Grafana Dashboard using Telegraf with additional plugins
-
@von-papst check the CRLF on all the plugins. Then use the telegraf test command to check that there are no errors. Failing that add the debug logging option to telegraf and check the log file. Instructions for the above are on the GitHub readme.
-
@wrightsonm Got pfblocker working, changed queries and added some info. But Gateway RTT and loss still not working.
-
@wrightsonm Got everything working now. I needed to modify some queries in the dashboard and added gateways.py script.
-
I'm a bit confused, where do the plugins need to be placed? Am I supposed to upload them to my pfSense install?
-
@jpetovello you should upload them to you pfsense.
-
I think there was some drift between my local system and my repo. I've updated the dashboard JSON. It should work with the updated gateways/interface plugin.
-
@victorrobellini What is your influxdb ram utilisation looking like with the latest set of changes? With the grafana dashboard, my influxdb ram has increased to 12GB. I had to increase the RAM allocation on my docker VM (now at 20GB). I'm going to keep an eye on it.
I think high series cardinality might be related. Will do some investigations. Unfortunately InfluxDB OSS v2 doesn't currently implement the cardinality command (only Cloud version at the moment).
https://docs.influxdata.com/influxdb/v2.0/reference/flux/stdlib/influxdb/cardinality/I also think the logged data shows something port scanning me yesterday which may be related to the big increase in cardinality of the data.
-
I found this neat little command playing around with PowerD options and it seems to be really light and work well for tracking CPU frequency changes.
sysctl dev.cpu.0.freq
Was thinking it would make a nice graph for those are also using PowerD which I would think would be most people but I could be wrong.
I would write this myself but it would just end up getting done better by others in this thread :)
@VictorRobellini what do you think about this, good add?
-
Interesting, I never messed with that, I just turned it on. This is an easy fit and can use the same script as the telegraf_temperature.sh script.
All you need to do is add the following line to the end of the script and build some graphs.
sysctl dev.cpu | fgrep "freq:" | tr -d '[:blank:]' | awk -v HOST="$HOSTNAME" -F '[.:]' '{print "temperature,sensor="$2$3",host="HOST" "$4"="$5""substr($7, 1, length($7)-1)}'The better way to implement it (which I don't have the time for right now) is to completely rename the telegraf_temperature.sh script to be something like telegraf_sysctl.sh and update all of the commands to output with a similar format and then update the queries and graphs. If you just want to poke around and see what you can get, use the above recommendation.
sysctl dev.cpu | fgrep -e "freq:" -e temperature | tr -d '[:blank:]' | awk -v HOST="$HOSTNAME" -F '[.:]' '{print "sysctl,sensor="$2$3",host="HOST" "$4"="$5""substr($7, 1, length($6)-1)}' sysctl hw.acpi.thermal | fgrep temperature | tr -d '[:blank:]' | awk -v HOST="$HOSTNAME" -F '[.:]' '{print "sysctl,sensor="$4",host="HOST" "$5"="$6"." substr($7, 1, length($7)-1)}'Something like this:
sysctl,sensor=cpu0,host=pfSense.home freq=1900 sysctl,sensor=cpu3,host=pfSense.home temperature=47.0 sysctl,sensor=cpu2,host=pfSense.home temperature=47.0 sysctl,sensor=cpu1,host=pfSense.home temperature=49.0 sysctl,sensor=cpu0,host=pfSense.home temperature=49.0 sysctl,sensor=tz1,host=pfSense.home temperature=29.9 sysctl,sensor=tz0,host=pfSense.home temperature=27.9 -
@victorrobellini said in Grafana Dashboard using Telegraf with additional plugins:
sysctl dev.cpu | fgrep "freq:" | tr -d '[:blank:]' | awk -v HOST="$HOSTNAME" -F '[.:]' '{print "temperature,sensor="$2$3",host="HOST" "$4"="$5""substr($7, 1, length($7)-1)}'
That worked like a charm, thank you so much.
-
Anyone else having problems with Uptime displaying?
Mine just shows N/A
-
@jpetovello This is what I have for my query
SELECT "uptime_format" FROM "system" -
@jpetovello There's an entire section of the README dedicated to troubleshooting. Please review the docs and report your findings.
- Check that telegraf is actually able to collect the info (first half of the troubleshooting section)
- Check what is being stored in influx (second half of the troubleshooting section)
-
@wrightsonm My influx sits around 6GB. Every now and then I start reading up on Influx retention and downsampling, but I end up just truncating my db since it's faster.
-
@seamonkey said in Grafana Dashboard using Telegraf with additional plugins:
@victorrobellini 7.1.1, but I wouldn't think that would make a difference regarding my particular issue. Your design applies the value mapping function to all fields within the panel, but instead it should only be applied to the Status column exclusively under the Override settings. I've fixed this on my own dashboard and I started to attempt a pull request to fix it, but didn't have the patience to manually adjust only the relevant lines in your JSON file and reimport for testing.
I just updated my dashboard and this is still an issue. Anyone with interfaces that have a MAC address starting with 00 will have 'DOWN' listed as their physical address.
-
@seamonkey What does the data in influx show?
Good point about the value mapping and threshold. I've updated the interfaces widget to apply thresholds and value mapping to just the Status column.
-
@victorrobellini said in Grafana Dashboard using Telegraf with additional plugins:
What does the data in influx show?
Sounds like you got it fixed, but just in case it's still relevant...
> select * from interface where mac_address!='Unavailable' limit 2 name: interface time friendlyname host ip4_address ip4_subnet ip6_address ip6_subnet ip_address mac_address name source status ---- ------------ ---- ----------- ---------- ----------- ---------- ---------- ----------- ---- ------ ------ 1607846650000000000 LAN fallia.thegalaxy 192.168.0.1 00:15:17:xx:xx:xx em0 pfconfig 1 1607846650000000000 WAN fallia.thegalaxy 00.00.00.00 00:15:17:xx:xx:xx em1 pfconfig 1 -
@seamonkey
The data looks good.I've already committed the update that isolates the value/thresholds to status.Is your IP really null?
