Complicated dynamic routing through remote gateways, having to reset state table.
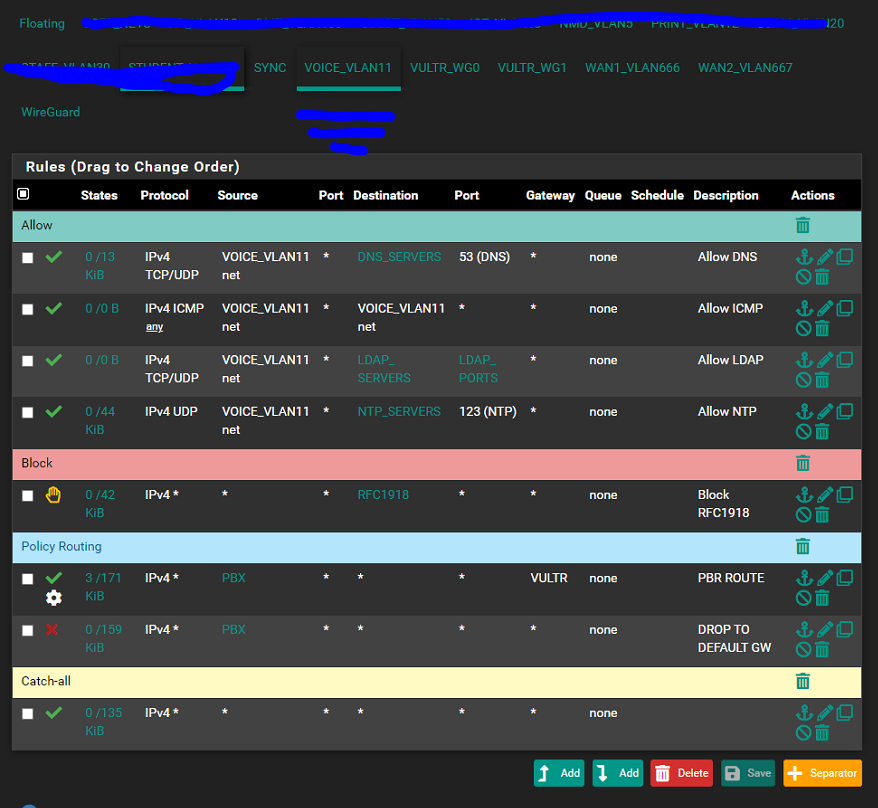
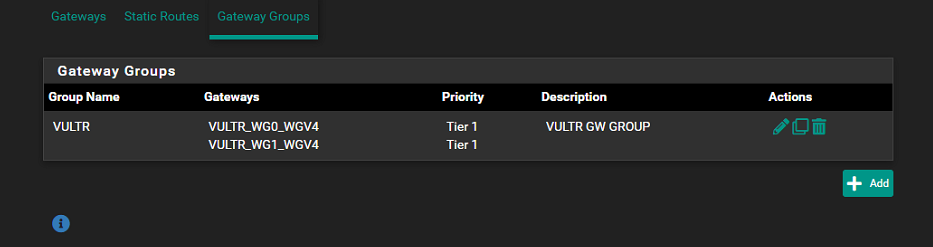
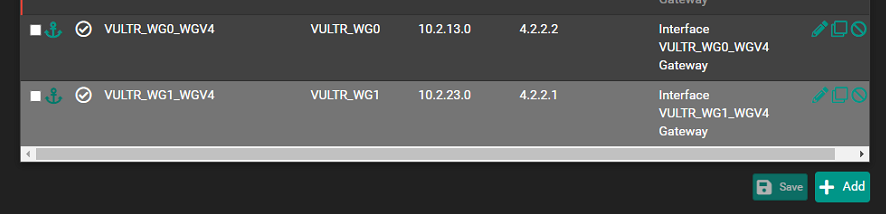
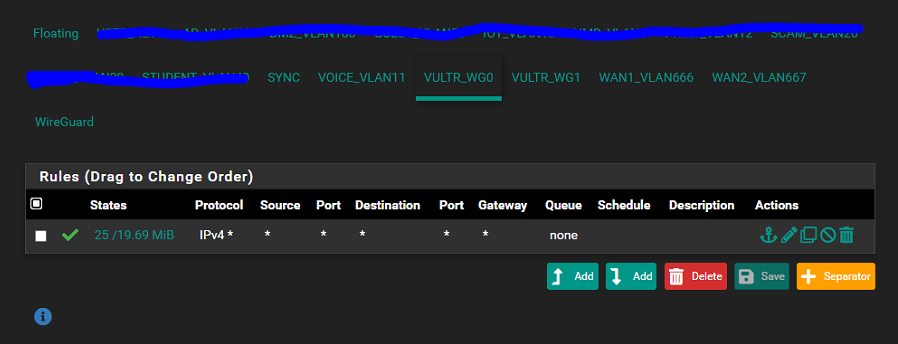
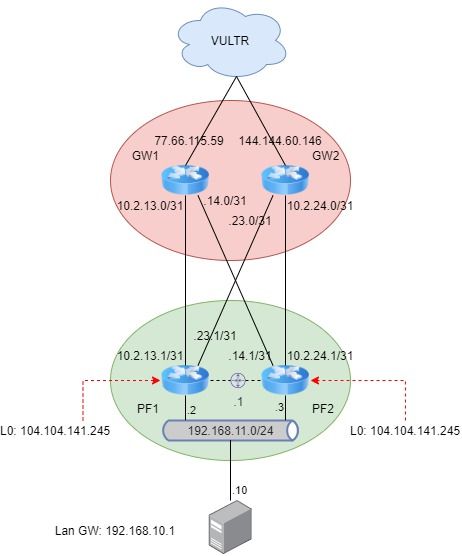
-
Well, I thought that disabling pfsync on these rules would fix the problem, but I'm still having to reset the state table after every failover. Also interesting to note that FreePBX begins to rate-limit and eventually BAN remote endpoints due to successive unsuccessful registration. So, inbound traffic works during the failover, and anything TCP related works fine in both directions as-is (i.e. I can still hit the admin GUI for the pbx, etc.). So something is dinking the outbound udp traffic until a state reset occurs, and by that time fail2ban on FreePBX has likely banned the endpoint due to successive unsuccessful registration.
