BIND DNS stops working 2-7 hours after reloading [SOLVED]
-
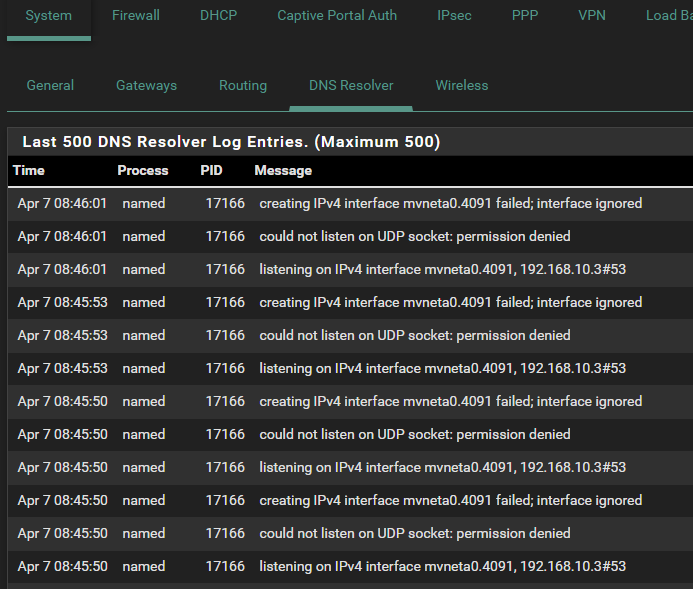
When I hit save and the package reloads I get between 2 and 7 hours of DNS service - at which point I need only to hit save in the "Views" page again to return service. Below is the log capture a couple hours after failure. I had note yet refreshed the package (hitting "save" again).
I tried narrowing down the amount of time the service is up to compare to configured timeouts but I haven't been able to really hone in on it. The IP seen here is the CARP address FYI.
Any insight as to what's actually causing the problem?
-
searching with google revealed that there is probably another instance of named running
did you try a reboot ? stop the service, check with diagnostic / system activity if there are multiple istance of named, kill them all and restart the service
or another service using port 53 on that interface -
I'll try some things along those lines... thanks. Though it's tough since I must wait so long for results.
Perhaps I have my "sync" mis-configured?
Am I correct in understanding that BIND's sync function does not use CARP addresses or pfSync? In both the master and slave servers I have entered the zone master IP. Changes in the master are immediately reflected on the slave... no CARP addresses.
-
yes, you are correct, that is a function of bind9 if you refer to allow-transfer/also-notify
-
OK, thanks.
I'm 6 hours in on stability after realizing and making a change in hopes of long lasting stability:
I had BIND listen on "all interfaces/IP addresses". I see why this may be a problem when using VIP's for CARP. I now have it only listening to the CARP addresses (of multiple VLAN's) but not my WAN VIP.So far so good... hope I didn't jinks it. ;)
-
...Not so lucky.
It failed after 6h 42m.I'll continue trying other ideas.
-
Still no luck. All I have to go on is what's going on on the general logs just before BIND DNS stops working due to the "down" interface. I sill can't get a consistent amount of up time after reloading either. Still usually around 6 hours but it has been as quick as 10 mins a couple times.
Here is the DNS log marked for when loss of service happens.
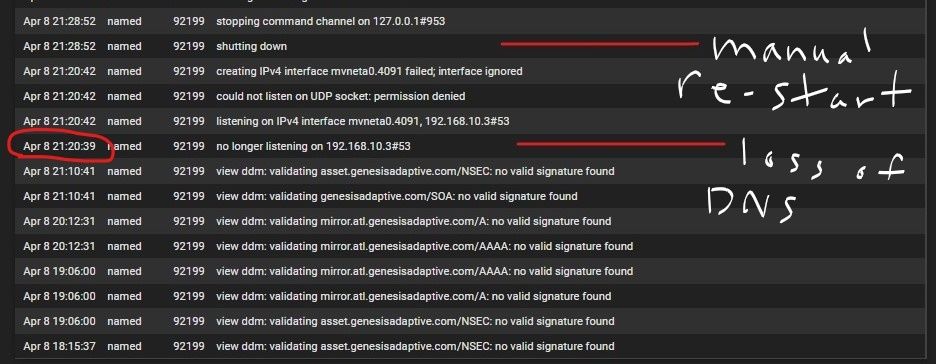
and here is the general log just before and during that time of LoS - the 3 screen shots are ordered latest at the top as if it were being viewed in the GUI.
