SSD read/write - how long will it last
-
Hey everyone,
Does anyone have the details on how many reads/writes the ssds are supposed to have on the MAX units? I have a 6100 and as expected, Suricata just hammers the ssd with tons of writes.
I cant find any data on the spec sheet.SMART status is below
smartctl 7.3 2022-02-28 r5338 [FreeBSD 12.3-STABLE amd64] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Number: M.2 (P80) 3TE6 Serial Number: YCA12203170170376 Firmware Version: V20B09 PCI Vendor/Subsystem ID: 0x1bc0 IEEE OUI Identifier: 0x24693e Controller ID: 0 NVMe Version: 1.3 Number of Namespaces: 1 Namespace 1 Size/Capacity: 120,034,123,776 [120 GB] Namespace 1 Formatted LBA Size: 512 Namespace 1 IEEE EUI-64: 24693e 36ba029988 Local Time is: Fri Feb 3 18:53:04 2023 EST Firmware Updates (0x02): 1 Slot Optional Admin Commands (0x0006): Format Frmw_DL Optional NVM Commands (0x000f): Comp Wr_Unc DS_Mngmt Wr_Zero Log Page Attributes (0x03): S/H_per_NS Cmd_Eff_Lg Maximum Data Transfer Size: 256 Pages Warning Comp. Temp. Threshold: 70 Celsius Critical Comp. Temp. Threshold: 85 Celsius Supported Power States St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat 0 + 6.50W - - 0 0 0 0 5 5 1 + 5.80W - - 1 1 1 1 30 30 2 + 3.60W - - 2 2 2 2 100 100 3 - 0.0500W - - 3 3 3 3 5000 10000 4 - 0.0025W - - 4 4 4 4 5000 45000 Supported LBA Sizes (NSID 0x1) Id Fmt Data Metadt Rel_Perf 0 + 512 0 0 === START OF SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED SMART/Health Information (NVMe Log 0x02) Critical Warning: 0x00 Temperature: 59 Celsius Available Spare: 100% Available Spare Threshold: 1% Percentage Used: 3% Data Units Read: 7,935 [4.06 GB] Data Units Written: 12,477,847 [6.38 TB] Host Read Commands: 99,971 Host Write Commands: 285,963,709 Controller Busy Time: 6,392 Power Cycles: 23 Power On Hours: 3,301 Unsafe Shutdowns: 16 Media and Data Integrity Errors: 0 Error Information Log Entries: 0 Warning Comp. Temperature Time: 0 Critical Comp. Temperature Time: 0 Temperature Sensor 1: 83 Celsius Temperature Sensor 2: 59 Celsius Temperature Sensor 3: 59 Celsius Temperature Sensor 4: 61 Celsius Thermal Temp. 1 Transition Count: 1 Thermal Temp. 1 Total Time: 25290 Error Information (NVMe Log 0x01, 16 of 64 entries) No Errors LoggedFirewall: NetGate,Palo Alto-VM,Juniper SRX
Routing: Juniper, Arista, Cisco
Switching: Juniper, Arista, Cisco
Wireless: Unifi, Aruba IAP
JNCIP,CCNP Enterprise -
@michmoor you have written 6TB in 137 days (3300 power on hours)? That seems a bit crazy...
-
@johnpoz I’m not amazingly surprised. My new build last August hammered my new SATA drive with over 300GB of written data in a couple of weeks. I then bumped up RAM and went to a RAM drive for logging etc and since then have only got to 374GB total in 6 months.
-
@michmoor That seems crazy high. I know Netgate recommends SSD for several packages but we haven’t had an issue running Suricata on client routers without SSD. Log display often covers days to weeks. It’s all relative though so how do you have it configured and how much traffic? If on WAN it will scan and alert on everything before it gets blocked by the firewall.
Anyway the PCI vendor is Innodisk, not that it helps much without a model. SSDs are usually measured in “n” drive writes per day so a lower number of 0.5 is 64 GB per day. Total guesstimate. 1 dwpd would be 128GB. 6000/137=43.8 GB per day.
We also usually use RAM drives now but with that amount of logging it might not be feasible.
-
@steveits @johnpoz Thanks. So for the firewall rules, i do have logging enabled on every rule. Thats sent to syslog server and its needed for compliance. But i really feel the intensity of the writes came from Suricata. By default, it logs almost everything about a flow plus DNS/TLS.
So on your own boxes, what kind of reads/writes are you seeing?
-
@michmoor Ah, I do uncheck "Enable HTTP Log" which could make a big difference too. ("Suricata will log decoded HTTP traffic for the interface. Default is Checked.")