I decided to test without a gateway group and explicitly pass inbound traffic through GW1 and outbound traffic policy routed to GW1. Problem still remains
Any suggestions for troubleshooting this?
Edit: Can pfSync handle syncing between interfaces that live on different subnets. For example WG0 on PF1 is on 10.2.13.0/31 and WG0 on PF2 is on 10.2.14.0/31.
Edit2: Disabling the FreePBX software firewall and fail2ban doesn't fix it either...so traffic is getting mangled elsewhere. I shutdown one of the vultr nodes so that I only have one potential ingress/egress point and the problem still persists. It really seems like the traffic can't flow out towards Vultr after a failover without first resetting the state table. I see SIP registration attempts coming in from my remote phones but the server is unable to contact them. NAT port issue?
Edit3: I'm open for suggestions on how to accomplish what I'm trying to do, which is in essence an IPv4 tunnel broker service, so that on-prem services can have a static point of presence without me having to have static addresses allocated directly from my ISP, and this also allows for failing over between multiple ISPs because the wireguard transit can ride over either.
-
@vbman213
There is a lot of similarity between the problems we are having.
https://forum.netgate.com/topic/160875/routing-issue-related-to-dynamic-nature-of-openvpn-interface-i-think- State table ends up poisoned after a link failure
- Routing SIP traffic to public IP space in the cloud
The configurations are very different, but I suspect the same route cause. I believe that tunnel interfaces are dynamic - when links go down, interfaces go away, and that changes the routing table, and some traffic goes someplace that it shouldn't, which in turn establishes states which pins future traffic to bad destinations, even after the links come back up... at least I know that's what my problem is, but it sounds like you have the same or similar issue.
Keep in mind that all the filter and NAT rules are often use exactly once upon encountering novel traffic, which establishes states, then traffic which matches a state is simply allowed without rechecking any rules. So, you can gets states in there which contradict rules, and the states win... the rule says one thing, but you observe the traffic doing something different.
-
@tlum I believe you are correct. I believe I have mostly resolved my issue by disabling pfSync on the problematic rules and then manually clearing states on both the primary and backup multiple times to really ensure these problematic states aren't lingering. Once I do this, I am able to CARP failover between my primary and secondary without much trouble (albeit I have to wait at least the OSPF dead time for the new routes to reconverge, but this is expected because FRR is only running on the primary node).
I'm going to let this bake for a few days, but at this point I'm ready to go back to terminating my tunnels on a on-site vanilla debian/iptables/frr set (acting as a Wireguard shim, that I was using prior to pfSense supporting Wireguard natively), and this worked great because both pfSense nodes just saw a single VRR gateway so states were always valid on either pfSense node.
-
@vbman213
Just noticed we've been talking about your issue on my thread, so I'm moving the conversation back to where it belongs.
fail2ban is a log file parser which takes action according to rules based on what it finds. Generally, it's FreePBX/asterisk that logged the complaint, fail2ban is just reacting to that. So, you should be chasing down the reason for the complaint in the log that fail2ban is picking up on. For example, based on your description it sounds like this may be the rule that's firing?
^(%(__prefix_line)s|\[\]\s*)%(log_prefix)s No registration for peer '[^']*' \(from <HOST>\)$If that's not it, which one are you seeing?
-
@tlum Thanks for the info, I'm still mulling over it all.
I'm simplified things considerably...I've shutdown one of the two cloud instances so that I'm only focusing on the pfSense failover aspect. Also, I'm now doing the 1:1 NAT on the cloud instance instead of on pfSense. I was optimistic about this but it seems that this case still has issues as well with stale states. I'm really starting to think that this is an edge case that isn't currently being handled gracefully. Could my issue be unique to the Wireguard implementation?
