dpinger high loss values ?
-
Hello,
This seems to be related to https://forum.netgate.com/topic/94852/help-troubleshooting-random-crazy-high-pings
I never looked at gateway logs and don't have any visible issues, but wonder about these entries in the gateway log:
Mar 13 00:47:25 dpinger WAN_DHCP 8.8.8.8: Clear latency 3127us stddev 666us loss 6% Mar 13 00:43:26 dpinger WAN_DHCP 8.8.8.8: Alarm latency 3241us stddev 104us loss 21% Mar 13 00:25:57 dpinger WAN_DHCP 8.8.8.8: Clear latency 3105us stddev 129us loss 5% Mar 13 00:24:45 dpinger WAN_DHCP 8.8.8.8: Alarm latency 3276us stddev 195us loss 22% Feb 27 01:59:01 dpinger WAN_DHCP 8.8.8.8: Clear latency 17716us stddev 11764us loss 15% Feb 27 01:56:56 dpinger WAN_DHCP 8.8.8.8: Alarm latency 27141us stddev 656us loss 21% Feb 27 01:56:32 dpinger WAN_DHCP 8.8.8.8: Clear latency 27071us stddev 566us loss 20% Feb 27 01:55:16 dpinger WAN_DHCP 8.8.8.8: Alarm latency 108954us stddev 40575us loss 21%Is it good, bad, what to do about those ?
I am on 1GB fiber up-link
Thx
-
BAD, it could be your ISP dropping ICMP packets when their network is busy.
mac-pro:~ andy$ ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: icmp_seq=0 ttl=122 time=10.242 ms
64 bytes from 8.8.8.8: icmp_seq=1 ttl=122 time=9.932 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=122 time=10.184 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=122 time=9.895 ms
64 bytes from 8.8.8.8: icmp_seq=4 ttl=122 time=10.160 ms
64 bytes from 8.8.8.8: icmp_seq=5 ttl=122 time=10.231 ms
64 bytes from 8.8.8.8: icmp_seq=6 ttl=122 time=10.154 ms
^C
--- 8.8.8.8 ping statistics ---
7 packets transmitted, 7 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 9.895/10.114/10.242/0.131 ms
mac-pro:~ andy$What do you get when you ping something a bit nearer your ISP.
-
@nogbadthebad said in dpinger high loss values ?:
ping 8.8.8.8
I see no losses running on the router:
ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8): 56 data bytes 64 bytes from 8.8.8.8: icmp_seq=0 ttl=118 time=3.504 ms 64 bytes from 8.8.8.8: icmp_seq=1 ttl=118 time=3.607 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=118 time=3.448 ms 64 bytes from 8.8.8.8: icmp_seq=3 ttl=118 time=3.469 ms 64 bytes from 8.8.8.8: icmp_seq=4 ttl=118 time=3.478 ms 64 bytes from 8.8.8.8: icmp_seq=5 ttl=118 time=3.320 ms 64 bytes from 8.8.8.8: icmp_seq=6 ttl=118 time=3.340 ms 64 bytes from 8.8.8.8: icmp_seq=7 ttl=118 time=3.462 ms 64 bytes from 8.8.8.8: icmp_seq=8 ttl=118 time=3.436 ms 64 bytes from 8.8.8.8: icmp_seq=9 ttl=118 time=3.197 ms 64 bytes from 8.8.8.8: icmp_seq=10 ttl=118 time=3.314 ms ^C --- 8.8.8.8 ping statistics --- 11 packets transmitted, 11 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 3.197/3.416/3.607/0.108 ms -
Does not seem like I am seeing losses all the time, maybe just some ISP issues but not ongoing ?
-
Seems like an ISP that sells 'n' times a "1GB fiber up-link" but they haven't a n x "1GB fiber up-link" from their neighbourhood router upstream, to the net. Thy're overselling (they all do).
Result : upstream gets full (everybody wants it's "1GB fiber up-link", espically at 08h00 PM, low priority protocols get dropped like ICMP.Drop in here to test more http://www.dslreports.com/speedtest
edit : if needed, optimize your connection.
-
http://www.dslreports.com/speedtest/47343618
-
@chudak said in dpinger high loss values ?:
http://www.dslreports.com/speedtest/47343618
Good !
