2.4.5 High latency and packet loss, not in a vm
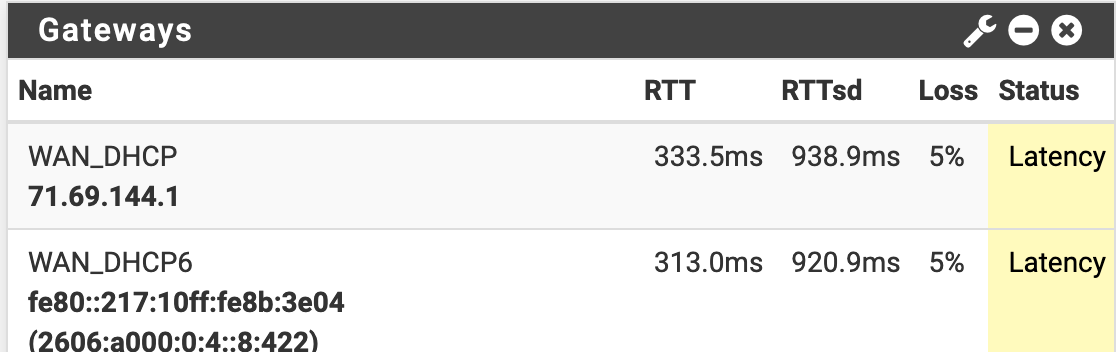
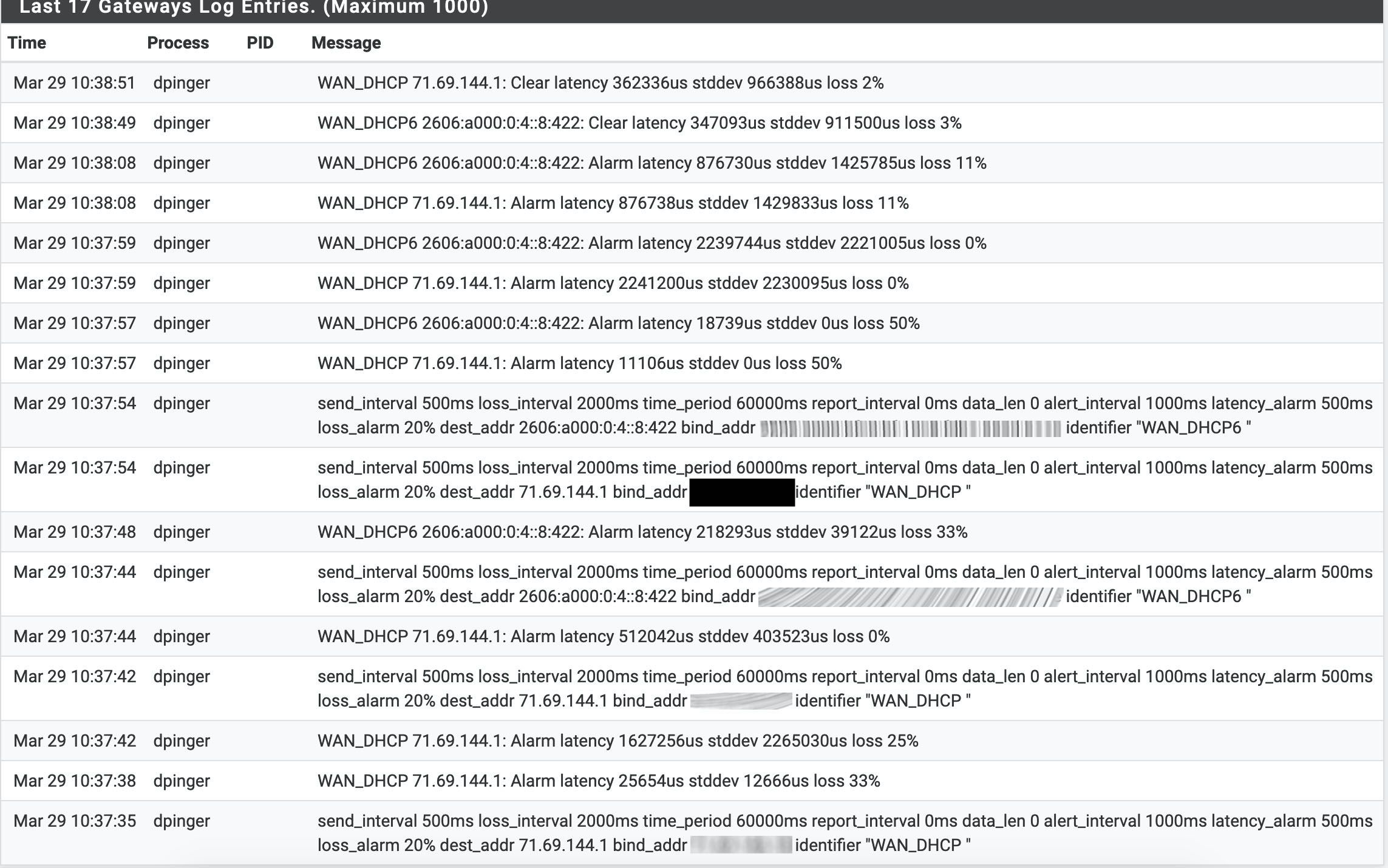
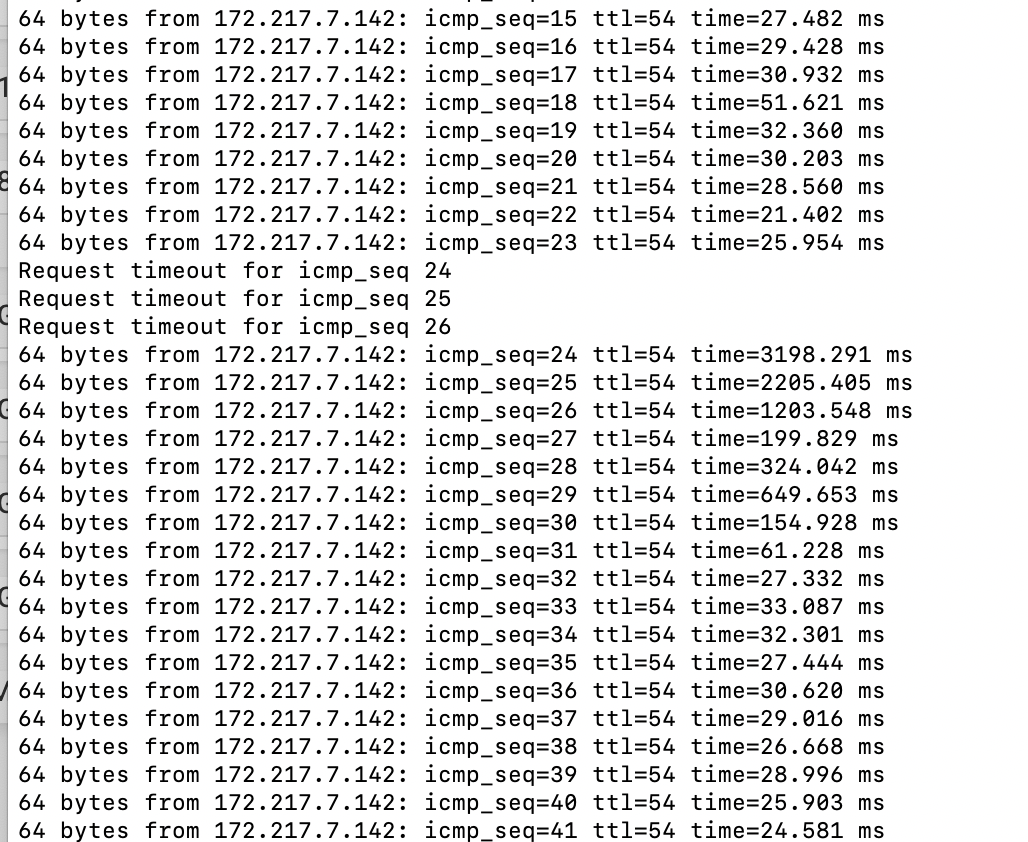
-
I was doing some thinking about this issue last night at 3am.
I know I hit it (on a VM) and I was thinking "What have I changed from the defaults that maybe some other users have also) and I figured maybe
net.isr.dispatch = deferredI know I set that to try and get a PPPoE performance increase. Have others who are hitting this bug set that too?
-
No,
net.isr.dispatch = deferreddoes not appear to be common to system hitting this. Good thought though.Steve
-
Hmmm someone with a test system hitting this issue could maybe share his config.xml so we can try with swarm intelligence?

-Rico
-
@Rico Already shared config and other information with Netgate. @stephenw10 has been immensely helpful coordinating that.
-
@stephenw10 said in 2.4.5 High latency and packet loss, not in a vm:
https://go.netgate.com/
Just opened a support ticket with my config.xml attached, INC-49525.
Not a virtual instance, X11SDV Xeon-D 2100 series motherboard, 16GB RAM. -
Had the same issue yesterday when I upgraded. Have since reverted to 2.4.4-p3 and the issue disappeared completely.
