Redirect all NTP traffic to internal IP
-
After many tries I wanted to restore a backup. Now I have a problem. See other thread. I have to fix them first...
-
Just wanted to chime in and confirm that I got this work as well after reading this discussion. All I did was add port forwarding (NAT Redirection) rules to forward NTP to the pfSense interface (for a given network segment) if the NTP request was bound for any other server (IP) that wasn't the pfSense interface (i.e. essentially like the DNS redirect instructions, but using NTP instead DNS and the interface IP instead of localhost). Did a quick test in a Linux VM and sure enough even though I specified an outside NTP server, traffic was directed to the internal NTP server running on the pfSense interface.
This is also neat way to help get all devices on the network perfectly in sync, i.e. especially mobile devices (phones, tablets, IoT) where it may not be easy (or even impossible) to separately configure the NTP (time) server.
-
I am not exactly sure why it doesn't work if you try and redirect to loopback for ntp.. Have not spent any time troubleshooting this.. Its just as easy to direct the port forward to the interface IP vs loopback, etc.
Guess we could dig into it a bit deeper, developers or admins might have insight to this little oddness. If you set ntp to listen on all interfaces, it clearly binds to loopback
root ntpd 44443 36 udp4 127.0.0.1:123 *:*So why would it be that dns works but ntp does not? Not sure to be honest.
But yeah if you just portforward to the IP of the interface on that network/vlan it works great.
-
Got it.
I selected the LAN interface only in ntp setting and it listens on localhost, too.
In NAT I redirected all ntp traffic to the localhost IP. That's it.There is one problem left that I cannot find the reason for.
We have two ntp servers. They are used internally and externally and are running pretty fine.
From pfsense I have a constant reach of 377 to external servers, but our internal servers make problems that we do not have from other hosts: They are very, very often unreachable for a long time. And later on they recover magically, but this may take hours.
On the ntp servers I see that they sent answer packets but these packets do never arrive at the pfsense machine. One of them is also part of ntp pool and makes no problems. Both are havily used inside wothout problems. On the pfsense machine it looks like this:
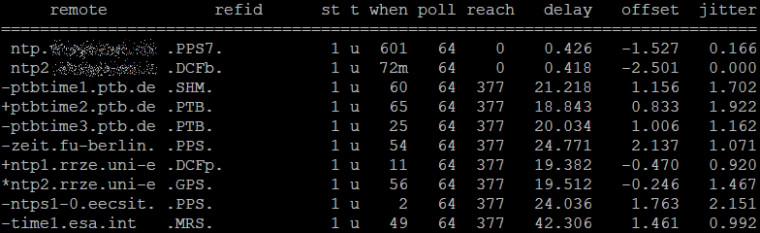
Did someone else see this before? It is seen from pfsense only.Thanks!
Now it looks like this:
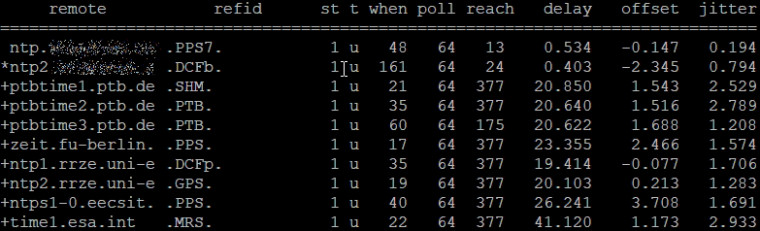
-
Nope never seen that.. So you sniff on pfsense and see it sending query to your internal ntp, and you see the return but reach doesn't go up?
Look at the NTP packet you get back, if its not valid for some reason ntp would not count it as a reach..
-
@johnpoz exactly like this.
a few minutes later...
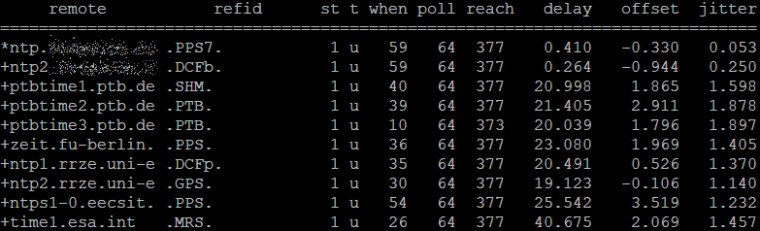
funny, if it were not my job to correct this ;-) -
they it only takes like 8 good queries to reach 377, if your polling every 64s out of the gate than yeah only a few minutes.
Maybe your ntp server looses its sync and its answers are not valid?
-
All switches, machines, devices whatever use the combination of these two local ntp servers. And in the meantime while I see these broken reach bits, the other machines/devices talk to the ntp servers without any problems. Even ntppool goes up again. I believe there is something (deep) inside pfsense.
