22.05 - CP clients have connectivity issues after x amount of time
-
TLDR: https://redmine.pfsense.org/issues/13488
Hi,
this summer i've migrated the config of a VM --> NG6100-max & updated to pf plus 22.05.
CP-authentication is done by radius(NPS) in a MS AD environment. afaik no accounting or quota's are being used.all appeared to work fine until the schoolyear started yesterday & captiveportal users complained about extremely slow WiFi. (only students & guest are on a CP-vlan). All other VLAN's, wired and wireless worked fine & no issues of "slowness"/timeouts/packetloss were found.
/------------------------------------------------------------------------/
when checking the traffic graphs of the last 24h's i've noticed that there wasn't a single moment that more then 20Mbit/s was being used on the entire CP-vlan. (with over 200 CP-users authenticated at any time during school-hours)
Connecting a new client to the CP-vlan it took minutes before the CP login page loaded. ping's to CP-vlan-ip had timeouts or rtt of over 800ms. (even when connecting by cable on an untagged port on the CP-vlan).
when investigating i found this:

I personally can not make much sense interpreting of diagnostics-->limiters. No clue what to look for exactly.
When i increased the per-user bandwidth field, traffic for all CP-vlan clients started to flow again. no more timeouts or high pings.
So for some reason the 'per-user' limit is acting as a global limiter for all the CP-vlan clients. Clients are NOT double-natted (that would also cause the same behaviour):
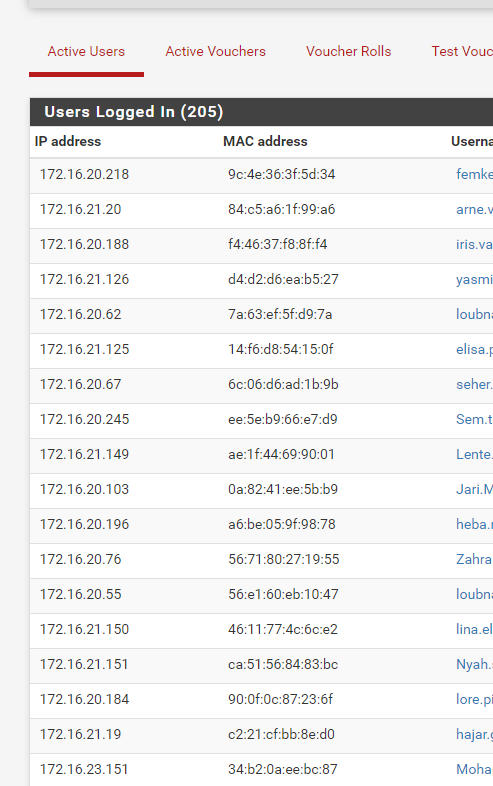
anyone else have the same problem? (@gertjan tested this & it worked fine in his test-setup)
anyone have a clue how i can start to diagnose / debug this issue?
-
increasing the per-user bandwidth appear to be a temporary fix. The problem returns after some time. not sure yet how much time
i had a CP-client connected overnight.
this morning i checked remotely and found that the client had a few existing states, but no new states could be created.
(i don't have remote access to the client, only pfsense)when looking at packet captures on the CP-vlan i found this:

client is trying to contact the DNS-server (= in CP-allowed ip's), but is getting no reply.packets don't arrive at 172.16.1.15 (i did a packet capture on that vlan to confirm this).
i edited CP settings and disabled Enable per-user bandwidth restriction & clicked 'save'.
The client instantly regained the ability to communicate:

also, the diagnostics->limiter info changed:
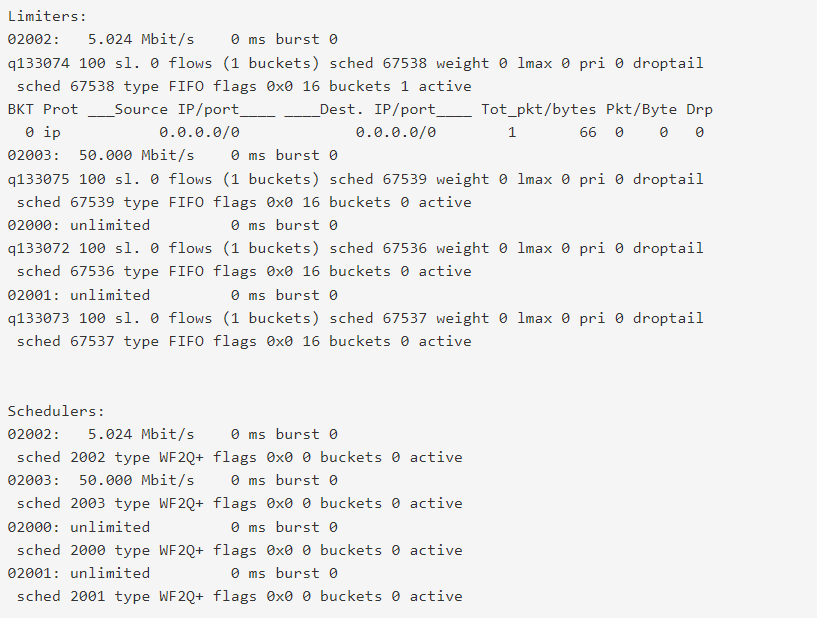
the 50mbit / 5mbit limit was probably the setting that was active when the client initially connected ???
