Packet loss and high ping
-
Hi there,
I'm at a loss here, been reading alot about pfsense but cannot figure out the root of my issue.
The problem is, I think, my TOR exit relay. Whenever it is running, at random intervals the State table size increases (from 1% to 2-3%), so nothing drastic. However, when this happens my internet connection becomes extremely slow. The GW monitor will show pings of 100ms+ with an RTTsd of 200ms+. Also, the packet loss goes up, sometimes to only 1-2% but othertimes it's so high the GW monitor considers the connection down. This usually takes a minute or two and then the connection normalizes again.
I don't know what to do. I have two Intel(R) PRO/1000 NIC's, one for wan and one for lan. The CPU is an i5-4670k with 8GB of ram (2x4GB). My connection is nowhere near saturated, I have an 300/40 line, and tor is limited to using 20/20, but at the time the problems start tor is using way below that, it's just the connection count shooting up in the states table.
The reason I suspect the tor relay, is that the problems don't happen when I've got it turned off.
Now the whole reason I built this PFsense box, is that I was having similar issues with my old edgerouter. I figured it couldn't handle the TOR connections, so I went with something over the top powerful.
Now, is there a possibility that the issue is with my ISP? Does the ISP modem handle all the connections, or does it just see one up/down connection from my PFsense router? And any ideas how to troubleshoot this issue?
Other relevant information, I have my own /29 ipv4 block, so I have one ipv4 address assigned to WAN, and the rest are defined as Virtual IP's in pfsense.
Any help is greatly appreciated.
Edit: Here's a screencap of it happening.
-
What is the speed of your WAN link? Have you put any limits on your exit node's bandwidth? Could it be that when your Tor node is very busy, its sucked up all your outgoing bandwidth?
-
@KOM My WAN link is 300/40, and it's nowhere near saturated at the time the issue presents. The only thing I see happening is the state table size increasing, and the GW monitor ping increasing. Also my internet is crawling to a stop. I did have traffic shaping in place, with the TOR relay on low prio, however I removed this for trouble shooting reasons. This did not make a difference.
-
It's not the state table. It's not pfSense. Could be the ISP or some upstream device choking.
If you have gateway monitoring on WAN (the default setting), the system is automatically keeping track of two pings per second in Status > Monitoring.
From there select settings, change the left axis to Quality / WANGW (or the local equivalent).A good place to start with Options: 8 hours, Resolution: 1 minute.
Another place to check is in Status > System Logs, Gateways. Any events there with "Alarm" in them are times when the ping monitor had excessive loss or latency.
A failure will look something like this: Jan 7 15:05:31 dpinger WANGW 8.8.8.8: Alarm latency 0us stddev 0us loss 100%
Lines like this are just the dpinger process starting or reloading and are normal:
dpinger send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 0 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% dest_addr 8.8.4.4 bind_addr 198.51.0.16 identifier "DSLGW"
Sometimes it is beneficial to change your monitoring address to something further out. In that example you can see that I am monitoring a google DNS server there. In general, monitoring the ISP gateway is fine if it reliably responds to pings. Changes to the monitor IP address can be made in System > Routing and editing the appropriate gateway.
-
@Derelict I do get these errors:
GW_WAN 94.x.x.x: Alarm latency 413201us stddev 500917us loss 21%
GW_WAN 94.x.x.x: Alarm latency 506484us stddev 528399us loss 29%I know the GW pinger is not definite in showing issues, however I experience issues when this is happening in the form of web pages not loading and timing out.
And by upstream device chocking, do you mean chocking on the amount of connections?
I pay a lot of money to my ISP to have a 'business' grade connection, with an SLA and everything. If it's on their side, I need something to prove it. Last time I called them they said to test it without the router directly on the modem, and add devices one by one to see when the issues start. That's how I found out about the TOR relay. However, I would like to keep the relay running. My ISP further said that everything on their end is good and that it must be my network/router/whatever.