Right now, your ISP is actually quiet good. -
I'm experiencing similar issues. It is even worse ... from time to time the interface is not even recovering. See my description below posted to support:
In two locations I have installed the SG3100. In one locations, there is a gateway group with two WAN connections. The other location has only one WAN connection.
On these two devices I discovered some strange behaviour with the gateway monitor which is pointing to Google DNS servers (8.8.8.8) or Quad9 (9.9.9.9). These are both multicast IP's.
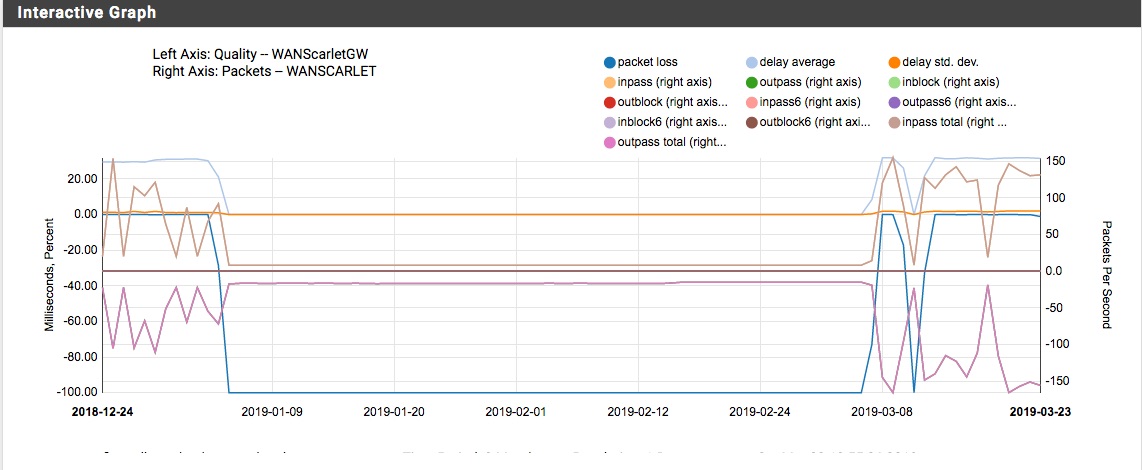
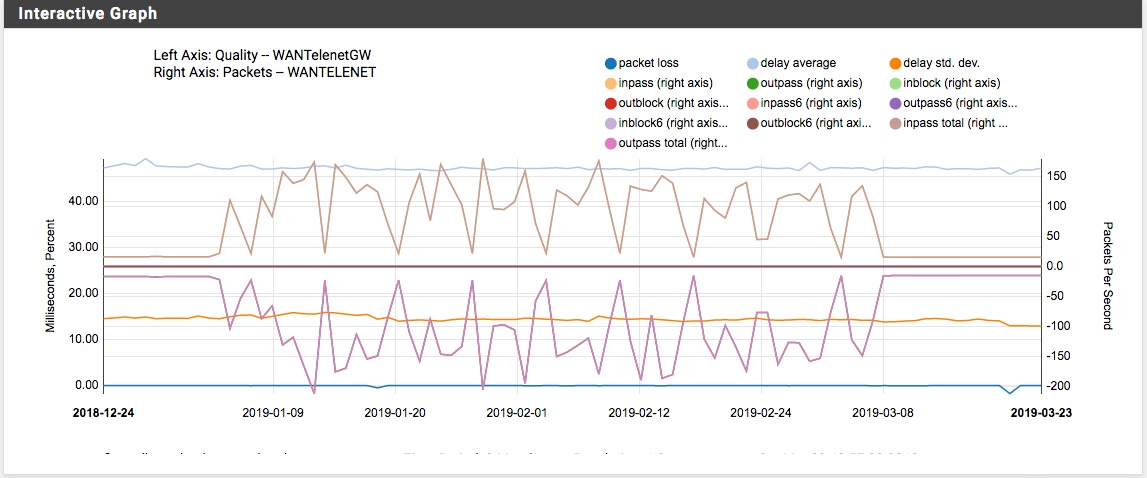
Case A/ 2 WAN connections with primary and failover WAN
At a given moment the primary WAN failed due to a package loss towards 8.8.8.8. The secondary takes over as planned and no network interruption seen, but at no moment (in a period of several weeks) the primary became online again (although of course the 8.8.8.8 was perfectly pingable from any device in the network). The only way I could re-enable the interface was going into the configuration and force it online. (See 2 attach starting with 2WAN_ => you see gateway with 100% loss, traffic dropping to 0 and other interface taking over.)
