Intermittent IPv4 routing issues
-
I'm having some new (as of late) connectivity issues with my internet. It seems to happen at random times and with a variety of sites. Basically I lose my IPv4 connectivity. Browsers display "Address Unreachable", cURL says "No route to host" but ping and traceroute seem to go through the motions without issue. The sites may load after several seconds but most of the time not at all. The next minute everything could be working and another minute later things could be back to acting up. It doesn't make a difference if I run ping/traceroute/cURL on a LAN device or from pfSense, the errors and/or lack thereof are the same. I've seen a couple instances where traceroute stops at a device two hops away (ISP) and then gives the "Destination Host Unreachable". They have been doing lots of upgrades lately so it's not out of the realm of possibilities but I would like a little more concrete evidence of that. The weird thing (or maybe this makes sense to someone else) is that if I use a VPN client on a LAN device, everything loads perfectly, and as soon as I toggle the VPN off, I am back to "host unreachable" messages.
Any more places I could be checking or things I could be doing?
Custom pfSense build - latest release
2x Intel ethernet cardsThanks
-
I spoke with an engineer at my ISP. Due to CGNAT, they limit each customer to 4096 available ports. According to them I am reaching that limit and at that point basically lose the ability to load more pages until old connections die off. So, is there any way to artificially limit pfSense to only use 4096 ports on the WAN side and/or be more aggressive with closing connections that aren't actively being used? I might post this over in the NAT forums as well.
-
You could create a custom set of manual outbound NAT rules which only allow 4096 ports to be used. That may not solve it entirely, but it should help.
-
Thanks for the suggestion, I'll look into it. At this point even something that only solves it partly is an improvement.
-
When you create the rules, the field you want to set strictly is the Port or Range field. You need to put in a range of ports there that is <= 4096, e.g.
60001:64096.The default range is
1024:65535. -
Okay, thanks @jimp it probably would've taken me a moment or ten to figure it out as I haven't had to implement anything like that before. I appreciate the help!
-
From the amount of states he is showing, I don't think its him having that many ports open to be honest.. We should prob merge these threads.. He stated he was only showing like 1000 states..
-
Doesn't really matter how many his side sees open vs how many ports the upstream CGNAT system believes is in use. Depending on how it's structured/configured.
-
Yeah but nothing he can do about that. If they don't close the connections.
-
Hey guys, sorry for the delayed response. This thread can be merged with the other. Whichever one makes more sense to keep.
I went through my logs and found that this morning when the wife and I got on our phones the state table jumped up, as expected. It totaled just over 4,000 states which still means it should be well below that for the WAN facing states. However, at this same time, I also saw connectivity drop out for sites that I had been tracking/logging all night without issue. Also, I saw in my logs that I've been averaging about 1,000 states for at least the past week with some times obviously being higher than that. @jimp Like you said, it seems like the upstream hardware could have some stale connections open.
If I setup a manual outbound NAT and limit it to 4096 ports at least that way I am only using a set number of ports. Even if some of the states upstream are stale, I won't be requesting new ports outside of the 4096 that I set. I would think at some point the stale connections/port mappings should time out on the upstream hardware.
I spoke with the engineer some more. I'm not sure how much this matters but he said the issue does stem from a recent/ongoing migration to new hardware. They believe that the old hardware only limited the TCP connections to 4096 ports but UDP was uncounted. The new hardware is counting both TCP & UDP connections against the port quota. They are supposed to be talking to their vendor next week to discuss possible fixes/changes. Fingers crossed they can implement a fix because I never had this issue before their migration, which was also a CGNAT implementation at that point in time.
Apparently this is only affecting about four other customers. Just my luck, go figure.
Thanks for the help thus far.
-
How many devices do you have on the network to hit 4k some states? I currently have 18 wireless devices. 3 different tablets, 3 phones.. 2 different tv streaming, etc. etc. And less than 1k states..
Do you have all your clients talking outbound for dns vs asking pfsense? 4k some states is a lot of states for a small household of devices.
-
I have 30-40 active devices. It's pretty close to a 50/50 split of wired/wireless. pfSense is the DNS server for all of those devices although I think a few (Google Home, etc.) are hard-coded with Google DNS servers. I suppose my logs could be funky but I'm fairly certain I'm looking at the right stuff.
And as I said, I do average about 1,000 states. But there are some spikes...not sure what from.
-
I would look to see why/when your spiking - that is prob when your having issues.. That is not really normal... Are all the states coming from single device?