when i'm on site on monday i'll resume my quest to gather information.
for now i "feel" like the automatically generated limiters get "stuck" after a while.
please guide me to provide more useful information.
-
problems persist. no clue how to debug. please advise
packet capture when broken:
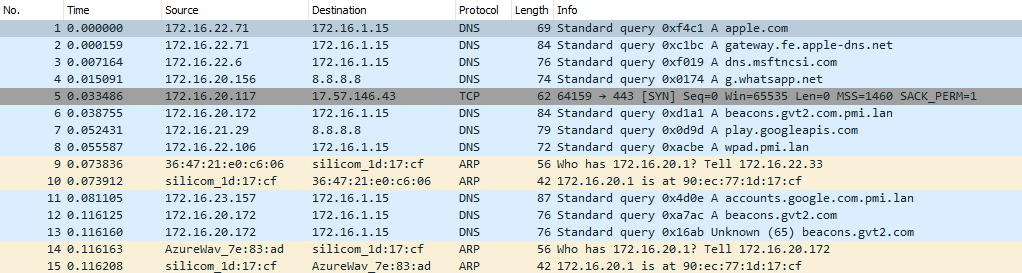
diag->limiter info when broken:
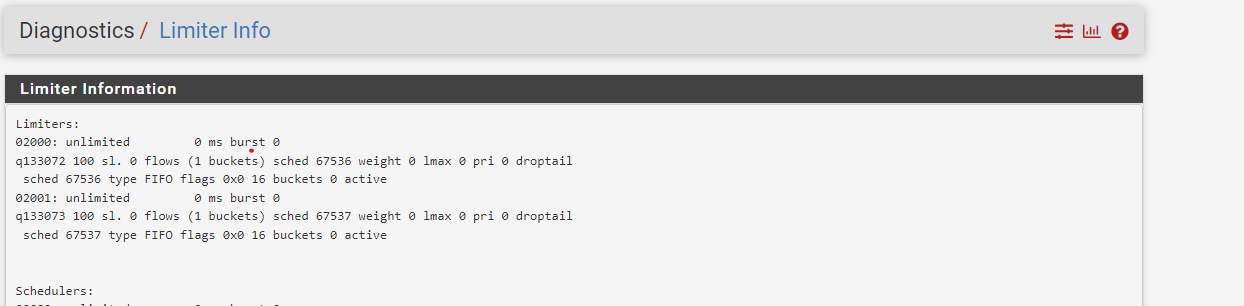
editing CP, check "Enable per-user bandwidth restriction" => save
edit CP, un-check "Enable per-user bandwidth restriction" => save
portal starts working againpacket capture afterwards:
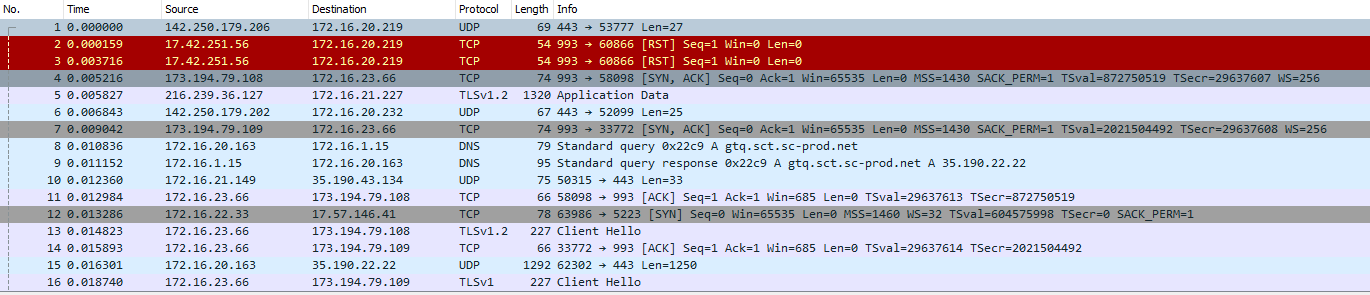
limiter info afterwards:
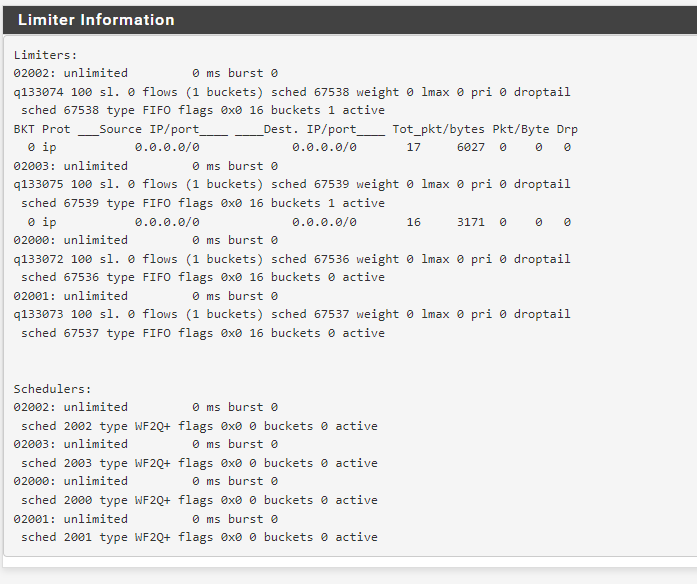
so for whatever reason shit gets fucked.
please advise how to debug. sorry to tag you @stephenw10additional info:
just started noticeing around 20 seconds of lost pings/downtime on the entire CP-vlan everytime when nginx.log gets rotated & bzip'd.