Case B/ 1 WAN Connection
At a given moment the gateway monitoring indicated major packet loss and the gateway was "offline". However, I didn't notice this one while working on the network, so even if it was "offline" it kept working, which I found strange. Again I tested the ping from a device on the network which worked perfectly. I did the ping test using diagnosis tab in PfSense GUI, and to my surprise it indicated 100% packet loss ... other pings worked well. Also here, I had to go to the config to force the interface online. This resolved the ping issue as well using the diagnosis ping option. However, as stated, even with the gateway "offline" I could still work.
(Attach: 1WAN_GatewayDown_Keptworking => You see the gateway goes down but there is still traffic). But key thing here as well ... why didn't the ping recover ?!Case A/
-
Primary interface goes down due to 100% package loss for ping
-
Secondary takes over for several weeks (till manual intervention)
Case B/
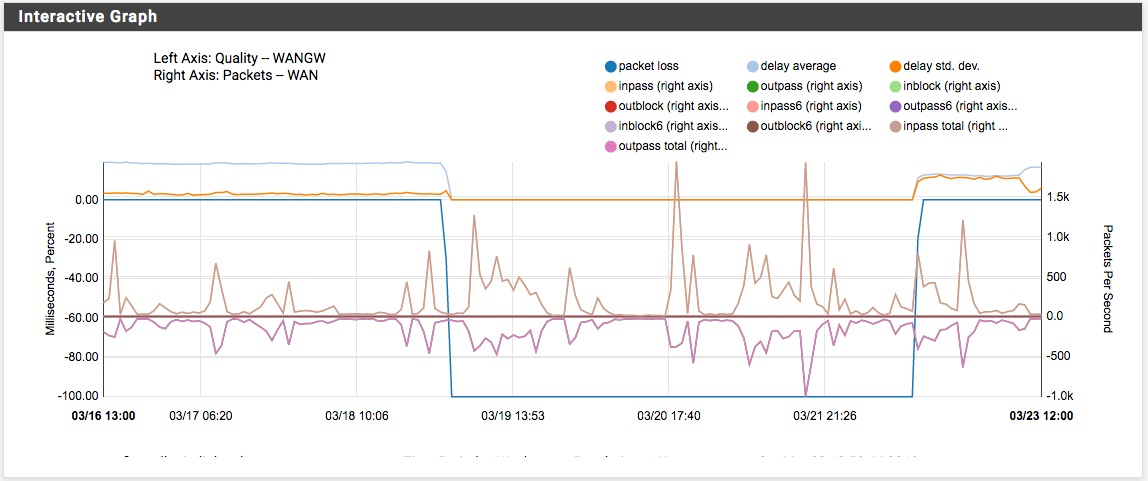
-
-
Similar happened to me. I'm using SG-3100, sometimes GW shows offline but still able to work, on other occassion completly dropped. I've rulled out ISP (checked my mode, connected directly to it and no problems).
"Also here, I had to go to the config to force the interface online. This resolved the ping issue as well using the diagnosis ping option. However, as stated, even with the gateway "offline" I could still work."
Can you elaborate on what you did? I'm new to pfSense and trying to learn :)I've checked my system log, it looks like ppp is tripping?
