HA randomly BACKUP goes to MASTER state
-
@m4rek11 I have the same problem. And it wasn't on version 2.5.x
In my opinion, the new 2.6 release broke something.
Router 1: No problems
Router 2:May 12 09:33:16 kernel carp: 130@em1.1030: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 160@em1.1060: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 11@em1.10: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 150@em1.1050: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 140@em1.1040: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 130@em1.1030: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 120@em1.1020: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 160@em1.1060: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 110@em1.1010: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 11@em1.10: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 14@em1.100: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 150@em1.1050: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 22@em1.500: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 140@em1.1040: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 10@em0: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 196@bce0.881: MASTER -> BACKUP (more frequent advertisement received) May 12 09:33:16 kernel carp: 120@em1.1020: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 110@em1.1010: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 14@em1.100: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 196@bce0.881: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 10@em0: BACKUP -> MASTER (master timed out) May 12 09:33:16 kernel carp: 22@em1.500: BACKUP -> MASTER (master timed out)I have been looking for the cause for some time, unfortunately still the same.
It is enough that on the main one I change something irrelevant for the second router, e.g. sending logs, Router 2 changes into a master for 1s. -
My UTM01 not showing any log about CARP like doing it UTM02, so we have the same behavior, I think. Another example about that strange situation is if I change anything what require "reload" firewall on UTM01 (MASTER) and of course after reload it, randomly UTM02 (BACKUP) change to MASTER for little short of time. I think it is exacly what you described.
One thing what I plan to test is to change network interface for UTMs in hipervior (Proxmox) from Virtio to e1000 and separate that VLAN that this interface is only for communication between HA.
If anyone has any other ideas, please let me known.
P.S. @przemyslaw85 Po Twoich postach widziałem, że też z Polski jesteś, ale że nie opisałem problemu w kategorii "Polska", więc po angielsku kontynuuje wątek. W każdym razie dziękuję za post z Twojej strony. Może uda się problem rozwiązać w końcu.
-
@m4rek11 I have a separate LAN port for Router1-Router2 sync.
It won't do much, but it is recommended that it be.
You also have the gateway monitor reset also on Router2?PS. W naszym dziale wieje nudą. Mało jest nas co korzysta z tego oprogramowania. Wiec tutaj się podłączyłem.
-
In the statistics for interfaces I see Error IN errors for Lan Sync.
Interestingly, the amount increases with these hops to Router 2.
I've already changed the server, network cards and ports. The problem persists. -
What do you mean about gateway monitor reset?
In my switch I don't see any packet errors about that vlan. Of course I made NIC chagnes in Proxmox, like I diescribed earlier, but problem still persist.
I'm very confused, why any changes that requires firewall reload causing (not always, but ofen) change MASTER to BACKUP and BACKUP to MASTER for a few seconds.
Maybe it is a pfSense bug?
-
@m4rek11 In earlier version 2.4.5 I saw sometimes (not always) that saving the rules from the firewall caused the change of one of several CARP interfaces from MASTER to BACKUP but it lasted a fraction of a second and did not cause any additional problems. This was only one, small issue with CARP I got with this older version.
This Saturday I installed version 2.6.0 CE and I noticed that just restarting one of the firewalls causes several minutes of "agreeing" who is MASTER and who is BACKUP - got similar logs as you and @Przemyslaw85
At first, I thought it is happening only when restarting one of 2 firewalls, because firewalls were working fine together for more than a day, but during the half of production day it happened again and do know why.Our firewall is two physical machines connected via two switches
-
-
@przemyslaw85 I also have Internet connection monitoring enabled. I found this discussion on https://redmine.pfsense.org/issues/12961 regarding CARP storm. I will try to play with this solution this saturday and see what will happen.
-
@Przemyslaw85, Im using monitoring system too and when the problem occuring lots of hosts (vlans) are not visible for a while within it.
@b_it, thank you for link, please, let us to known about your test.
-
@m4rek11 @Przemyslaw85 Sure I will. I hope that I will back with good news. Stay tuned
-
On last Saturday I added the two patches I mentioned in the previous comment and so far it looks much better. I don't see too many unnecessary messages, both firewalls are stable after these few days. Here are all the patches I added directly to mitigate CARP issue:
Fix CARP event storm when leaving persistent CARP maintenance mode 1/2
https://github.com/pfsense/pfsense/commit/8a906fba5e42d391227dfc39311d02b570576d50.patchFix CARP event storm when leaving persistent CARP maintenance mode 2/2
https://github.com/pfsense/pfsense/commit/3c15b353c6968801cfffb7d3b30a7069d2330a3e.patchduring patching Saturday I also manually added this one:
Fix Clicking Save & Force Update on a Dynamic DNS entry results in a GUI timeout
https://github.com/pfsense/pfsense/commit/bdffb77d1aa21770b23ef408ad9fba79d0825ec5.patchand I applied this three patches from recommended section:
Disable pf counter data preservation to temporarily work around latency when reloading large rulesets (Redmine #12827)Fix Captive Portal handling of non-TCP traffic after login (Redmine #12834)
Fix OpenVPN dashboard widget client termination (Redmine #12817)
to sum up: for now I will stay with 2.6.0 version with patches
-
@b_it I understand I have made changes for mode 1/2 and mode 2/2.
