Nmap results inconsistent over IPv6 through pfSense
-
I've spent a few hours trying to troubleshoot why our data center has been having trouble renewing or issuing Let's Encrypt certs the past couple of weeks. We have narrowed it down to IPv6 connections through our routers (pfSense 22.01) being inconsistent. For instance these nmap scans were run less than 2 minutes apart:
# nmap -Pn -6 -p80,443 2607:ff50:x:x::x:x Starting Nmap 6.40 ( http://nmap.org ) at 2022-04-20 15:28 CDT Nmap scan report for 2607:ff50:x:x::x:x Host is up (0.018s latency). PORT STATE SERVICE 80/tcp open http 443/tcp filtered https Nmap done: 1 IP address (1 host up) scanned in 1.39 seconds # nmap -Pn -6 -p80,443 2607:ff50:x:x::x:x Starting Nmap 6.40 ( http://nmap.org ) at 2022-04-20 15:30 CDT Nmap scan report for 2607:ff50:x:x::x:x Host is up (0.023s latency). PORT STATE SERVICE 80/tcp filtered http 443/tcp open httpsWe can replicate this behavior on all tested web servers of varying OSs in the data center. However when running nmap on a server across the data center LAN we can't get it to fail.
Similarly, I was pointed to the site letsdebug.net which is also inconsistent about whether it can connect on port 80 and/or 443 if we try it multiple times.
I generated the states below from an nmap that resulted in:
PORT STATE SERVICE
80/tcp open http
443/tcp filtered httpsWAN tcp 2001:470:1f11:233::2:2c09[58937] -> 2607:ff50:x:x::x:x[80] TIME_WAIT:TIME_WAIT 2 / 1 124 B / 64 B LAN tcp 2001:470:1f11:233::2:2c09[58937] -> 2607:ff50:x:x::x:x[80] TIME_WAIT:TIME_WAIT 2 / 1 124 B / 64 B WAN tcp 2001:470:1f11:233::2:2c09[58937] -> 2607:ff50:x:x::x:x[443] SYN_SENT:ESTABLISHED 1 / 2 64 B / 128 B LAN tcp 2001:470:1f11:233::2:2c09[58937] -> 2607:ff50:x:x::x:x[443] ESTABLISHED:SYN_SENT 1 / 2 64 B / 128 B WAN tcp 2001:470:1f11:233::2:2c09[58938] -> 2607:ff50:x:x::x:x[443] SYN_SENT:ESTABLISHED 1 / 2 64 B / 128 B LAN tcp 2001:470:1f11:233::2:2c09[58938] -> 2607:ff50:x:x::x:x[443] ESTABLISHED:SYN_SENT 1 / 2 64 B / 128 BI am confused why port 80 connects and 443 did not, and why does it sometimes flip so 443 connects and 80 does not, without any other changes. Does this indicate a problem with the router or just that the web server isn't responding. ESTABLISHED should mean the connection succeeded??
Any suggestions to diagnose the inconsistency?
The routers are in an HA config, though that shouldn't matter and I have flipped to the backup. They are running Suricata, but we have verified it isn't blocking and also stopped it. The firewall rules are not being changed during the test. The applicable firewall rule on WAN is to allow IPv6 TCP to any LAN IP on a port alias of Web (80,443).
-
I should note this started early in April. The only software updates to the servers in the data center were installed March 5 and April 15. So unless there weren't any Let's Encrypt certificates at all renewed March 5-31 or so, which seems awfully unlikely, that doesn't seem a likely cause.
I'm sure it can't be a pfSense "problem" but I don't know where else to look.
Edit: also worth noting, we have found no packet loss from pinging into or out of the data center.
-
@steveits I take it these scans were done from wan side of pfsense (internet), something else in the wan or wan side network.
I would sniff while you do your nmap tests, are the packets sent on by pfsense or not. This allows you to know its pfsense or not pfsense.
Packet seen coming into the wan, does pfsense send it on or not?
2001:470:1f11 is Hurricane - so this is through a tunnel?
Does the answer go back out the tunnel?
-
@johnpoz Nmap from the LAN side (inside) of the data center routers have not yet failed.
My example was me connecting out through HE but we tried a few other locations/ISPs. The data center doesn't use HE.
re: Packet capture, I get this:
PORT STATE SERVICE
80/tcp filtered http
443/tcp open https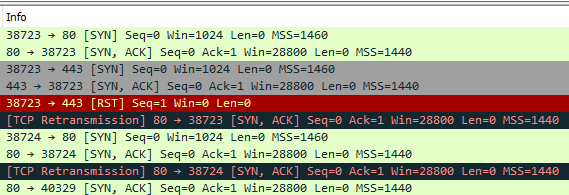
Aside from the retransmissions, I noticed Wireshark shows elapsed time of 2.61 seconds while nmap shows 1.40 seconds, and the timestamps in pfSense go from 20:52:02.826207 to 20:52:05.828249 which is 3 seconds? Does that mean nmap is giving up before the retransmission?
Then, what would cause the retransmissions? If I ping the server IP from my office (HE) PC I lost 2 packets (1%) and from my testing server (same office) with nmap I get no loss. From my home (Comcast) I have no packet loss. If I ping ipv6.google.com from the server I see no loss. Yet if I install nmap on my home PC I can duplicate the issue on the first try.
The one oddity with pinging is if I ping6 cnn.com (2a04:4e42:400::323) from the data center server I either get 0% loss or 100% loss, no in between...makes me think only some of their servers respond to pings? All the same IP but it might be a server farm or something.
Only install packages for your version, or risk breaking it. Select your branch in System/Update/Update Settings.
When upgrading, allow 10-15 minutes to reboot, or more depending on packages, CPU, and/or disk speed.
Upvote 👍 helpful posts! -
I kept digging at the pinging and suddenly couldn't ping to ipv6.google.com either. After another 45 minutes of pinging and tracerouting I'm opening a ticket with our data center. Something doesn't seem right but I suspect it is outside our equipment.
-
@steveits said in Nmap results inconsistent over IPv6 through pfSense:
80/tcp filtered http
Where exactly did you sniff that at? You can see the syn,ack sent - so was that on the lan side of pfsense, did that also go out the wan?
What you need to do to rule out pfsense is validate traffic is passed through. Pfsense has zero to do with if your server answers or not... But if syn come in wan, then it would send that out lan.
When syn,ack comes back into lan, it should send that out wan.
If that happens - then pfsense is not the problem.
-
@johnpoz The packet capture was on LAN, I was connecting from our office so through WAN.
I'm confident there's a subtle routing problem on the data center's side and I've bounced it to them. Ironically the Let's Encrypt cert for their own support portal expired overnight.
-
Just to follow up for posterity, the data center spent quite a while looking into it and overnight responded, "We have seen some random issues with VRRP after the replacement of one of our core devices several weeks ago. This seems to have been the culprit here. We have moved your IPv6 VRRP instance to a unique instance ID and this seems to have resolved the issue." We have not been able to reproduce any symptom today.
Thanks,
-
@steveits well that could explain it for sure - traffic takes path X works, takes path Y fail sort of thing.. Could be random for sure..
Thanks for the follow up - keeps those pesky curiosity kats from meowing at me ;)
-
@johnpoz Yeah I was just so into it being an inbound problem I didn’t test outbound for a while. D’oh! My assumption was the data center was good…