Does it happen same sort of time? what your graph of states look like for say last week
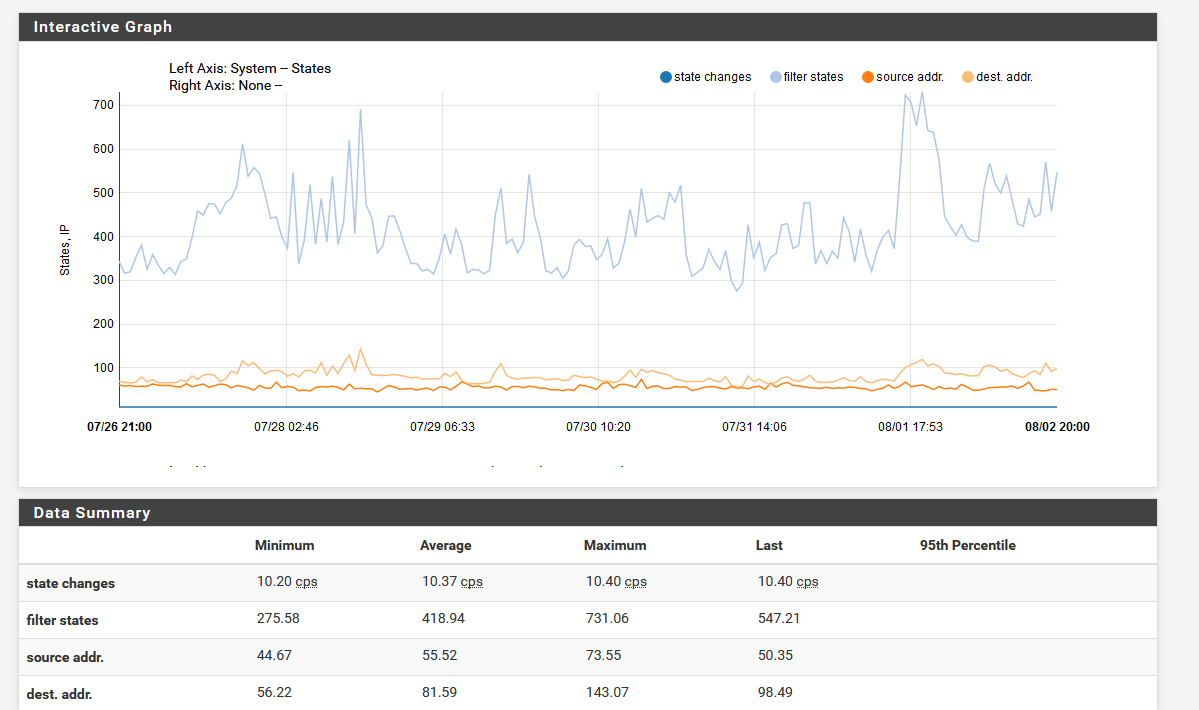
Do you p2p? That would for sure ramp up your connections.
-
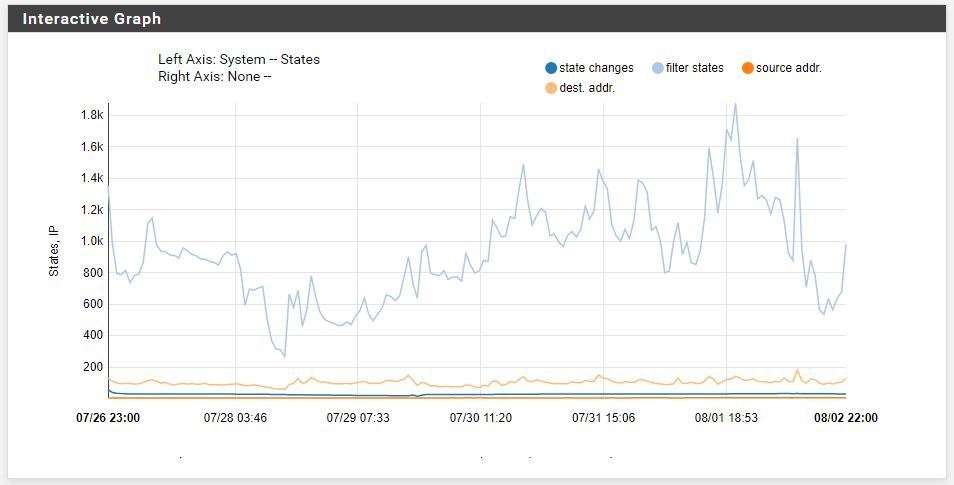
I haven't discovered any patterns at this point. I was looking at some external logging but pfSense matches what my other logs show. The scaling hides some of the spikes but you can see a pretty large one from today.
No P2P and the spike around 10am today has me scratching my head what it could be. My wife was home but I don't know if it would be her devices. I would think the more likely culprit would be my internet/connectivity monitoring systems but those should be a constant flow, not spiky.
The past week:
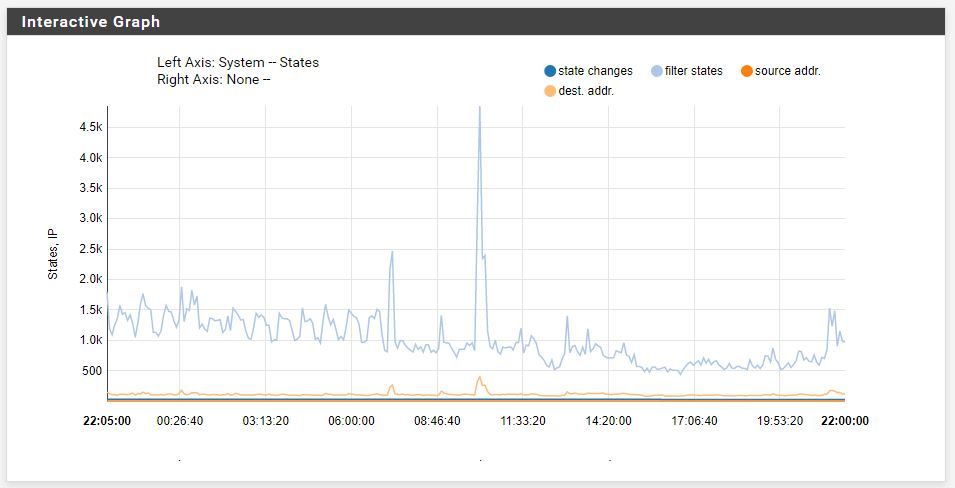
Today:
-
Yeah that is a crazy spike.. Looks like something was talking to a bunch of stuff - see the dest addr spike up as well.
-
Oh nice catch. I didn't see that and my other logs didn't break that out. Looks like that spike boosted everything 4x. The dest addr jumps from 100 to 400 and the states go from about 1k to 4k. So now I have to figure out what is causing it...
Any suggestions besides staring at a screen til the needle jumps and then scrambling through the state table
 ?
? -
Prob just log your allow rule for a bit, sending it to another syslog so easier to parse though and see who is the jump in traffic.
-
Thanks. I'll see what I can do.