will check if this is somehow related. nginx log gets rotated every 5 minutes or so because of CP requests(update 2): it happened again around the time the dhcpd log rotated .
-
Rotating, if teh file are small, can happen a lot => make the log files a lot bigger
Bzipping is optional. Really need it ? I've stopped that.You have a MAX (like me) after all, so space isn't really an issue (90 Gbytes or so ?)
The nginx log mostly contains the captive portal login page visits, these are a couple of line per visitor per login - and me when I visit the Dashboard / GUI etc.
You have that many lines ?Btw : not related to your issue, I know.
-
@gertjan
at around 3pm (15:00) this afternoon i've increased the nginx log to 5MB & increased the dhcp log to 2MB
this should reduce the number of log rotations.the default 500k nginx log would rotate approx every 3 minutes:
contents of nginx log is spammed with clients hotspot detection crap like this:
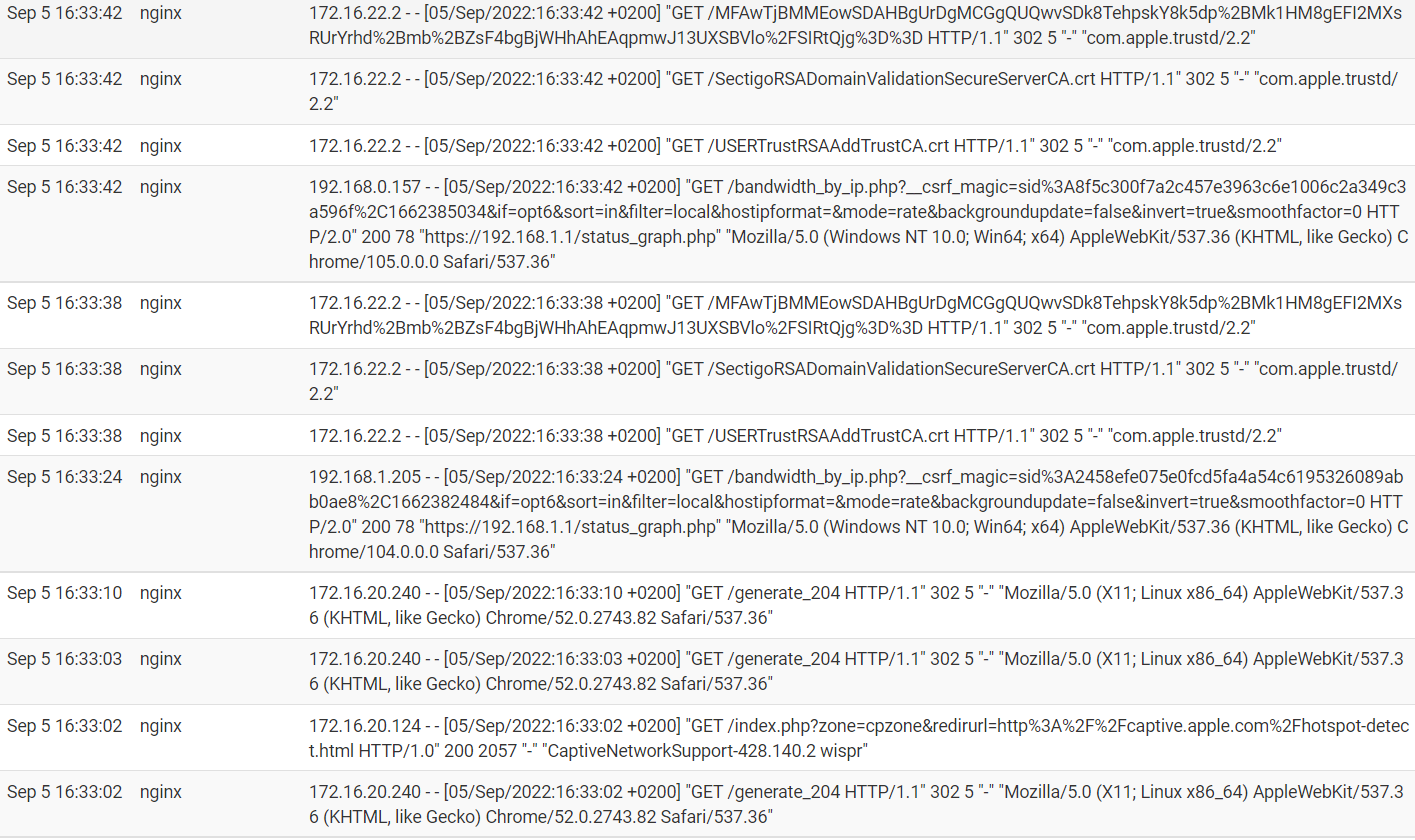
