2.4.5 High latency and packet loss, not in a vm
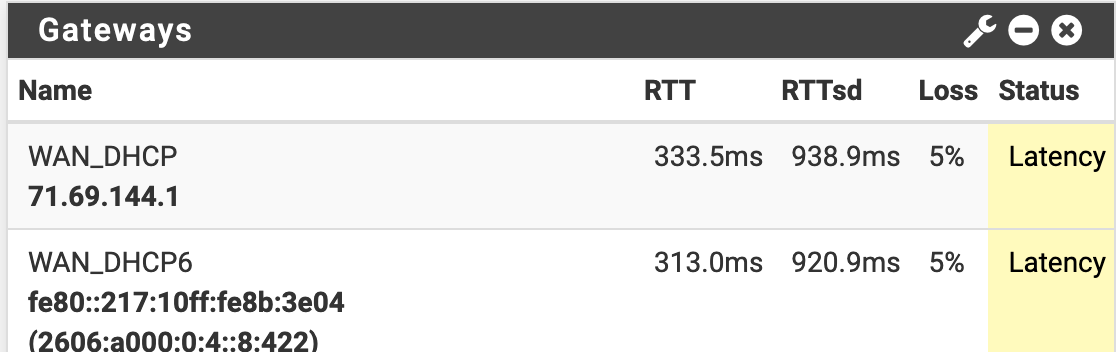
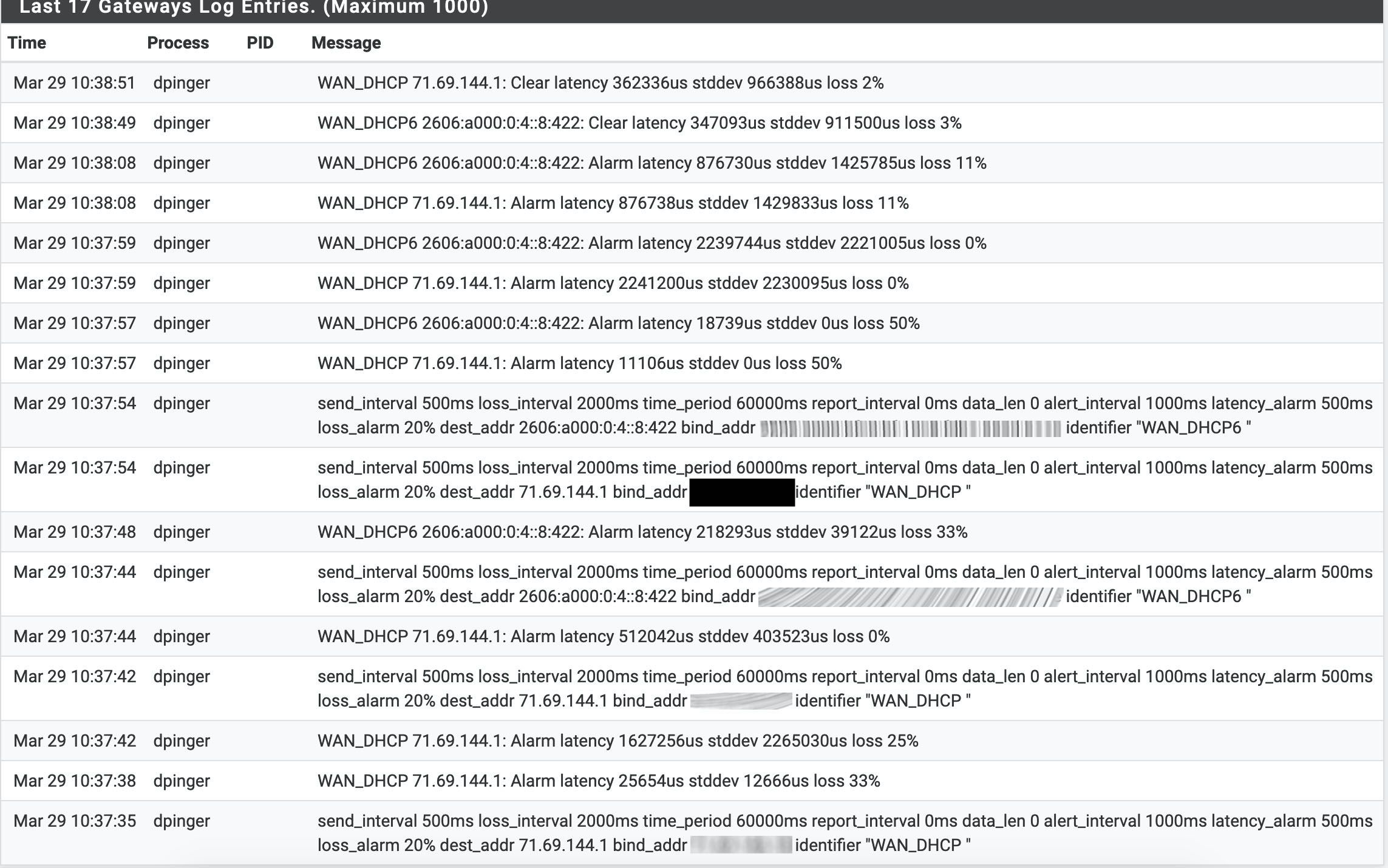
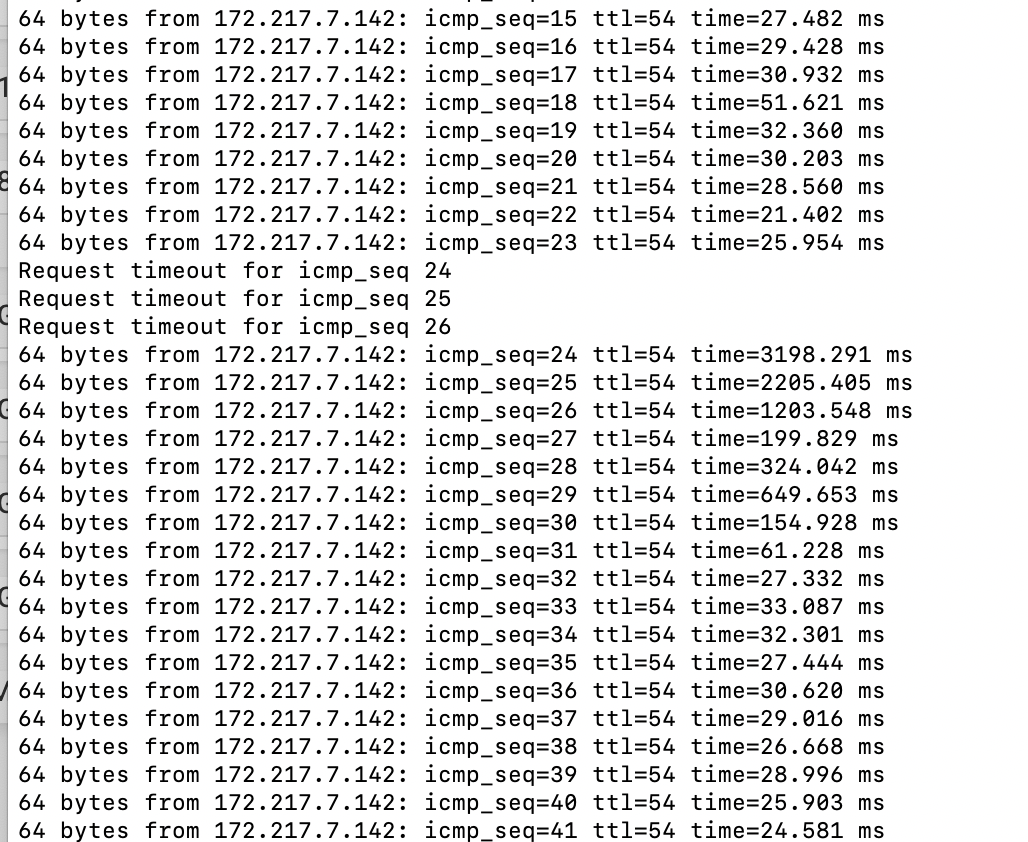
-
I can ping ipv6 without issue. I get a /56 from my isp.
The only thing that has changed in my configuration is the pfsense version.
I have offered to share my config.xml to test on matching hardware. My Supermicro hardware is the same as a box Netgate sells other than not being Netgate branded.
This is an frustrating problem, more so for Netgate than anyone else I'm sure.
-
Can you see what is calling pfctl if you run, say:
ps -auxdww | grep pfctl. -
root 25572 33.5 0.0 8828 4888 - R 09:34 0:04.12 | | `-- /sbin/pfctl -o basic -f /tmp/rules.debug
-
I was able to run ps auxdww >> psoutput a few times before the shell locked up.