I will make the changes you suggested and monitor it. For now, here is a screencap of when it's happening if it's any help:
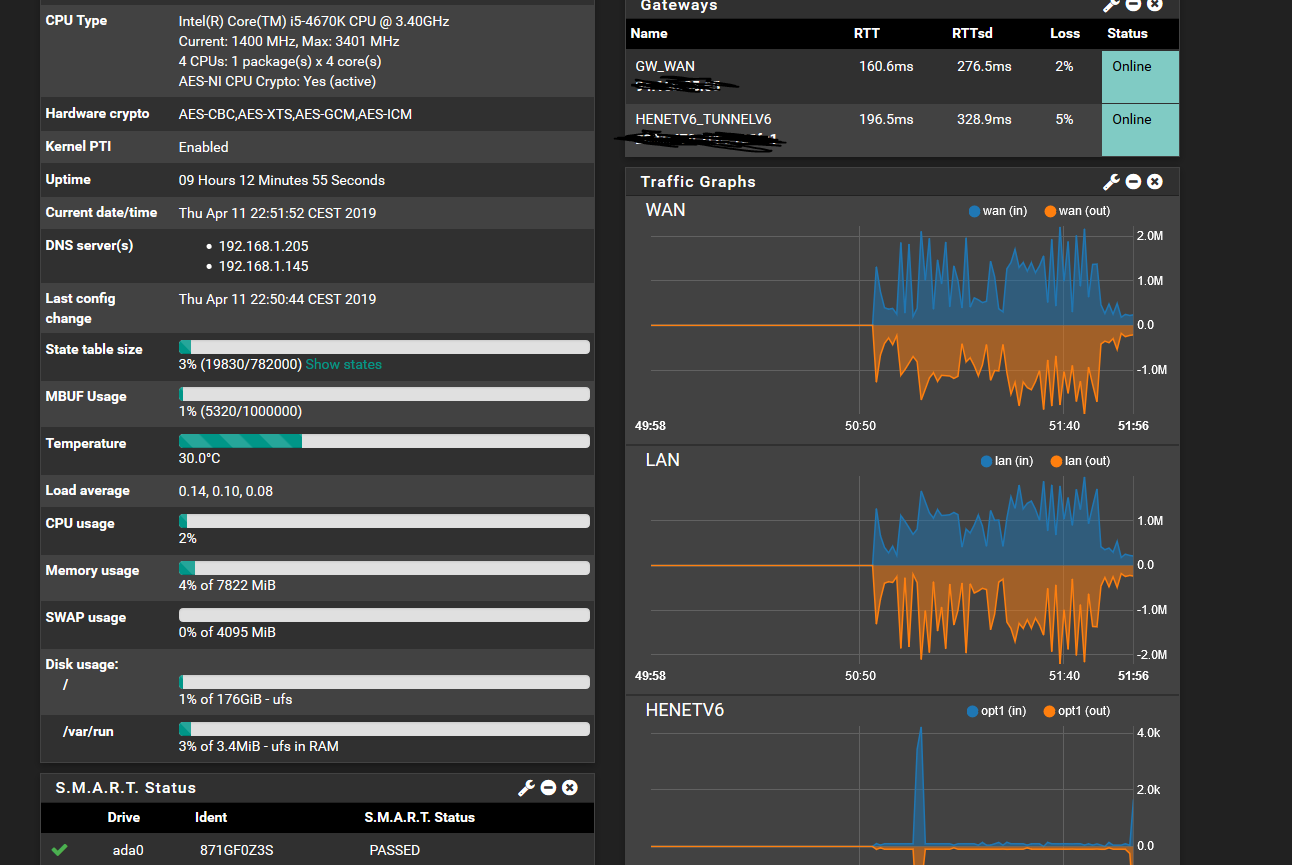
And a screenshot of the 8hour/1minute quality graph:
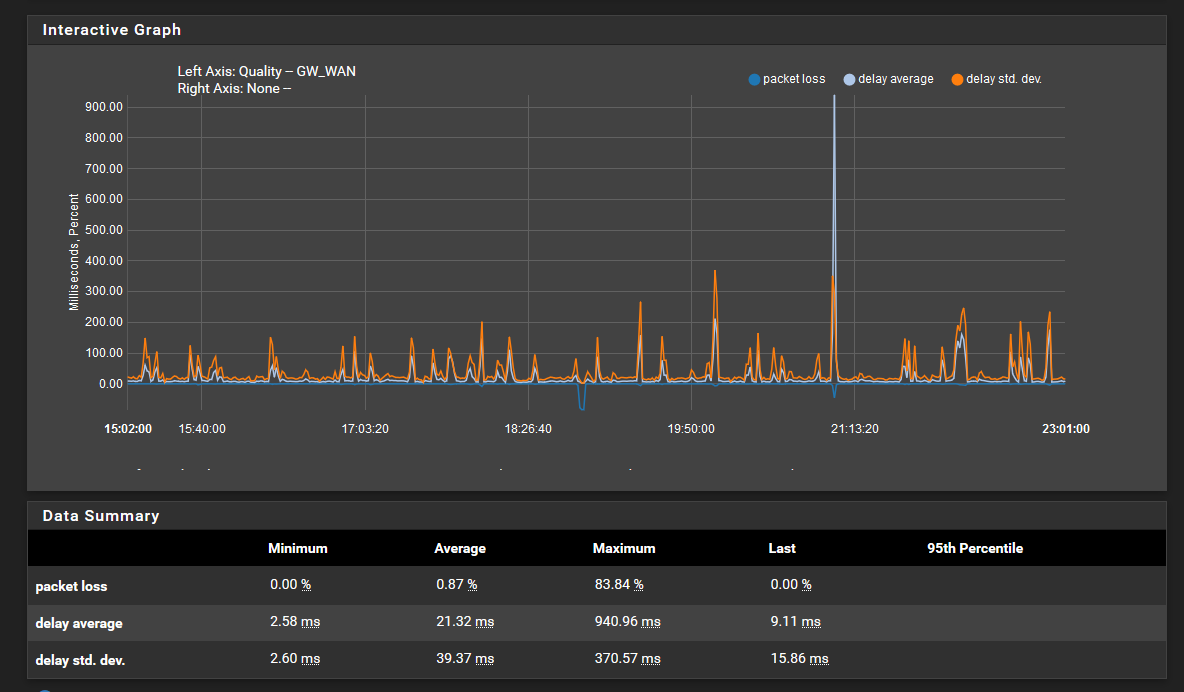
-
Is it actually a TOR exit node or a relay? If it's an exit node it seems very likely your IP is being flagged as such.
Are you running that on a separate VIP? What happens if you change the VIP it's running on?
Steve
-
@stephenw10 Thanks for your reply.
It's a TOR exit node, and it has it's own vip with the proper rdns configuration. My 'normal' traffic as webbrowsing and such, goes through the default WAN ip, which is different.
The problems still persist with the monitoring ip being 8.8.8.8 as suggested by @Derelict. I have tried to turn off all HW acceleration, updated TOR to the latest stable version, put on a traffic shaper by the means of the wizard, swapped out all cables, but nothing seems to help. The only way to get a stable connection, is turning off the TOR relay, which I really want to prevent.
-
It is something upstream, unfortunately. I don't see anything that should be causing that on the firewall.
There is nothing in pfSense that will delay the return of an echo reply from the outside.
If you want to definitively prove it is not pfSense, put a small, managed switch between the pfSense WAN port and the ISP. Set up a packet capture of the ISP port and look at the pings. If you see the echo request go out and there is a delay in its return, pfSense is not involved there at all. Take that capture to the ISP and see what they have to say for themselves.
-
It doesn't look to be much in bandwidth terms but maybe that is all tiny packets, a SYN flood out of TOR perhaps? You might check the traffic PPS graphs. Though I would expect the state table to fill more if that was the case.
Steve
-
@Derelict Thanks so much for the tip, I still have my old edgerouter lying around, I'll set it up as you said and see what happens.
@stephenw10 I checked the graphs, and it seems that the pps actually seem to dip before the ping spike, strange.
Thanks all for the advice so far! I'll have enough to go on for now and will contact my ISP with my findings next week.