-
@victorrobellini The mac addresses are there, I've just censored the last three hex pairs for the sake of privacy. Same for the WAN IP. There's nothing wrong with the influx data, and as I mentioned previously, I was able to fix the problem by moving the value mappings under the Field tab to the Overrides tab in order to explicitly apply them to the Status field - which it sounds like you've implemented in the latest update.
-
@victorrobellini I've done a bit of investigation into the Series Cardinality of the database.
We changed the ip_block_log grok pattern to tag more fields. As a result the cardinality of the database increased significantly. The downside to this is querying the database to show the new pfBlocker detail section became very RAM intensive. I was using > 20GB RAM in influxdb to display the last 10mins on the grafana dashboard. I had an OOM Out of Memory issue that crashed my Docker VM, so at this point I dropped the entire measurement and influx memory memory usage looked much happier again.
After 2 days of collecting new pfblocker data, I looked at the Cardinality of the database using this query (I am using Influx 2.0.4):
import "influxdata/influxdb/v1" cardinalityByTag = (bucket) => v1.tagKeys(bucket: bucket) |> map(fn: (r) => ({ tag: r._value, _value: if contains(set: ["_stop","_start"], value:r._value) then 0 else (v1.tagValues(bucket: bucket, tag: r._value) |> count() |> findRecord(fn: (key) => true, idx: 0))._value })) |> group(columns:["tag"]) |> sum() |> keep(columns: ["tag","_value"]) cardinalityByTag(bucket: "pfsense")(Whilst Influx 2 does have a cardinality function, it is only currently available in the Cloud variant, not the OSS variant....
The above function does the job though)Cardinality was 34540! Influx is currently using 6GB RAM at this level.
Breaking this down it is attributed to:- src_port: 15780
- dest_port:10603
- src_ip:7980
- other metrics (not many)
I have now changed my telegraf config to tag less stuff. For now i've untagged src_ip, dest_ip, src_port, dest_port
grok_patterns = ["^%{SYSLOGTIMESTAMP:timestamp:ts-syslog},%{NUMBER:rulenum},%{DATA:interface},%{WORD:friendlyname},%{WORD:action},%{NUMBER:ip_version},%{NUMBER:protocolid},%{DATA:protocol:tag},%{IPORHOST:src_ip},%{IPORHOST:dest_ip},%{WORD:src_port},%{NUMBER:dest_port},%{WORD:direction},%{WORD:geoip_code:tag},%{DATA:ip_alias_name},%{DATA:ip_evaluated},%{DATA:feed_name:tag},%{HOSTNAME:resolvedhostname},%{GREEDYDATA:clienthostname},%{GREEDYDATA:ASN},%{GREEDYDATA:duplicateeventstatus}"]The next step is to look into rewriting the dashboard to perform the required grouping and aggregation.
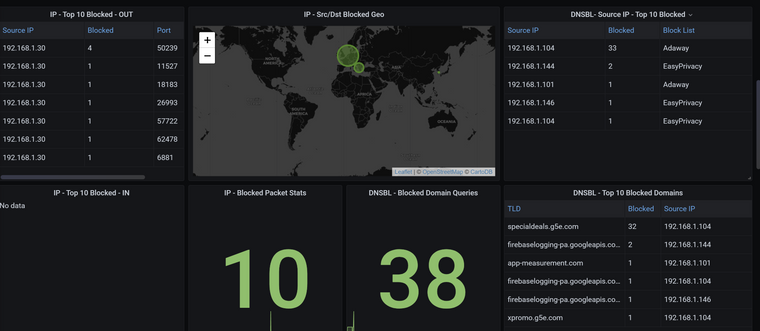
I've started with this table:
IP - Top 10 Blocked - IN (By Host/Port)Original query:
SELECT TOP("blocked",10),src_ip,dest_ip, protocol FROM ( SELECT count("action") as "blocked" FROM "autogen"."tail_ip_block_log" WHERE ("host" =~ /^$Host$/ AND "action" = 'block' AND "direction" = 'in' ) AND $timeFilter GROUP BY src_ip,dest_ip,protocol )New V2 Query using Flux:
from(bucket: "pfsense") |> range(start: v.timeRangeStart, stop: v.timeRangeStop) |> filter(fn: (r) => r["_measurement"] == "tail_ip_block_log") |> filter(fn: (r) => r["_field"] == "src_ip" or r["_field"] == "dest_ip" or r["_field"] == "dest_port" or r["_field"] == "action" or r["_field"] == "direction" or r["_field"] == "protocolid" or r["_field"] == "host") |> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value") |> filter(fn: (r) => r.host =~ /^.*$/ and r.action == "block" and r.direction == "in" and r.protocolid =~ /^(6$|17$)/) |> group(columns:["src_ip","dest_ip","dest_port"]) |> rename(columns:{action: "Blocked"}) |> count(column: "Blocked") |> group() //use group to ungroup data and return to a single table |> top(n:10, columns: ["Blocked"]) |> sort(columns: ["Blocked"], desc: true) |> yield()This is as far as I have got for the time being.
Thought I would share this before I got too far into updating the dashboard.
I suspect I won't get a good view of performance imrpovement until I've redone all of the pfBlocker Details section.
Also raising this now as it involves an update from Influx v1 to v2 to support the flux language.
Once you get used to flux, it is really quite powerful.
The old influxql language can still be used with v2, they are backwards compatible.You thoughts & opinions are appreciated.