Here it is: (removed)
-
Thanks, that could be useful.
Interesting there are things there using far more CPU than I would ever expect.You might want to remove it though if those public IPs are static.
Steve
-
@stephenw10 Dynamic. No open ports, so they can bang away all they want ;)
-
I have some spare cycles, I suppose a lot of people do. You, however, are slammed.
If it would be helpful I'm willing to run through a methodical sequence of configurations and test to try to get a handle on the issue(s).
If you provided an outline of configurations like: Generic install, no ipv6, Test. Make big table(s). Test. Turn on ipv6, test. Make big ipv6 tables. Test. Like that.
I can give it some hours over the next day or two and see if that helps get a handle on the issue(s).
I would ask that the tests be specific and the data needed be spelled out clearly so my gaps in experience doesn't reduce the usefulness of the exercise.
I have a Supermicro 5018D-FN4T (32GB ECC) which is the same as Netgates XG-1541. I have been doing zfs (single ssd) UEFI installs.
I wonder if there is something apparently unrelated going on that is common with the installations that are experiencing these issues. Something simple like UPnP or the like. I wouldn't think so, but it would be nice to know exactly what is what as each service is configured in a methodical sequence.
Anyhow, just a thought.
-
The fact that pfctl is running for so long and using so many cycles implies it's having a very hard time loading the ruleset for some reason.
I would manually check the /tmp/rules.debug file. Make sure it's not absolutely huge for example.
If it isn't then start disabling things that add anything to it. So UPnP, and packages like pfBlocker.Steve
-
Nothing in there that shouldn't be. I have disabled everything including pfblocker. Made a big url alias and the problem persists.
To me, I could be wrong, it looks like big tables big issue. Small tables small issue. Small tables don't cause a dramatic issue so it appears as if everything is ok when it isn't.
My curiosity to find out what is going on is waning. If there is anything I can do to help I'd be happy to do so. Otherwise I'll go back to 2.4.4-p3 or onto something else.
-
I agree it does seem like that.
If you don't actually have any large tables try setting the sysctl in System > Advanced > Firewall back to something closer to the default. So set
Firewall Maximum Table Entriesto, say, 65k or something even smaller.There was coded added to allow that to be set and others have seen that as the issue. We see some reports (I have seen it myself) where you get the error 'unable to allocate memory for (some large table) but it then loads fine for subsequent reloads. It appears that's way pfctl may be doing something it shouldn't.
Steve
-
@stephenw10 I have done that and seen the can't allocate memory when total table entries > Maximum Table Entries. I can have my config (lots of vlans) with no packages, ipv6 enabled so the big bogonsv6 table and have the issue. Turn off block bogons and the symptoms are eliminated. The Max table entries setting has nothing to do with it. Total table entries is what matters. The only thing I haven't done is start from scratch and added stuff, I always started from my config and then disabled stuff.
Anyhow, what happens will happen. I'm not going to get stuck on this for much longer.
-
Ok, so to confirm the presence of the large table(s), irrespective of the max table size value, triggers the latency/packet-loss/cpu usage?
And removing the table completely eliminates it?Steve
-
Total table size is limited by max table size. If I set max tables at some arbitrarily large number, say 20000000 but only have a few small tables (no bogonsv6, no ip block lists) things are fine, meaning the symptoms of the problem are not noticeable. I have done that.
It's obvious that the opposite can not be configured, large tables small max tables.
I'll demonstrate some time later today, things to do right now.
-
OK, only took a moment.
Set max tables to 20000000.
Turned off block bogons.
Disabled pfblocker.Rebooted.
Reboot was fast, 2.4.4-p3 fast.
Ran ps auxdww | grep in a while 1 loop
Reloaded the filters (status->filter reload)No lag, no latency, didn't notice it in any way.

