Netgate 2100 ARP problem after replugging WAN port
-
@somerino said in Netgate 2100 ARP problem after replugging WAN port:
The pfsense is still spamming ARP request, it never receives an answer, because the device with the IP: 192.168.70.4 is offline.
Yes, that's fine. If you have something referencing it in the config and pfSense is trying to send traffic to it, an internal DNS server for example, it will keep ARPing for it until it responds.
Steve
-
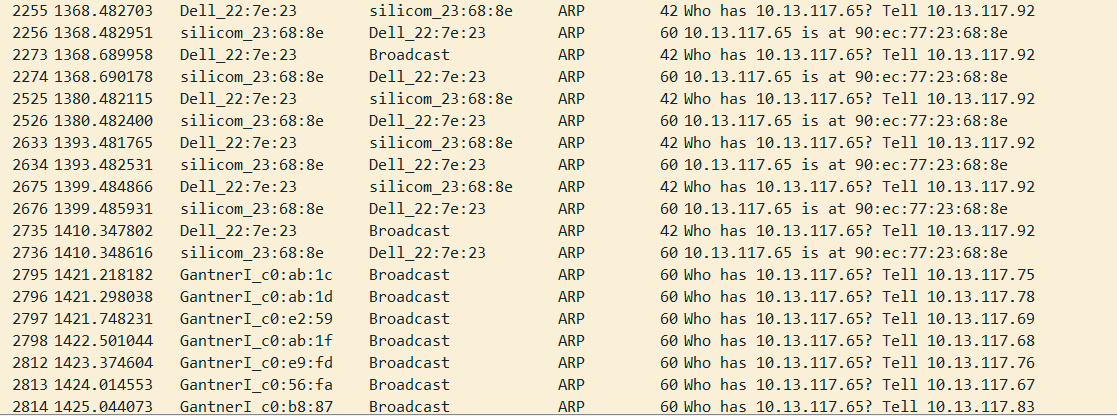
@somerino sorry for not understanding that this is a different system than the slow sonos system you were working with. The original arp scan and the most recent ones you posted look normal. Like stephenw10 has said. My personal system has 2 IoT controllers ARPing for devices I shifted to a different VLAN 3 weeks ago. You probably don't have a ARP problem but may have something else wrong with your Gantner equipment.
For your Gantner equipment failing to work after loss of connection on the wan port makes me wonder what kind of cloud or internet or VPN connection needs to be reestablished. I would look at its full normal communication all packets not just ARP.
For example I'm currently researching the packet process for the DIAL protocol for multiscreen casting. It seems to be a different flavor of ssdp upnp and mdns that Avahi and pimd don't resolve -
What I've noticed is that after plugging the WAN port back in. The OpenVPN service works, but it's in a half functioning state:
Sorry for the blurry picture the status says: "Waiting for response from peer"

But still it's shown online:

Most of the network still works in this state except my access readers (gantner). Only through manually restarting the VPN tunnel, the problems gets resolved and I can see traffic on the VPN status page.

I'm using the Peer To Peer (SSL/TLS) server mode and I really haven't experienced such an issue before upgrading the netgate 6100 (other end of the connection) to 22.05
-
Hei mike, I think you're right, it's not an ARP issue.
I've captured the traffic between the server and the gantner device and it literally only sends a phantom byte and closes the connection:

Even weirder, sometimes I can only see the tcp handshake without closing the connection.
The problem is so frustrating. I've mentioned below, that It might be VPN related. But I can't figure out, why everything else works through the VPN, except those gantner readers.
