NRPE3 process 100% CPU load
-
Hi,
We run a CARP setup with two dedicated Xeon Servers and pfSense 2.5.1.
For HA there's a dedicated 1G copper link. Everything else is connected over 2 times 10G LACP. For every downstream interface there's a VLAN interface on top of that LAGG.
We're monitoring both nodes with Icinga2 and NRPE individually. We recently switched from Nagios to Icinga2 and also from IPv4 addresses to IPv6 addresses. The problem started occuring after this switch.Only the secondary device suffers from the problem that the NRPE3 process itself after a couple of minutes takes 100% CPU load. After some more time even more NRPE processes spawn, also with 100% CPU load. After few hours load goes higher than 5. Never waited much longer but I guess it's a neverending story.
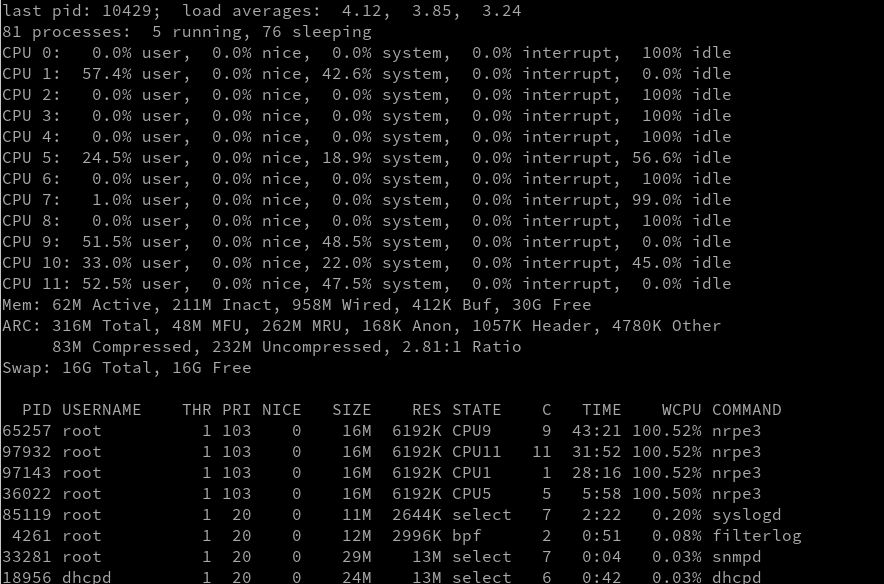
NRPE process looks like this:
nagios 36022 100.0 0.0 16144 6192 - R 13:40 7:27.85 /usr/local/sbin/nrpe3 -d -c /usr/local/etc/nrpe.cfgconfig file looks like this:
log_facility=daemon pid_file=/var/run/nrpe3.pid server_port=5666 nrpe_user=nagios nrpe_group=nagios allowed_hosts=2a00:1234:0:106::61 dont_blame_nrpe=0 debug=0 command_timeout=60 connection_timeout=300 command[check_users]=/usr/local/libexec/nagios/check_users -w 5 -c 10 command[check_load]=/usr/local/libexec/nagios/check_load -w 15,10,5 -c 30,25,20 command[check_root]=/usr/local/libexec/nagios/check_disk -w 20% -c 10% -p / command[check_var]=/usr/local/libexec/nagios/check_disk -w 20% -c 10% -p /var/run command[check_zombie_procs]=/usr/local/libexec/nagios/check_procs -w 5 -c 10 -s Z command[check_total_procs]=/usr/local/libexec/nagios/check_procs -w 150 -c 200 command[check_swap]=/usr/local/libexec/nagios/check_swap -w 50% -c 25% command[check_synclink]=/usr/local/libexec/nagios/check_ping -w 10,2% -c 20,5% -H 192.168.15.2 server_address=2a00:1234:0:16::3It looks like sometimes the icinga2 daemon gets a timeout when connecting to the nrpe process and it somehow looks like at that event a new nrpe3 process is being spawned.
I wasn't able to find anything related to that. -
Update:
It seems there is an asymmetric routing problem which leads to this phenomenon. TCP Sessions die because of that after 30 seconds. We will fix this by using a different IPv6 address for the check.Yet I believe this should never lead to the nrpe service going haywire.
-
You could be hitting the route-to/reply-to bug that was fixed in 2.5.2:
https://docs.netgate.com/pfsense/en/latest/releases/2-5-2.html#rules-nat
https://redmine.pfsense.org/issues/11805Though I agree the nrpe service should not behave like that. That's probably an upstream bug though.
Steve