IPSEC with VTI - trap not found
-
Hi everyone, I am experiencing some very unstable behavior with an IPSEC VPN between two pfsense firewalls running 2.4.5. I feel like I have tried just about every combination of phase 1 and 2 config while trying to troubleshoot, but I haven't had much luck. These two firewalls seemed to work just fine with IPSEC VPNs prior to moving over to VTI. The routes were becoming a bit difficult to manage, so wanted to utilize a dynamic routing protocol.
I'v spent hours on this since originally posting and think after setting up syslog that I have finallly gotten somewhere. I believe I am a victim of this bug.
https://redmine.pfsense.org/issues/9767
I am seeing this in the GUI after the tunnel had been working okay initially.
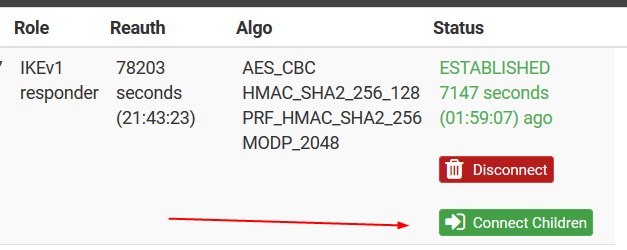
I am also seeing the same log data as posted in this bug 9767..
02[CFG] trap not found unable to acquire reqid 3000 12[KNL] creating acquire job for policy 65.182.241.141/32|/0 === 216.228.186.7/32|/0 with reqid {3000}Like I said, I've played with just about every setting in the phase 1 and 2 section of the config. Including the adjustment of the "Child SA Close Action" option which I believe was the GUI add on related to the bug reported 9767 in the link above. The last change was to push both phase 1 and 2 timeouts to 28800 to match, this seems to have finally given me a bit longer before the tunnel is completely down and I have to manually disable/enable to get things going again.
Quote from bug report
I have been able to sort of work around this with closeaction=restart but then it always keeps two instances of the child SA open if both sides initiate. Might need a GUI option to control that, and then only set it on one side (like setting one side responder only)Regards,
Adam Tyler -
VTI can't use traps, since traps are for policy-based IPsec, so that log message is expected and normal.
The only way to keep VTI tunnels up is by setting the child SA close action on one side to reconnect. Do not set it on both or it will always hold two open as that note says. Even if it does hold just two open, that's not fatal, and still better than none open.
-
@jimp Good morning, thanks for your reply. As stated in my original post, I tried just about every settings combination that's available. The key change that seemed to finally get things stable was to set both phase 1 and phase 2 lifetime to match. I currently am using 28800. Before phase 1 was set to 86400 and phase 2 was set to 3600. These timeout settings have been reliable for me on other routing equipment, but in the case of this experience the tunnel was up and down all the time regardless of any other adjustment.
My guess as to why this worked, is that it forces the entire tunnel to renegotiate rather than phase 2 alone on a shorter interval. I know prior to this change, when the tunnel was misbehaving, the act of disabling and enabling it resolved the problem for a time.
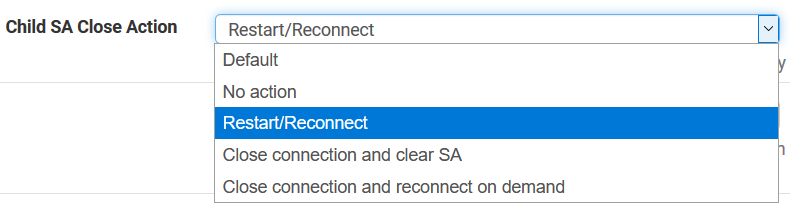
Currently I have the "Child SA Close Action" set to "Restart/Reconnect" set at both ends. You are saying that only one side should be set for "Restart" and the other at "Default"?
Right now both ends are set up to initiate the tunnel if that matters at all. Ie.. This setting is not checked.

-
Your P1 and P2 lifetimes should not match, as that is more likely to cause you problems. P2 lifetime should be shorter than P1.
Only one side should be set to restart the child SA.
And ideally only one side should be initiator.
So set one side to responder only and set that same side to close/clear the child SAs.
After making these kinds of changes it's a good idea to stop and then start (not the restart button) the strongSwan service to ensure it's getting a fresh start.
-
@jimp Oh I get it, not making any sense. I originally built the tunnel with one side as the initiator and the phase 1 and 2 lifetimes being unique. Not sure why, but the current setup was the only combination that made the tunnel work consistently.