For mode 1/2 I have to do steps for server 1 or both. -
@przemyslaw85 I think that every node should have the same set of patches. So I patched first node, and than the second node.
this name is just my own convention name:
Fix CARP event storm when leaving persistent CARP maintenance mode 1/2
Fix CARP event storm when leaving persistent CARP maintenance mode 2/2For CARP issue the second patch is not going to apply without the first one. This the view from one node (the second has the same set o patches)
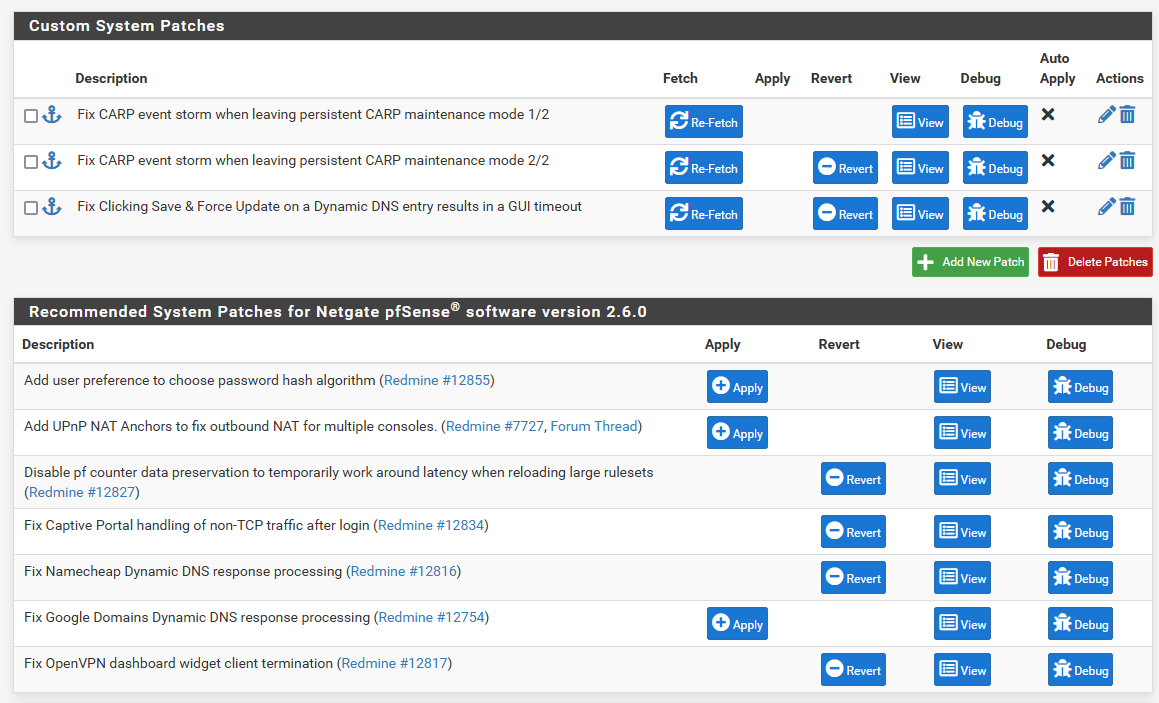
-
@b_it I confirm the operation of the patches.
Yesterday I made a few changes to the original files using the file editor. I didn't know there was such a module as patches. I had to revert to the original changes from a copy made before editing.
As I added 1/2 2/2 patches and Dynamin DNS I did not notice any improvement. Only after I added patches # 12827, # 12834, # 12816 and # 12817 I can say that now the system works as it should. -
@przemyslaw85 Seems to me that when I started to patch (CARP) I saw that firewall is more responsive making later changes (patching) but I didn't wait too long - just rebooted both nodes to be sure that all selected patches are fully applied.
I have to admit that I started to make more thorough tests after I rebooting FWs (with mentioned patch set), so I can't be sure what really helped and how much.
BTW; The patching mechanism was introduced around version 2.5, and I've already learned from his beginning that I have to be careful selecting patches. -
@Przemyslaw85, @B_IT, after that changes did you have carp storm in logs and that MASTER -> BACKUP, BACKUP ->MASTER change for little time?
-
@m4rek11 I am looking into logs I see that during applying patch there are some entries, but after patching I see only a few, and they all looks as they should (at least for me) and they have reason (eg. rebooted node). I wouldn't call them storm and definitely I don't see flipping MASTER - BACKUP entries now.
-
@m4rek11 After applying the patches, I did not notice that the routers changed the roles of Master-> Backup, Backup-> Master.
All the problems went with those when I made any changes to the rules, dns or DHCP.I found my configuration error early. For unknown reason, for 2 different networks I sent the same vhid for Virtual IP. But the problems were still there. After applying the patches, the problem was gone.