I've found a work-around by restarting the VPN manually. There comes the next problem. I've to do it everyday, because for some other silly reason, the VPN tunnel automatically restarts at night a few times.Jul 27 22:12:42 WHQ-FW01 check_reload_status[414]: Reloading filter Jul 27 22:12:43 WHQ-FW01 php-fpm[51938]: /rc.openvpn: Gateway, NONE AVAILABLE Jul 27 22:12:43 WHQ-FW01 php-fpm[51938]: /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use BUELACH_VPNV4. Jul 27 22:26:00 WHQ-FW01 sshguard[87099]: Exiting on signal. Jul 27 22:26:00 WHQ-FW01 sshguard[39533]: Now monitoring attacks. Jul 27 22:35:46 WHQ-FW01 rc.gateway_alarm[38160]: >>> Gateway alarm: BUELACH_VPNV4 (Addr:10.0.0.2 Alarm:1 RTT:32.705ms RTTsd:2.141ms Loss:22%) Jul 27 22:35:46 WHQ-FW01 check_reload_status[414]: updating dyndns BUELACH_VPNV4 Jul 27 22:35:46 WHQ-FW01 check_reload_status[414]: Restarting IPsec tunnels Jul 27 22:35:46 WHQ-FW01 check_reload_status[414]: Restarting OpenVPN tunnels/interfaces Jul 27 22:35:46 WHQ-FW01 check_reload_status[414]: Reloading filter Jul 27 22:35:47 WHQ-FW01 php-fpm[51938]: /rc.openvpn: Gateway, NONE AVAILABLE Jul 27 22:35:47 WHQ-FW01 php-fpm[51938]: /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use BUELACH_VPNV4. Jul 27 22:38:04 WHQ-FW01 rc.gateway_alarm[33071]: >>> Gateway alarm: BUELACH_VPNV4 (Addr:10.0.0.2 Alarm:0 RTT:23.979ms RTTsd:1.969ms Loss:5%) Jul 27 22:38:04 WHQ-FW01 check_reload_status[414]: updating dyndns BUELACH_VPNV4 Jul 27 22:38:04 WHQ-FW01 check_reload_status[414]: Restarting IPsec tunnels Jul 27 22:38:04 WHQ-FW01 check_reload_status[414]: Restarting OpenVPN tunnels/interfaces Jul 27 22:38:04 WHQ-FW01 check_reload_status[414]: Reloading filter Jul 27 22:38:06 WHQ-FW01 php-fpm[375]: /rc.openvpn: Gateway, NONE AVAILABLE Jul 27 22:38:06 WHQ-FW01 php-fpm[375]: /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use BUELACH_VPNV4.Jul 27 22:38:04 WHQ-FW01 rc.gateway_alarm[33071]: >>> Gateway alarm: BUELACH_VPNV4 (Addr:10.0.0.2 Alarm:0 RTT:23.979ms RTTsd:1.969ms Loss:5%) Jul 27 22:38:04 WHQ-FW01 check_reload_status[414]: updating dyndns BUELACH_VPNV4 Jul 27 22:38:04 WHQ-FW01 check_reload_status[414]: Restarting IPsec tunnels Jul 27 22:38:04 WHQ-FW01 check_reload_status[414]: Restarting OpenVPN tunnels/interfaces Jul 27 22:38:04 WHQ-FW01 check_reload_status[414]: Reloading filter Jul 27 22:38:06 WHQ-FW01 php-fpm[375]: /rc.openvpn: Gateway, NONE AVAILABLE Jul 27 22:38:06 WHQ-FW01 php-fpm[375]: /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use BUELACH_VPNV4. -
@somerino at this point I am unable to assist farther my knowledge of vpn connections is limited. You may want to repost this as a open vpn connections problems or change the thread title to get others to assist. Maybe stephenw10 can work with this new information and help
-
Do you have DCO enabled at the HQ end? Try disabling it again if so. There is a known issue some people are hitting with DCO where only the server side IPs are available and nothing beyond.
Steve
-
@stephenw10
I haven't activated this feature yet.
I just found out on a site note, that my ISP had maintenance work the last couple days. So this explains why the VPN tunnels had to reset.Still I can't find an answer, what the difference is between an automatic reset and manual reset of the tunnel.
-
This thread is already getting out of hand. It started with ARP went to Spanning-Tree, to TCP protocol, VPN and I hope it will find an end soon.
Thank you for your help so far. By the way, the sonos problem isn't solved yet, I'll comeback at it, after this :D
-
Hmm, you have clients logs leading up the 'stuck in pending' state?
-
@stephenw10 not more than this. This was the last time I've seen something related to the mentioned VPN tunnel in the logs.
I think it's the same error state as I mentioned in the original problem. By replugging the WAN port, I tear down the VPN tunnel unexpectedly for the functioning part of the tunnel.