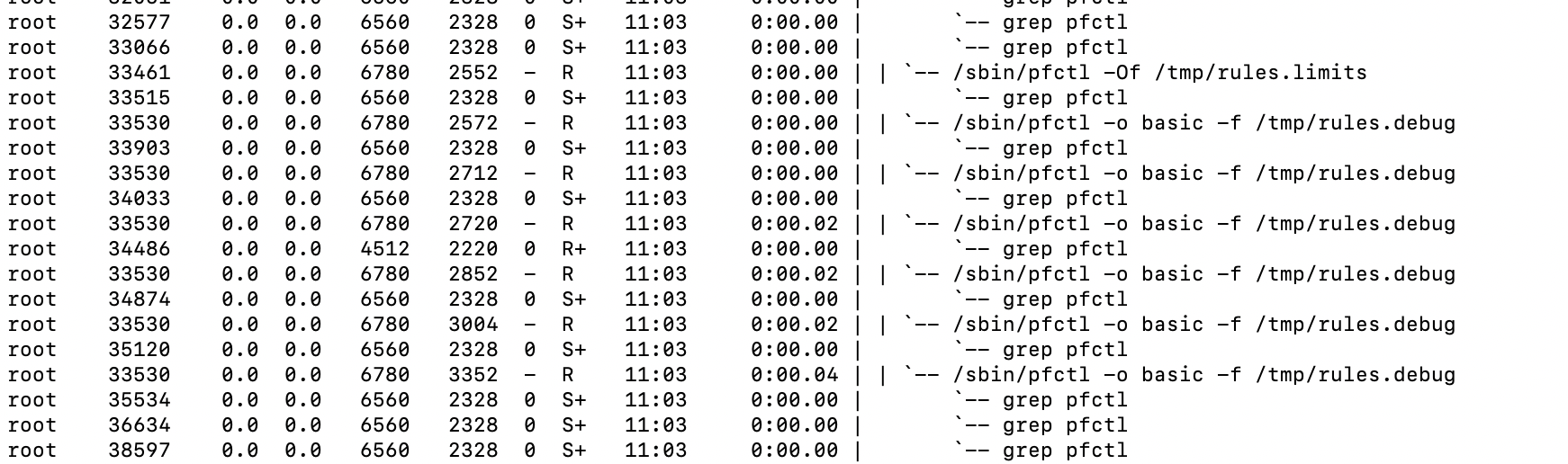
Didn't even see pfctl pop up when running top. Must have happened in between refreshes.
Conclude what you will from this. The evidence shows max tables limits total table size (what is supposed to do) but the total table entries is what causes the symptoms of the issue (cause currently unknown, some regression maybe in pf) to become obvious.
-
So, I'm either going to go back to 2.4.4-p3 or another solution (I have a ISR I could drag out of the closet). I want to go back to the set and forget setup I have enjoyed with pfsense for a while now.
The question that I feel needs to be answered by the FreeBSD team is this:
Why was that hard limit implemented? I would assume there was some observed reason for rewriting that with a hard limit.
-
Has anyone managed to find a permanent solution to the problem where pfblocker and bogons can be enabled without latency or loss?
-
@mikekoke Not that I can see.
There is a bug in redmine that has exactly one update from Netgate, can't reproduce in their testing environment. We are passed the idea that it is a bug. It is. It sure looks like a bug that would require upstream (FreeBSD) participation in resolving.
The question is do they even bother fixing it?
You could say:
- Use 2.4.5 if you do not have a large number of total items in tables.
- Stay on 2.4.4-p3 if you have a large number of total table items.
2.4.4-p3 remains a viable release. Accommodations made to set repositories to the 2.4.4 versions make it a reasonable option.
Put all the effort into 2.5 knowing that both current options are safe and secure or divert resources to fixing 2.4.5? FreeBSD 11.3 is not EOL but it is also not a target for ongoing development. Will FreeBSD put resources into this bug?
I don't know the answers to those questions. I not going to offer an opinion on one way or the other. I do think Netgate should put out a statement setting out their position for the short term. 2.5 is the long term resolution.
-
@jwj said in 2.4.5 High latency and packet loss, not in a vm:
Accommodations made to set repositories to the 2.4.4 versions make it a reasonable option.
Does that repo/branch choice also affect packages update/installation?
-
Yeah, there are two drop down menu choices under System->Update->System Update and System->Update->Update Settings.
The base OS/pfsense and the package repo should be correct. As always backup your configuration, make a snapshot if your in a virtual env, and have a plan to recover if you end up FUBAR.
It is too bad the download link for 2.4.4-p3 has not been restored. You can open a ticket and ask (nicely :) for one even if you do not own Netgate HW or have a support contract.
-
@jwj said in 2.4.5 High latency and packet loss, not in a vm:
System->Update->Update Settings.
Thanks. I got around to testing and this affects what package updates are detected, e.g. Suricata 4.1.7 vs 5.x. So that's good to know. Would be handy if they left the previous version there all the time (and/or had a warning on the package page if you're checking the wrong repo for your version) but nice it's there now.