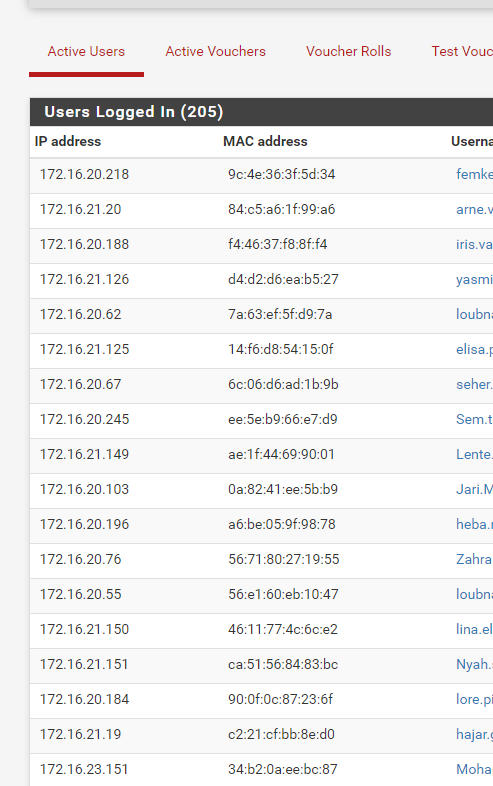
22.05 - CP clients have connectivity issues after x amount of time

-
Rotating, if teh file are small, can happen a lot => make the log files a lot bigger
Bzipping is optional. Really need it ? I've stopped that.You have a MAX (like me) after all, so space isn't really an issue (90 Gbytes or so ?)
The nginx log mostly contains the captive portal login page visits, these are a couple of line per visitor per login - and me when I visit the Dashboard / GUI etc.
You have that many lines ?Btw : not related to your issue, I know.
-
@gertjan
at around 3pm (15:00) this afternoon i've increased the nginx log to 5MB & increased the dhcp log to 2MB
this should reduce the number of log rotations.the default 500k nginx log would rotate approx every 3 minutes:
contents of nginx log is spammed with clients hotspot detection crap like this:
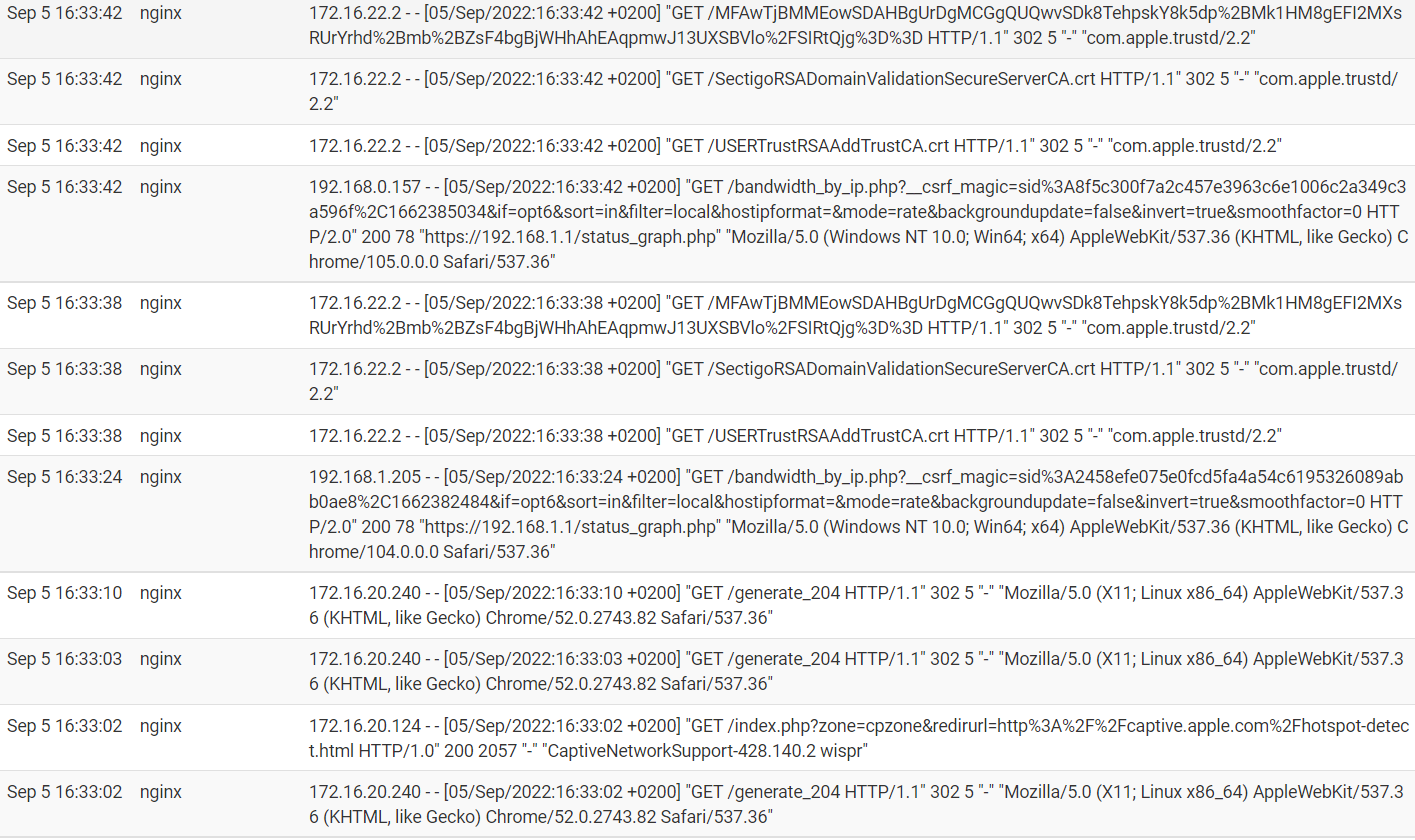
i will disable bzip. but i'm thinking the excessive hotspot_detection logging is a consequence of the connection issues the clients are having at random intervals. i doubt logrotating is the actual cause of the connection issues.