-
@vbman213
I can pretty much guarantee you're hitting an edge case. In pfSense, the virtual interfaces can be problematic. Take my issue for example; this is educated speculation on my part, but I believe what happens when a tunnel goes down is the interface dynamically goes away. This will cause a problem for pf which probably won't let you reference interfaces which don't exist in rules, so, they had to come up with policy(s) to maintain valid rules in pf as interfaces on which the rules depend come and go.
While the reasoning is speculative, what I now know for sure is they will rewrite the rule without the reference to the gateway that is down, by default, which sends the traffic instead to the default gateway. I also now know, thanks to @vbman213, there is a checkbox which will cause it to drop the rule altogether instead of modifying it. In my case, neither policy would achieve the desired behavior, which is to actively fail the traffic - an ICMP destination unreachable would be nice - so I had to insert an additional rule to reject the traffic in the event the gateway was down and the preceding rule was removed.
So yea, something like that is probably going on. You need a reproducible test case, then you need to hang a network trace on it and capture the transition to failure mode. From that you'll expose the pfSense, or other behavior, which is problematic, and once you understand what it's doing you can usually devise a workaround.
Sometimes the packet logs are helpful, at least in suggesting what you need to look closer at. I'll usually temporarily log all traffic, pass and fail, on filters relevant to the traffic of interest. Sometimes you need to add rules to log traffic which is silently falling through and not hitting a log. Then it's just a matter of a before and after traffic pattern diff - does traffic suddenly start failing or get handled by a different rule? The log may or may not end up being inconclusive.
Ultimately, I usually end up, up in there with tcpdump and Wireshark following the SIP conversation. With the new setup I was actually running three traces and correlating them; one trace was looking at the voice DMZ subnet, another was looking at the tunnel interface, and the third was up in the cloud watching what was going in and out of the tunnel. The problem with a SIP conversation is you're looking at a "feedback loop" so it's easy to see when it breaks, but if you're only looking at a single point you really can't tell if the problem is egress or ingress, especially when the paths are long and complex. So, not only would I need to find the timestamp where it breaks, I'd need to look at a trace from each next hop and/or previous hop to see where the failure occurred. It's not really as bad as it sounds... just tedious.
-
So it seems that SIP UDP state issues has been an issue going back many years and it seems the solution is either use a routing platform besides pfSense or use TCP for SIP transport (UDP still for RTP).
-
@vbman213
Well, UDP state issues have been around since the advent of statefull firewalls, so it affects way more than SIP. UDP is a stateless protocol, so keeping state is a hack, at best. So, the more complex the interactions between the endpoints the more likely it is to run amok.
@vbman213 said in Complicated dynamic routing through remote gateways, having to reset state table.:
or use TCP for SIP transport
Why wouldn't you? It sounds like you don't, and you mention it as if TCP would be a sacrifice, so I'm not sure of your thoughts on this.
SIP benefits in many ways from TCP.
- It's used only for call setup and teardown - and out-of-band signaling if configured for it.
- The SIP protocol will be mostly silent during the call so the UDP states will usually have aged off and new UDP states need to be established for call teardown.
- The SIP protocol is statefull; if you use a "best effort" protocol like UDP then responsibility for reliability falls upon the application layer, whereas using TCP handles transport reliability in the transport layer.
- The statefull SIP protocol often runs multiple streams/conversations at once, with varying lifetimes. If you use UDP it becomes difficult for a "man in the middle" to differentiate the distinct streams, so you end up with state problems.
- The usual arguments for UDP don't apply here since SIP is a single, long lived stream, per call, so the connection overhead is negligible.
If you MUST use UDP for some reason I would turn off "keep state" (State type = none) in the SIP rules. You'll also need to add rules for the return traffic, I believe. This will eliminate any state problems, at the expense of every SIP packets having the pass the rule checks, in both directions. Since SIP is not very "chatty" the additional overhead wouldn't be much more than the TCP overhead.
- It's used only for call setup and teardown - and out-of-band signaling if configured for it.
-
@tlum thanks again for the valuable and much appreciated insight. I guess my only reservation about switching to TCP signaling was that UDP seams to be the vendor default on pretty much every handset on the planet...though that's a terrible excuse with automated provisioning etc.
Just for my own curiosity, how might I go about disabling state tracking on this traffic? What would the rule look like for return traffic? I understand setting that advanced setting to State = None, but that by itself understandably breaks traffic flow.
-
@vbman213
You'd have to look at the traffic. If s_port and d_port are always 5060 you could restrict the port in the rule, but often on the return trip the d_port will be some random port (the originating s_port), so port filtering will be impractical. In any event, you'd be filtering inbound on your providers IP address(es). And, now that I'm thinking about it I'm not sure how NAT will behave, if at all. I honestly wouldn't try it unless there really, really, really, wasn't any other choice and you had the time and patients to mess with it.
TCP, if you can use it, should enhance reliability and security. Trying not to keep state on UDP will cost you time, possibly degrade security, but maybe solve your issue without having to reconfigure clients. The right tools for the job are TCP for the SIP protocol, and UDP for the RTP streams. I'm not sure what the vendor rational is for UDP as a default... other than maybe using one protocol type for both use cases, and RTP over TCP would end badly.