i will disable bzip. but i'm thinking the excessive hotspot_detection logging is a consequence of the connection issues the clients are having at random intervals. i doubt logrotating is the actual cause of the connection issues.
currently it's 6:45pm.
1 test-client is still connected to CP:
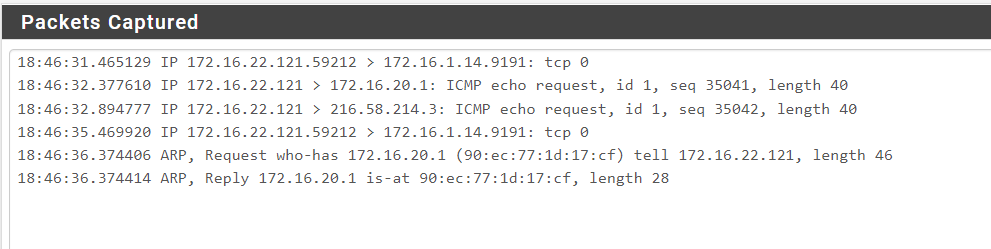
as seen above, there is no traffic flowing, not a single reply on any of the tcp or icmp requests. not even pfsense is responding to ping reply (172.16.20.1)1)status -> filterreload: situation remains the same.
-
status -> services -> captiveportal restart: situation remains the same.
-
services -> CP -> change idle timeout + save: situation remains the same
-
services -> CP -> change 'per-user-bandwidth-restriction' setting to anything different:
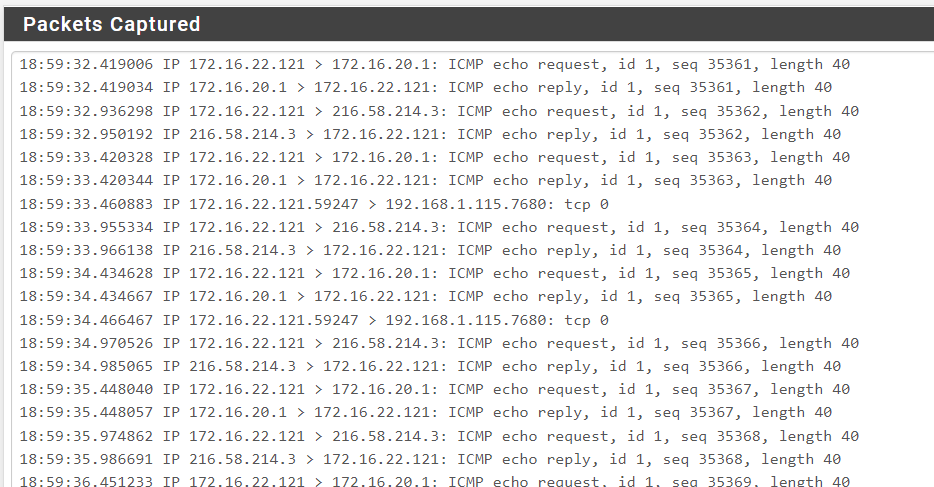
as one can see, tcp & icmp requests start getting replies again
still no clue how,when,why things stop working after some time. no even sure if there is a fixed interval.