currently it's 6:45pm.
1 test-client is still connected to CP:
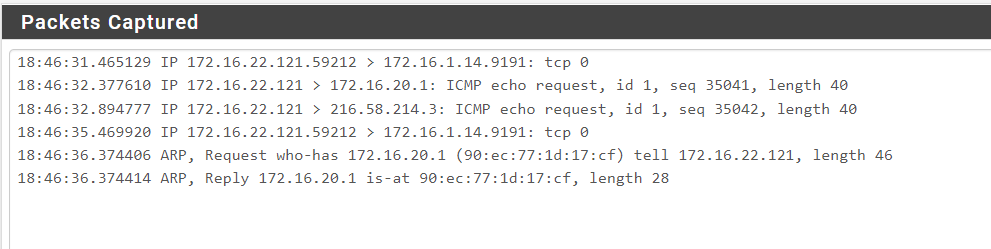
as seen above, there is no traffic flowing, not a single reply on any of the tcp or icmp requests. not even pfsense is responding to ping reply (172.16.20.1)1)status -> filterreload: situation remains the same.
-
status -> services -> captiveportal restart: situation remains the same.
-
services -> CP -> change idle timeout + save: situation remains the same
-
services -> CP -> change 'per-user-bandwidth-restriction' setting to anything different:
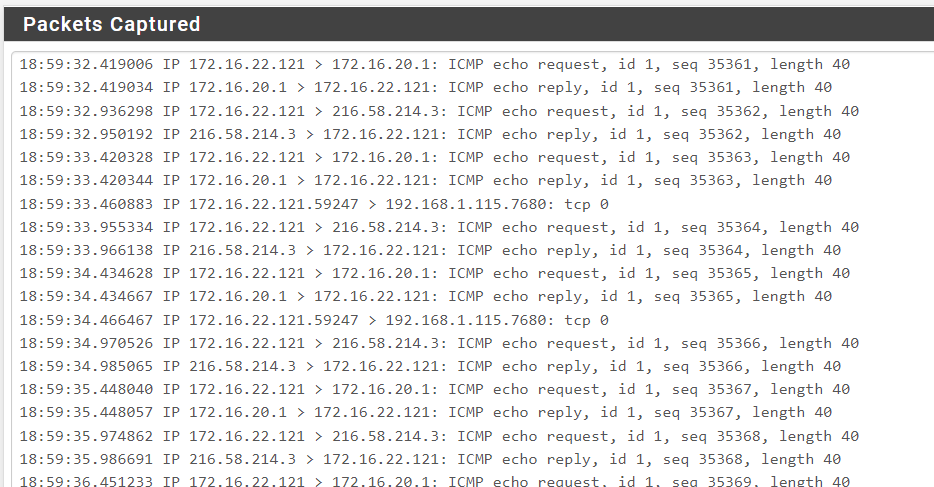
as one can see, tcp & icmp requests start getting replies again
still no clue how,when,why things stop working after some time. no even sure if there is a fixed interval.
hopefully someone can give me some debugging pointers
-
-
Can I assume you do not see either of these issues if per user bandwidth is not enabled at all?