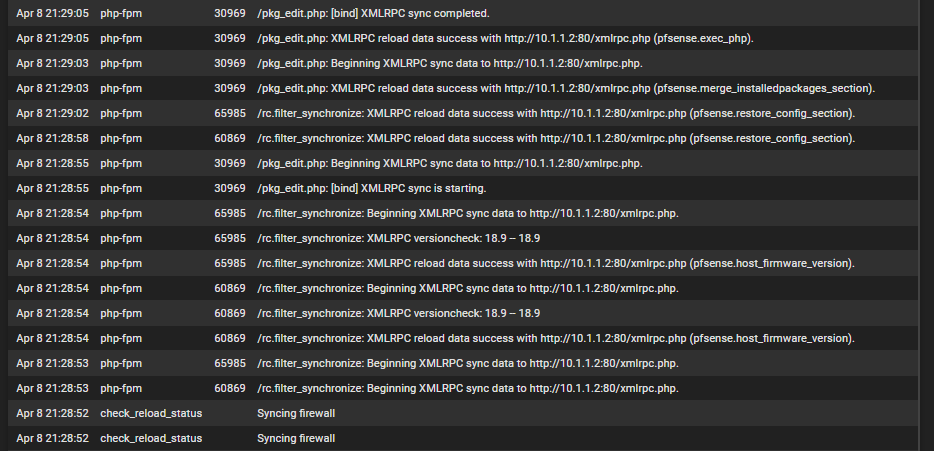
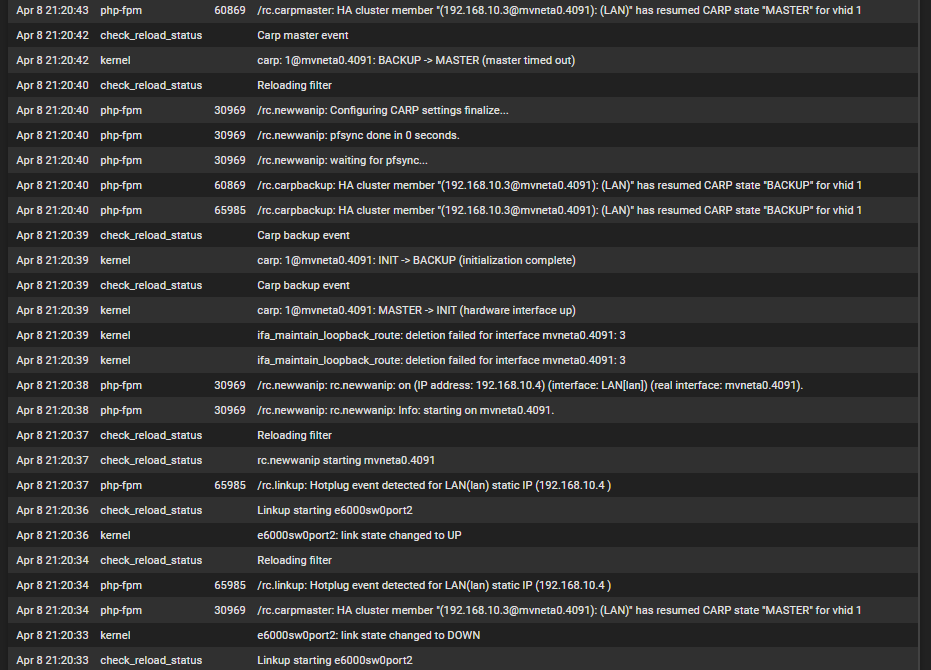
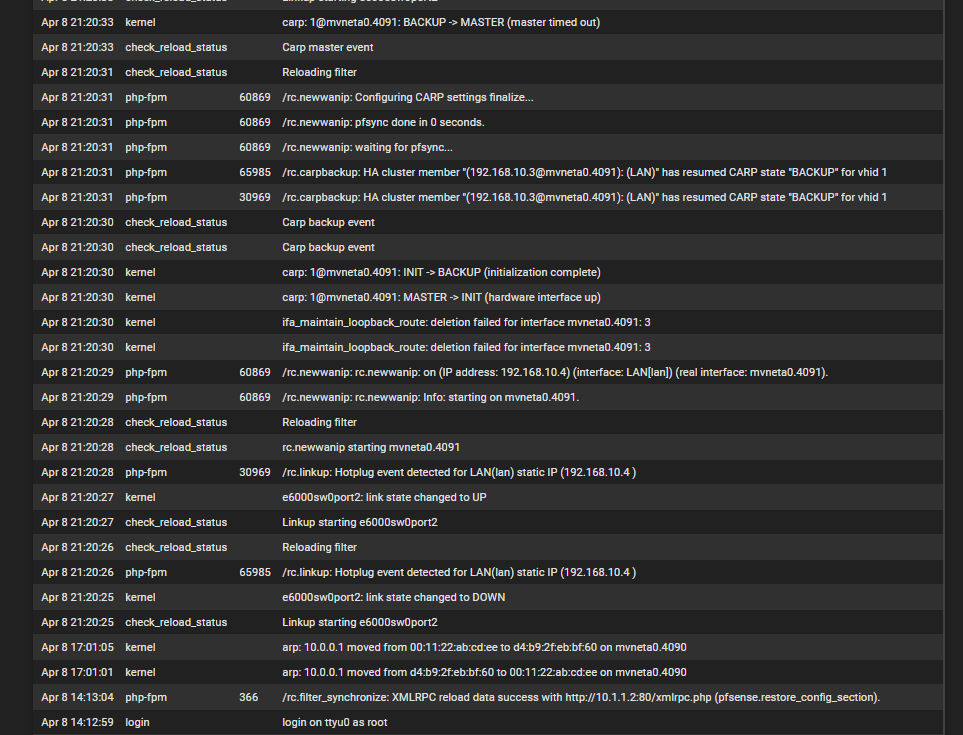
-
Hello -
Obfuscating things like RFC1918 private networks is going to do nothing except prevent people from being able to help you.
MAC addresses too.
-
Ah. Thanks. ...re-posting.
-
SOLVED: I have a Cisco SG-350 downstream of the pfSense box(es). The problem definitely resided there.
I had EEE turned on on the Cisco SG-350.
The were no obvious other symptoms of this besides just port 53 on the native VLAN for the trunk between the SG-1100 and the Cisco SG-350, going down randomly within 24 hours. (more substantial test revealed that failure occurred as little as 10 minutes and as much as 21 hours)
~A