Until yesterday I had version 2.4.3 running, do you know what ntpd version was used with 2.4.3? Because I cannot remember having seen this before with 2.4.3 and we already use this pfsense ntp server setup for about 2 years. The only difference now is the new pfsense version and NAT, and when I disable NAT things don't get better. -
In a first step I let run ntpdate for about 12h every 5 secs from pfsense to the ntp server. I recorded a tcpdump on both ends and I had not one missed ntp packet. Meanwhile ntpd had the usual problems. Really strange. In the logs of doing the ntpq -p against the pfsense machine (every 7 seconds) I saw that not only my local servers seen from pfsense do experience timeouts, the external servers also have timeouts but less often. Strange...
-
@demux said in Redirect all NTP traffic to internal IP:
I had not one missed ntp packet.
But what did the data say, you can't just look for a reply but what was in the reply.
And what do you mean by nat - there should be no nat to anything local
-
@johnpoz I meant NAT / port forward.
I did not dig into the packets or assemble them. This is why I used ntpdate and ntpq -p.
I assume ntpdate and ntpq will tell me if there is something unusual inside the packets.
If ntpdate reports increasing times by 5 secs if called every 5 secs, then I assume it's ok.
If I see packets travelling from left to right and back and a resuling answer by ntpdate, I assume it is ok. And I had run ntpq -p against pfsense to see what the pfsense ntp server currently does.
So I see an uninterrupted data flow and data that makes sense to ntpdate (and to me).
Do you know what version of ntpd was included in version 2.4.3? -
Again what would port forwarding have to do with pfsense talking to your local NTP server? There is no nat from pfsense IP to some device on one of pfsense networks.
No I do not... Look in the release notes.. 2.4.4p2 is current
ntpq 4.2.8p12@1.3728-o Wed Sep 5 02:13:06 UTC 2018 (1)this version came out well after 2.4.3 so yeah it was a slightly older version.
-
I did a packet trace. What I see is - I believe - strange:
11:22:12.477255 IP (tos 0xb8, ttl 64, id 11111, offset 0, flags [none], proto UDP (17), length 76)
10.200.100.pfSense.123 > 10.200.100.ntp_server.123: [udp sum ok] NTPv4, length 48
Client, Leap indicator: (0), Stratum 2 (secondary reference), poll 5 (32s), precision -22
Root Delay: 0.025558, Root dispersion: 0.500915, Reference-ID: 130.149.17.21
Reference Timestamp: 3759301270.497451600 (2019/02/16 11:21:10)
Originator Timestamp: 3759301236.436497210 (2019/02/16 11:20:36)
Receive Timestamp: 3759301236.437431054 (2019/02/16 11:20:36)
Transmit Timestamp: 3759301332.477197054 (2019/02/16 11:22:12)
Originator - Receive Timestamp: +0.000933844
Originator - Transmit Timestamp: +96.040699843
11:22:12.477621 IP (tos 0xb8, ttl 64, id 20383, offset 0, flags [DF], proto UDP (17), length 76)
10.200.100.ntp_server.123 > 10.200.100.pfSense.123: [udp sum ok] NTPv4, length 48
Server, Leap indicator: (0), Stratum 1 (primary reference), poll 5 (32s), precision -23
Root Delay: 0.000000, Root dispersion: 0.550033, Reference-ID: DCFb
Reference Timestamp: 3759301329.370467552 (2019/02/16 11:22:09)
Originator Timestamp: 3759301332.477197054 (2019/02/16 11:22:12)
Receive Timestamp: 3759301332.475587226 (2019/02/16 11:22:12)
Transmit Timestamp: 3759301332.475714633 (2019/02/16 11:22:12)
Originator - Receive Timestamp: -0.001609827
Originator - Transmit Timestamp: -0.001482420As far as I understood, the first packet leaving the client should have (nearly) Originator=Receive=Transmit. The server uses sets Originator=Originator client, Receive=receive time at the server, Transmit=transmit time at the server.
What does the client (pfSense ntp server) do between Receive and Transmit times?
This is whay I see the correct and fast flow of packets; it seems to hang around in pfSense's ntp server before being sent out.
??? -
Thanks fellas, i got this to work with the above info.
Had to forward to the interface, instead of 127.0.0.1.Works if set to time.nist.gov option in windows 10, but not time.windows.com
Any ideas why -
What do you mean doesn't work is set to time.windows? If your doing redirection shouldn't matter what the client asks for.. As long as it would resolve.
-
@johnpoz talking through my bottom. it synchronized. maybe i tried to quick after the gov one...anyways. all good now
-
My crux was that part: NAT Reflection: Disable
Before I had it enabled and had a auto or 2nd LAN rule that was not beneficial for NTP redirect.
With NAT Reflection: Disable the answer time is below 5ms, and I guess the answer is coming from pfsense.
-
@febu This suggestion is only relevant if, under
System / Advanced / Firewall & NAT, the system setting "NAT Reflection mode for port forwards" is set to anything other than "disabled" (in which case the individual "NAT reflection" setting you've referred to within a Port Forward redirect rule may override the system setting).Alternatively you might reconsider the system setting you've configured under
System / Advanced / Firewall & NAT / NAT Refelction mode for port forwards. -
@tinfoilmatt Yes I was not aware of it. Thanks for the explanation