Steve
-
@stephenw10
issue remains even when per-user-bandwidth is disabled.
it doesn't matter if it's enabled or disabled.everything starts working temporary when i make a change to the setting.
any change works:- disabling works
- enabling works
- changing the speeds works
all for x amount of time until it breaks down again
-
Hmm. And the number of connected clients doesn't make any difference?
Do existing states remain passing traffic? Just new connections fail?
-
@stephenw10
If number of clients increase - then issue returns more quickly.Some states seem to remain. At least for a while.
Traffic comes to a complete stop.Sometimes it fixes itself after a couple of minutes. Sometimes it stays 'stuck' forever
-
FYI this is likely related:
https://redmine.pfsense.org/issues/13150#note-16 -
@marcosm
That ticket might be related but I'm not using radius attributes for per-user bandwidth limiting.Also the problem occurs when disabling per-user bandwidth limiting all together.
But I do believe limiters are somehow involved.
At this point it is more of a gut feeling. I don't know how/where to read/interpret the realtime limiter-data to get to the bottom of this.Will try to gain more insight in the redmine you've posted
-
It definitely 'feels' like Limiters and all of that code changed in 22.05 with the removal of ipfw.
It's probably related to that ticket because it similarly pulls in the expected values when the rulset is reapplied.
Still looking into this...
-
i've found a fancy new party trick to be able to reproduce it on my system:
- disconnect a user from captiveportal by status->captiveportal
- All traffic for all users stop
- reconnect a different user to captiveporal
- traffic starts flowing again for all devices
- repeat this a couple of times to get the blood of users boiling
- create a screencapture
could not attach screencapture gif to this post (>2MB)
see here: https://imgur.com/a/GKCesgF -
If was about to ask about your point 2 : are you sure ?
Then I watched your movie .....
I'm pretty confident some will now know where to look. -
@gertjan
I hope someone will figure this out quickly...If not they'll burn me at the stake
-
You've said that a a save on the captive portal settings page made things flow again.
I mean, when you change your
3.reconnect a different user to captiveporal
for
3 save the portal settings
is the blood temperature going down ?
If I fabricate a small script that runs every minute that compares the list with connected users with the previous minute old list. If something changed, then the script executes a "captive portal save".
Just as a work around, for the time being.
-
@gertjan
just hitting save does not fix the problem.
i've mentioned this in one of the previous posts in this thread:-
status -> filterreload: situation remains the same.
-
status -> services -> captiveportal restart: situation remains the same.
-
services -> CP -> edit -> save: situation remains the same
-
services -> CP -> edit -> change idle timeout + save: situation remains the same
-
services -> CP ->edit -> change 'per-user-bandwidth-restriction' setting to anything different (doesnt matter if its enable / disable / change of speed) ==> FIXED
-
-
"Save" with a minor change (like change of speed from 10 to 12 Mbits or 12 to 10) => FIXED.
Ok - I work something out. -
with the information i've found today, the issue occurs on disconnect.
i'm currently running an experiment:
i wonder if backend code treats manual disconnects the same way as IDLE timeouts.
Because if the same "bug" is triggered by IDLE-timeouts that could explain the randomness i'm experiencing.So i've currently set the CP idle-timeout to blank
and i'll increase the dhcp leasetime to 8 hours or so to artificially prevent CP-clients from "disconnecting".will post results when i have them
preliminary results:
last 3 hours from 12:25pm -> now (3:10pm) i haven't noticed any more outages.
so it appears the workaround to disable idle-timeout & increasing dhcp-lease-time has a positive effect.
Schools out in less then an hour - so i will continue to monitor the situation on monday. -
Ah, that is a good discovery! Yeah, that has to narrow it down...
