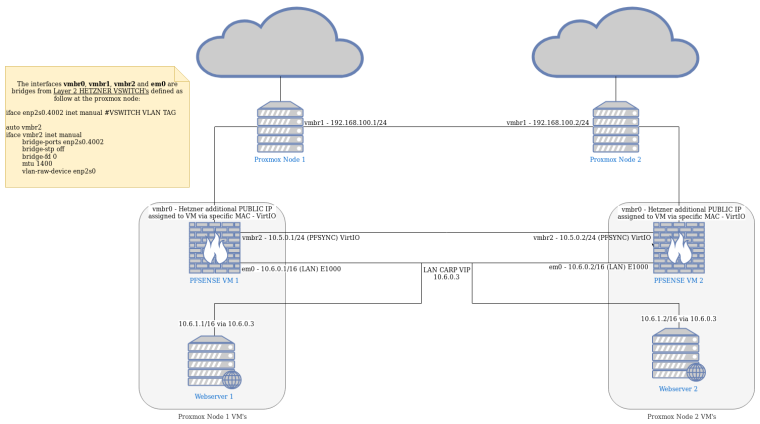
If you have a better cluster idea please let me know, thanks.
-
I'm still stuck with this, any help will be greatly appreciated

This is a diagram showing the problem:
-
If the secondary starts advertising the CARP immediately, and it takes 290 seconds for the VM on the other host to swing traffic over, the problem is in the Proxmox "switch" not on pfSense.
When it starts receiving CARP advertisements from the other VM, it should instantly move that MAC address to that switch "port."
It could also be something in the switching layer connecting the two host nodes.
The host "switch" losing the MAC address (Node 1 in this example) needs to know the MAC address has moved and drop it from its MAC address table immediately.
-
Well, after intensive testing, joining the two instances with a real switch and moving the two servers to the same datacenter everything was solved.
It also works through the Hetzner VSWITCH if the two servers are in the same datacenter.
Thank you for your assistance @Derelict.
-
@plokker We're looking to do the same thing. All our servers are in the same rack and connected via a second 10G NIC to a managed switch.
What IPs did you use on the CARP WAN side? pfsense recommend a minimum /29 for this.
Thanks.