Jul 3 03:00:03 pfSense rc.gateway_alarm[37291]: >>> Gateway alarm: WAN_PPPOE (Addr:8.8.8.8 Alarm:1 RTT:16.206ms RTTsd:.350ms Loss:22%) Jul 3 03:00:03 pfSense check_reload_status: updating dyndns WAN_PPPOE Jul 3 03:00:03 pfSense check_reload_status: Restarting ipsec tunnels Jul 3 03:00:03 pfSense check_reload_status: Restarting OpenVPN tunnels/interfaces Jul 3 03:00:03 pfSense check_reload_status: Reloading filter Jul 3 03:00:04 pfSense php-fpm[85706]: /rc.openvpn: Gateway, none 'available' for inet, use the first one configured. 'WAN_PPPOE' Jul 3 03:00:04 pfSense php-fpm[85706]: /rc.openvpn: Gateway, none 'available' for inet6, use the first one configured. '' Jul 3 03:00:04 pfSense php-fpm[85706]: /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use WAN_PPPOE. Jul 3 03:00:06 pfSense php-fpm[60912]: /rc.dyndns.update: phpDynDNS (meaple.dyndns.org): No change in my IP address and/or 25 days has not passed. Not updating dynamic DNS entry. Jul 3 03:04:18 pfSense kernel: arp: 192.168.1.221 moved from b8:27:eb:xx:xx:xx to b8:27:eb:yy:yy:yy on mvneta1 Jul 3 03:10:58 pfSense php-fpm[43606]: /index.php: Session timed out for user 'admin' from: 192.168.1.25 (Local Database) Jul 3 03:11:07 pfSense php-fpm[43606]: /index.php: Successful login for user 'admin' from: 192.168.1.25 (Local Database) Jul 3 03:11:20 pfSense php-fpm[96938]: /index.php: Successful login for user 'admin' from: 192.168.1.25 (Local Database) Jul 3 03:11:31 pfSense php-fpm[51982]: /index.php: Successful login for user 'admin' from: 192.168.1.25 (Local Database) Jul 3 03:18:59 pfSense check_reload_status: Linkup starting mvneta2 Jul 3 03:18:59 pfSense kernel: mvneta2: link state changed to DOWN Jul 3 03:19:00 pfSense check_reload_status: Reloading filter Jul 3 03:19:08 pfSense check_reload_status: Linkup starting mvneta2 Jul 3 03:19:08 pfSense kernel: mvneta2: link state changed to UP Jul 3 03:19:09 pfSense ppp: Multi-link PPP daemon for FreeBSD Jul 3 03:19:09 pfSense ppp: Jul 3 03:19:09 pfSense ppp: process 4402 started, version 5.8 (root@pfSense_factory-v2_4_4_armv6-pfSense_factory-v2_4_4-job-10 13:18 16-Nov-2018) Jul 3 03:19:09 pfSense ppp: caught fatal signal TERM Jul 3 03:19:09 pfSense ppp: waiting for process 10494 to die... Jul 3 03:19:09 pfSense ppp: [wan] IFACE: Close event Jul 3 03:19:09 pfSense ppp: [wan] IPCP: Close event Jul 3 03:19:09 pfSense ppp: [wan] IPCP: state change Opened --> Closing Jul 3 03:19:09 pfSense ppp: [wan] IPCP: SendTerminateReq #4 Jul 3 03:19:09 pfSense ppp: [wan] IPCP: LayerDown Jul 3 03:19:09 pfSense php-fpm[60912]: /rc.linkup: calling interface_dhcpv6_configure. Jul 3 03:19:09 pfSense php-fpm[60912]: /rc.linkup: Accept router advertisements on interface mvneta2 Jul 3 03:19:09 pfSense php-fpm[60912]: /rc.linkup: Starting rtsold process Jul 3 03:19:09 pfSense check_reload_status: Rewriting resolv.conf Jul 3 03:19:09 pfSense ppp: [wan] IFACE: Removing IPv4 address from pppoe0 failed(IGNORING for now. This should be only for PPPoE friendly!): Can't assign requested address Jul 3 03:19:09 pfSense ppp: [wan] IPV6CP: Close event Jul 3 03:19:09 pfSense ppp: [wan] IPV6CP: state change Opened --> Closing Jul 3 03:19:09 pfSense ppp: [wan] IPV6CP: SendTerminateReq #2 Jul 3 03:19:09 pfSense ppp: [wan] IPV6CP: LayerDown Jul 3 03:19:10 pfSense ppp: waiting for process 10494 to die... Jul 3 03:19:10 pfSense check_reload_status: Rewriting resolv.conf Jul 3 03:19:10 pfSense ppp: [wan] IFACE: Down event Jul 3 03:19:10 pfSense ppp: [wan] IFACE: Rename interface pppoe0 to pppoe0 Jul 3 03:19:11 pfSense ppp: waiting for process 10494 to die... -
I have changed my monitor ip to 8.8.8.8 and so far don’t see any losses in 2-3 days.
-
@chudak hi, did this workout for you?
-
I don't know :(
Frankly, I did not pay much attention
This is what I see in the logs now:
Oct 27 19:46:32 dpinger 92730 send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% alarm_hold 10000ms dest_addr 135.180.64.1 bind_addr 135.180.66.6 identifier "WAN_DHCP " Oct 27 19:46:32 dpinger 97106 exiting on signal 15