Here's a crash dump...
-
Maybe I'm just neurotic, but I personally suspect there are enough of these pouring in to justify a dedicated forum category? I had to read the entire list about four times to decide my report belongs here. It's not exactly friendly. (Nor is uploading a crash dump to an extremely public forum to get any help deciphering what even failed on the system, but that's an entirely different story.)
Anyway, that rant aside (and I'm sure it'll never be read by folks who can actually do anything about it anyway), attached is my crash dump. What happened to my system that caused it to crash? This has been happening every few hours, which is frankly exhausting, and leaves me without Internet for upwards of 20 minutes at a time as the system reboots and tries to ensure it didn't just destroy its entire self in the process.
-
The important parts of that are the panic:
Fatal trap 9: general protection fault while in kernel mode cpuid = 0; apic id = 00 instruction pointer = 0x20:0xffffffff8109a4fa stack pointer = 0x28:0xfffffe001ef293c0 frame pointer = 0x28:0xfffffe001ef29850 code segment = base 0x0, limit 0xfffff, type 0x1b = DPL 0, pres 1, long 1, def32 0, gran 1 processor eflags = interrupt enabled, resume, IOPL = 0 current process = 12 (swi1: netisr 1) trap number = 9 panic: general protection fault cpuid = 0 time = 1634683680 KDB: enter: panicAnd the backtrace:
db:0:kdb.enter.default> bt Tracing pid 12 tid 100030 td 0xfffff800041fd740 kdb_enter() at kdb_enter+0x37/frame 0xfffffe001ef290d0 vpanic() at vpanic+0x197/frame 0xfffffe001ef29120 panic() at panic+0x43/frame 0xfffffe001ef29180 trap_fatal() at trap_fatal+0x391/frame 0xfffffe001ef291e0 trap() at trap+0x67/frame 0xfffffe001ef292f0 calltrap() at calltrap+0x8/frame 0xfffffe001ef292f0 --- trap 0x9, rip = 0xffffffff8109a4fa, rsp = 0xfffffe001ef293c0, rbp = 0xfffffe001ef29850 --- pf_test_rule() at pf_test_rule+0xeaa/frame 0xfffffe001ef29850 pf_test() at pf_test+0x2448/frame 0xfffffe001ef29ab0 pf_check_in() at pf_check_in+0x1d/frame 0xfffffe001ef29ad0 pfil_run_hooks() at pfil_run_hooks+0xa1/frame 0xfffffe001ef29b70 ip_input() at ip_input+0x475/frame 0xfffffe001ef29c20 swi_net() at swi_net+0x12b/frame 0xfffffe001ef29c90 ithread_loop() at ithread_loop+0x23c/frame 0xfffffe001ef29cf0 fork_exit() at fork_exit+0x7e/frame 0xfffffe001ef29d30 fork_trampoline() at fork_trampoline+0xe/frame 0xfffffe001ef29d30 --- trap 0, rip = 0, rsp = 0, rbp = 0 ---Neither of which are very revealing unfortunately.
The message buffer is completely spammed with link-local IPv6 warnings so we can't see what might have led up to that.
Is this the first time you're seen it crash?Steve
-
@stephenw10 Not even close. As mentioned in the original post, "This has been happening every few hours ... for upwards of 20 minutes at a time ..." Though a new development right after I posted was that it's now started locking up instead of outright crashing, leaving me with no further dumps to work with, and having to physically visit the router in question to perform a hard reset.
-
@danhunsakeWhen you're on site, isolate pfSense from any IPv6 harassment, by UN checking :
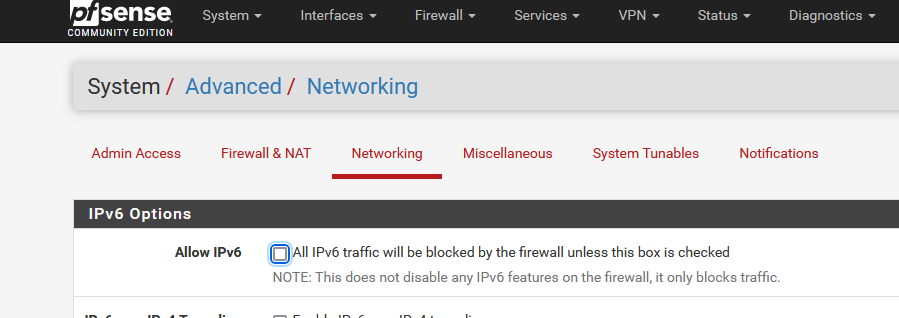
This will keep out the IPv6 traffic.
-
@gertjan I rely on the v6 traffic for some things, but for the purpose of tracking down this issue, I'll temporarily toggle that one.
-
@danhunsaker
The measure is not the fix, but just might help to see what's is the issue.
For example : if the issue is really 'IPV6' related, and if so, is a it local device, or pfSense itself, etc.The message buffer @stephenw10 mentioned could also be filled up because pfSense (FreeBSD) was stalling because it was 'close to dead' and thus not related.
"Not using IPv6" isn't the solution, of course ;)
-
Ah, sorry missed the repeated crashing in your original post. Do you have access to any further reports? Importantly does the backtrace look the same on them all?
Steve
-
No other crash logs in sight, at the moment. Unless they no longer live in
/var/crash. Finally got the dumb thing back up long enough to block IPv6 traffic so we can get a cleanerdmesglog the next time it actually creates a crash log. The new freezing behavior has become more common than full restarts, at this point, so I'm not sure how long it will be before we see a new log.
-
Locking completely with no crash report and unresponsive console starts to look like a hardware problem. Comparing old crash reports, and finding them all different, would confirm it if you could.
Steve