hopefully someone can give me some debugging pointers
-
-
Can I assume you do not see either of these issues if per user bandwidth is not enabled at all?
Steve
-
@stephenw10
issue remains even when per-user-bandwidth is disabled.
it doesn't matter if it's enabled or disabled.everything starts working temporary when i make a change to the setting.
any change works:- disabling works
- enabling works
- changing the speeds works
all for x amount of time until it breaks down again
-
Hmm. And the number of connected clients doesn't make any difference?
Do existing states remain passing traffic? Just new connections fail?
-
@stephenw10
If number of clients increase - then issue returns more quickly.Some states seem to remain. At least for a while.
Traffic comes to a complete stop.Sometimes it fixes itself after a couple of minutes. Sometimes it stays 'stuck' forever
-
FYI this is likely related:
https://redmine.pfsense.org/issues/13150#note-16 -
@marcosm
That ticket might be related but I'm not using radius attributes for per-user bandwidth limiting.Also the problem occurs when disabling per-user bandwidth limiting all together.
But I do believe limiters are somehow involved.
At this point it is more of a gut feeling. I don't know how/where to read/interpret the realtime limiter-data to get to the bottom of this.Will try to gain more insight in the redmine you've posted
-
It definitely 'feels' like Limiters and all of that code changed in 22.05 with the removal of ipfw.
It's probably related to that ticket because it similarly pulls in the expected values when the rulset is reapplied.
Still looking into this...
-
i've found a fancy new party trick to be able to reproduce it on my system:
- disconnect a user from captiveportal by status->captiveportal
- All traffic for all users stop
- reconnect a different user to captiveporal
- traffic starts flowing again for all devices
- repeat this a couple of times to get the blood of users boiling
- create a screencapture
could not attach screencapture gif to this post (>2MB)
see here: https://imgur.com/a/GKCesgF -
If was about to ask about your point 2 : are you sure ?
Then I watched your movie .....
I'm pretty confident some will now know where to look. -
@gertjan
I hope someone will figure this out quickly...If not they'll burn me at the stake
-
You've said that a a save on the captive portal settings page made things flow again.
I mean, when you change your
3.reconnect a different user to captiveporal
for
3 save the portal settings
is the blood temperature going down ?
If I fabricate a small script that runs every minute that compares the list with connected users with the previous minute old list. If something changed, then the script executes a "captive portal save".
Just as a work around, for the time being.
-
@gertjan
just hitting save does not fix the problem.
i've mentioned this in one of the previous posts in this thread:-
status -> filterreload: situation remains the same.
-
status -> services -> captiveportal restart: situation remains the same.
-
services -> CP -> edit -> save: situation remains the same
-
services -> CP -> edit -> change idle timeout + save: situation remains the same
-
services -> CP ->edit -> change 'per-user-bandwidth-restriction' setting to anything different (doesnt matter if its enable / disable / change of speed) ==> FIXED
-
-
"Save" with a minor change (like change of speed from 10 to 12 Mbits or 12 to 10) => FIXED.
Ok - I work something out. -
with the information i've found today, the issue occurs on disconnect.
i'm currently running an experiment:
i wonder if backend code treats manual disconnects the same way as IDLE timeouts.
Because if the same "bug" is triggered by IDLE-timeouts that could explain the randomness i'm experiencing.So i've currently set the CP idle-timeout to blank
and i'll increase the dhcp leasetime to 8 hours or so to artificially prevent CP-clients from "disconnecting".will post results when i have them
preliminary results:
last 3 hours from 12:25pm -> now (3:10pm) i haven't noticed any more outages.
so it appears the workaround to disable idle-timeout & increasing dhcp-lease-time has a positive effect.
Schools out in less then an hour - so i will continue to monitor the situation on monday. -
Ah, that is a good discovery! Yeah, that has to narrow it down...