After a while both sides try to reestablish the connectionClient Side
Jul 27 22:35:47 php-fpm 345 /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use HQ_TO_BUELACH_VPNV4. Jul 27 22:38:07 rc.gateway_alarm 1141 >>> Gateway alarm: HQ_TO_BUELACH_VPNV4 (Addr:10.0.0.1 Alarm:0 RTT:24.269ms RTTsd:1.975ms Loss:5%) Jul 27 22:38:07 check_reload_status updating dyndns HQ_TO_BUELACH_VPNV4 Jul 27 22:38:07 check_reload_status Restarting ipsec tunnels Jul 27 22:38:07 check_reload_status Restarting OpenVPN tunnels/interfaces Jul 27 22:38:07 check_reload_status Reloading filter Jul 27 22:38:08 php-fpm 99524 /rc.openvpn: Gateway, none 'available' for inet6, use the first one configured. '' Jul 27 22:38:08 php-fpm 99524 /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use HQ_TO_BUELACH_VPNV4Server Side
Jul 27 03:11:44 WHQ-FW01 php-fpm[41160]: /rc.openvpn: Gateway, NONE AVAILABLE Jul 27 03:11:44 WHQ-FW01 php-fpm[41160]: /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed its IP. Reloading endpoints that may use BUELACH_VPNV4. Jul 27 03:14:00 WHQ-FW01 sshguard[21891]: Exiting on signal. Jul 27 03:14:00 WHQ-FW01 sshguard[55980]: Now monitoring attacks. Jul 27 03:14:04 WHQ-FW01 rc.gateway_alarm[97993]: >>> Gateway alarm: BUELACH_VPNV4 (Addr:10.0.0.2 Alarm:0 RTT:26.625ms RTTsd:22.486ms Loss:5%) Jul 27 03:14:04 WHQ-FW01 check_reload_status[414]: updating dyndns BUELACH_VPNV4 Jul 27 03:14:04 WHQ-FW01 check_reload_status[414]: Restarting IPsec tunnels Jul 27 03:14:04 WHQ-FW01 check_reload_status[414]: Restarting OpenVPN tunnels/interfaces Jul 27 03:14:04 WHQ-FW01 check_reload_status[414]: Reloading filter -
There's only one client on that tunnel I assume?
With the server side assigned as an interface like that both sides reset when the link goes down because of the gateway failures. You might try disabling the gateway monitoring on the server side so it doesn't reset twice. There could be a timing issue.
Steve
-
@stephenw10 Yes it's a one client tunnel.
Can i disable it on the client side, I'd like to manage everything on one device.Thanks Steve
-
That's worth testing. It's far more common to have the client side assigned though. I wouldn't expect that to cause a problem.
-
I made the change you suggested. It improved the time it takes to reestablish the VPN connection, but I still have the "Waiting for response from peer" status on the server side.
(Client side is fine)I think I've figured out the cause of my problem:
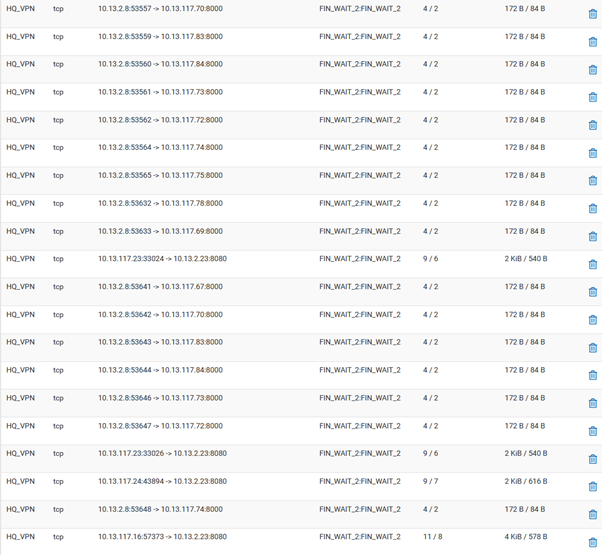
When the VPN tunnel breaks, some states remain in the FIN_WAIT_2 state, which won't allow a new tcp connection until it's been definitely closed.
Restarting the VPN tunnel kills the states and that's why it works as a solution.Is there any way to automatically kill these states after a certain amount of time?
-
You can set 'State Killing on Gateway Failure' to 'Kill states for all gateways that are down' in Sys > Adv > Misc. As long as you have a gateway defined there it should kill those states.
Or you can set the TCP state timeout dircetly in Sys > Adv > Firewall&NAT. That set's it globally though.
However you can see there are states there for duplicate connections with different source ports. So it would be possible for that to open another state using a new source port with the old states still present.Steve
-
@stephenw10
This makes it even more complicated.
So if it can create a new state, why doesn't it close the previous one.I don't get it, why it doesn't close the tcp connection at all. why does it keep getting stuck at FIN_WAIT2
-
That's normal for TCP states. They will close when the state times out but if the firewall doesn't see the full close sequence between the end points it won't immediately close them. I don't expect that to cause a problem though since a new state will be opened with a different source port and that will be unaffected by any existing states.
Steve
-
@stephenw10
I think you're right.
I've set the Firewalll Optimization to normal, which should've set the time out for "FIN WAIT" to 900 seconds, but it still doesn't kill the state.
So I guess back to the roots to find out what the problem is.EDIT
Well uhm, somehow it solved my problem automatically without restarting the VPN tunnel. I think the Firewall Optimization worked, need to do more testing though.