-
@heper said in 22.05 - CP clients have connectivity issues after x amount of time:
everytime when nginx.log gets rotated & bzip'd.
re: Bzip, is your 6100 running ZFS? If so you should turn off log compression:
https://docs.netgate.com/pfsense/en/latest/releases/22-01_2-6-0.html#general
"Log Compression for rotation of System Logs is now disabled by default for new ZFS installations as ZFS performs its own compression.Tip
The best practice is to disable Log Compression for rotation of System Logs manually for not only existing ZFS installations, but also for any system with slower CPUs. This setting can be changed under Status > System Logs on the Settings tab." -
@heper said in 22.05 - CP clients have connectivity issues after x amount of time:
i'm currently running an experiments
Not sure if I actually broke mine ....
Read from bottom to top :
2022-09-10 11:12:31.228623+02:00 logportalauth 77440 Zone: cpzone1 - ACCEPT: 001, 78:e4:00:1f:67:05, 192.168.2.122 2022-09-10 11:12:30.969566+02:00 logportalauth 77440 Zone: cpzone1 - Ruleno : 2008 2022-09-10 11:11:58.724810+02:00 logportalauth 54493 Zone: cpzone1 - ACCEPT: 203, 94:08:53:c0:47:63, 192.168.2.6 2022-09-10 11:11:58.462396+02:00 logportalauth 54493 Zone: cpzone1 - Ruleno : 2008 2022-09-10 11:07:22.560836+02:00 logportalauth 3105 Zone: cpzone1 - ACCEPT: x, ea:1a:04:4f:cc:a1, 192.168.2.6 2022-09-10 11:07:22.380192+02:00 logportalauth 3105 Zone: cpzone1 - Ruleno : 2008All portal clients get assigned the same '$pipeno' 2008 ? ?
What I understand :
My pipe numbers :
2000 (2001) For my "Allowed IP Addresses" 192.168.2.2 - an AP1" - no speed limits set
2002 (2003) For my "Allowed IP Addresses" 192.168.2.3 - an AP2" - no speed limits set
2004 (2005) For my "Allowed IP Addresses" 192.168.2.4 - an AP3 " - no speed limits set
2006 (2007) For my "Allowed Host Name" - no speed limits set " - no speed limits setso portal user get assigned pipe number 2008 (+2009); 2010 (+2011), etc.
note : I've added a log line in the function captiveportal_get_next_dn_ruleno() so the returned "pipeno" gets logged.
If a portal user gets delete and 'his' pipe '2008' (+'2009') get deleted, what happens with all the other user using the same pipe ?? ( I do have some ideas )
This also explained the horror video from @heper : all user are are clipped at a total 10 Mbits speed => because they all use the same pipe ?
Could it be that easy as that, a GUI issue ??
I've looked in my radius radacct (mysql table) where I have all my connected users activity : way back (using 2.6.0, not 22.05) I can clearly see that every user gets its own "rulenumber" is "pipeno".
True, I'm using FreeRadius so maybe I see smoke from another fire.
edit :
A script that dumps the content of the "captive portal connected user database" :
All user have the de same
[1] => 2008 [pipeno] => 2008#!/usr/local/bin/php -q <?php /* captiveportal_xxxxxx.php No rights reserved. */ require_once("/etc/inc/util.inc"); require_once("/etc/inc/functions.inc"); require_once("/etc/inc/captiveportal.inc"); /* Read in captive portal db */ /* Determine number of logged in users for all zones */ $count_cpusers = 0; $users = array(); /* Is portal activated ? */ if (is_array($config['captiveportal'])) /* For every zone, do */ foreach ($config['captiveportal'] as $cpkey => $cp) /* Sanity check */ if (is_array($config['captiveportal'][$cpkey])) /* Is zone enabled ? */ if (array_key_exists('enable', $config['captiveportal'][$cpkey])) { $cpzone = $cpkey; $users = captiveportal_read_db(); foreach ($users as $user => $one) print_r($one); } ?> -
@gertjan said in 22.05 - CP clients have connectivity issues after x amount of time:
Could it be that easy as that, a GUI issue ??
i doubt it's a gui issue.
because currently i'm under the impression that i might be hitting the same issue:- with or without per-user-bandwidth enabled (i guess when disabled, everyone gets added to the same unlimited pipe-pair?)
- with manual disconnect on gui
- when CP-client triggers the idle-timeout
on monday i'll resume testing & will try to create some sort of flow-chart (IF x then y | IF a then b)
- with or without per-user-bandwidth enabled (i guess when disabled, everyone gets added to the same unlimited pipe-pair?)