I run it on a Eglobal Braswell Fanless Mini PC AES-NI Intel N3160/J3160 Qaud Core Pfsense Computer Server 4K 2HDMI 2LAN(RJ-45) 300M Wifi.
-
@wernsting Do you have any large aliases or huge lists of IP's in any firewall rules? Have you modified the max table entries (and if so, to what)?
Do you use PPPoE? -
@muppet can you define "large"? One mans "large" is another mans "small"! :-) 1000? 10000? 1000000?
-
It's total entries not individual table size that counts from my experiments.
100000 and up the issue is very noticable. 100k and a bit is the bogonsv6 table. 200000 and up filter reloads can basically freeze the system (unresponsive GUI and packet loss) even with powerful HW. On my supermicro 5018D-FN4T (XG-1541) it becomes unresponsive at around 300000 total table entries for minutes if the filters are reloaded.
max table entries isn't relevant other than you can prevent too many entries from loading if you set it small. In FreeBSD 11.3Stable it was hard limited to 65k. Netgate submitted a patch to make it tunable.
I would be interested in knowing why that 65k hard limit showed up in 11.3?
-
Hi,
I'm just a small household that suffers my nerdy-ness that hated the ISP provided crapware— so no, nothing like that. My set up is hardly configured beyond the base installation :)
Cheers,
-
@wernsting You'd be surprised. Out of the box defaults with ipv6, a few geoip blocks and other ip block lists in pfblockerng and you can easily get over 400k if not more in total.
-
Fair enough.
However in my case I don't have any block lists configured, nor pfblockerng installed as a package, neither do I have aliases or additional firewall rules above the two standard rules (RFC 1918 networks & Reserved
Not assigned by IANA).@muppet forgot to mention no I have not modified the max table entries and my WAN is DHCP IPv4 only.
-
@wernsting Interesting. Very much sounds like you have experienced something else or the problem manifests itself with a much smaller number total table entries on lower powered HW.
Glad you were able to recover to 2.4.4-p3. Hope a fix, other than downgrading, comes along sooner rather than later that works for all situations. The 2.4.4 line has been impressively stable for a long time, we were spoiled ;)
-
My 2.4.4-p3 work without any problem for a long time... But when 2.4.5 came out I did an update as usual... Then problems with high latency started... I was even unable to get in WEB interface right after update restart, because of over 3000ms... After some time, lets say 20 sec. everything get back to normal... I have some friends who I gave internet and they are gamers... I have now 3 WAN set as failover, but every gets disconnected due to high latency on every single WAN at the same time...
I caught it happens every time when i do some config on interfaces and apply it... I also installed pfSense on another machine to test it and it behave the same...
This behavior is unacceptable, so I reverted to 2.4.4-p3 and everything is fine now :) Problem was in place even when I disconnect any of the ISP, because i think it sees this as interface reconfigure and make ping over 3000... -
I decided to downgrade the number of CPU's used in the VM.
Went from 32 core to 8 core. It had similar problems. Slow response in the webGUI and latency on monitored IP's.
Downgraded to 1 CORE and everything came up quickly and everything is working as expected.
No 100% CPU anymore and everything is responsive and packet loss is back to 0.0%.
-
@Cool_Corona said in 2.4.5 High latency and packet loss, not in a vm:
I decided to downgrade the number of CPU's used in the VM.
Went from 32 core to 8 core. It had similar problems. Slow response in the webGUI and latency on monitored IP's.
Downgraded to 1 CORE and everything came up quickly and everything is working as expected.
No 100% CPU anymore and everything is responsive and packet loss is back to 0.0%.
How do you change the number of cores? Is that an Intel thing or does it also apply to the AMD processors as well?
-
@jdeloach You can do that in a Virtual Machine, bare metal hardware not so much.
-
If you are using a virtualized system (like qemu-kvm, etc), you can decide whether to use the physical processor or a logical processor, with the desired characteristics and functionalities (such as the number of cores, extensions such as AES-NI etc.)
-
@jwj said in 2.4.5 High latency and packet loss, not in a vm:
@jdeloach You can do that in a Virtual Machine, bare metal hardware not so much.
Yeah, that is what I thought. Need some more coffee this morning. I haven't used virtual memory for running programs in the past. Will have to give that a try someday. Thanks.
-
@Cool_Corona said in 2.4.5 High latency and packet loss, not in a vm:
Downgraded to 1 CORE and everything came up quickly and everything is working as expected.
This is a great observation! Testing now.