One router on CE has a spinning drive so doesn't log that info. It has this:
/var/log/suricata/suricata_em01532: ls -l total 2196 -rw-r--r-- 1 root wheel 334962 Feb 3 22:55 alerts.log -rw-r--r-- 1 root wheel 0 Nov 15 17:55 block.log -rw-r--r-- 1 root wheel 1242618 Feb 3 22:55 block.log.2022_1115_1755 -rw-r--r-- 1 root wheel 89352 Feb 3 18:23 sid_changes.log -rw-r--r-- 1 root wheel 576904 Feb 3 18:25 suricata.logand
Filesystem Size Used Avail Capacity Mounted on pfSense/ROOT/default 405G 804M 404G 0% / devfs 1.0K 1.0K 0B 100% /dev pfSense/home 404G 96K 404G 0% /home pfSense 404G 96K 404G 0% /pfSense pfSense/cf 404G 96K 404G 0% /cf pfSense/var 404G 164K 404G 0% /var pfSense/cf/conf 404G 5.2M 404G 0% /cf/conf pfSense/var/empty 404G 96K 404G 0% /var/empty pfSense/var/tmp 404G 96K 404G 0% /var/tmp pfSense/var/log 404G 120K 404G 0% /var/log pfSense/var/cache 404G 96K 404G 0% /var/cache pfSense/var/db 404G 372K 404G 0% /var/db tmpfs 512M 356K 512M 0% /tmp tmpfs 1.0G 45M 979M 4% /var devfs 1.0K 1.0K 0B 100% /var/dhcpd/dev pfSense/reservation 449G 96K 449G 0% /pfSense/reservationOn that one the 250 log entry page goes back to early December. Our data center is different, its 250 entries go back an hour or two.
I had looked at several Netgate routers with eMMC drives a while back and it was something reasonable like 10-20% for most, and they were not new, so I was not concerned. Plus we were enabling the RAM disk at the time.
For anyone curious here are Netgate's package vs. disk recommendations.
-
@steveits Nice link, I hadn't come across that page before.. While I get haproxy if actually with heavy use.. I use it for a hand full of users to access a couple resources now and then.. I think my emmc should be fine ;)
-
@johnpoz @SteveITS Thanks both of you. So reviewing the config history of this box i think i found the culprits
- Someone had ntopng running for a few days.
- Suricata had logging on multiple traffic types - http/dns/tls. This was me so im guilty. :)
Ok im not to concerned then about the usage on the disk. Thanks for the tip on the Enable HTTP Log @SteveITS . I'm thinking about disabling TLS logging as well. Maybe DNS. I already have unbound logging anyways.
-
@johnpoz said in SSD read/write - how long will it last:
written 6TB in 137 days
Agree that is a lot given the terabyte(s) written (TBW) rating for a SSD in that size range is probably 60 and 150 TB but probably last longer in practice https://www.ontrack.com/en-au/blog/how-long-do-ssds-really-last and https://www.ionos.com/digitalguide/server/security/ssd-life-span/
-
I was running pfSense Plus 22.05 and now 23.01 under Proxmox. SMART for my SSD shows roughly 40-50GB written per day. Some of that is write amplification due to nested ZFS but pfSense is still writing an insane amount per day.
There's not that much logging going on, it's a home internet connection. I don't use a IDS/IPS package. All I have installed is pfBlockerNG, acme, iperf, Status_Traffic_Totals, and System_patches. I am running a DNS resolver if that matters. I only see syslogd writing stuff every few seconds in top.
My Proxmox box is using a Samsung 980 which is relatively durable but I'd rather not thrash it needlessly either. Something is extremely inefficient in how it writes in pfSense.
Here is what the IO graph for pfSense looks like in Proxmox:
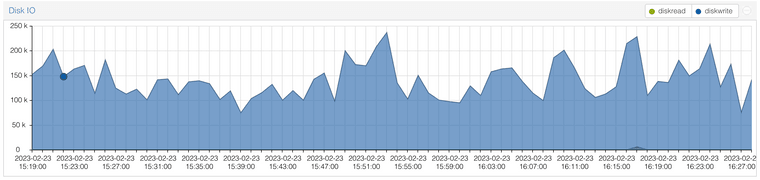
Here is zpool iostat output:
zpool iostat -y 1capacity operations bandwidth pool alloc free read write read write ---------- ----- ----- ----- ----- ----- ----- pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 87 0 1.16M pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 89 0 1.17M pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 97 0 2.21M pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 85 0 1.16M pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 91 0 1.20M pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 87 0 1.17M pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 86 0 1.12M pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 pfSense 3.53G 59.0G 0 0 0 0 -
@adriftatlas As noted above, if it’s logging then a RAM disk will help.
pfBlockerNG can be set to log DNSBL. PfSense logs the default block rule by default.
Could it be using swap? (Low on memory) -
It has 4GB of RAM and it's only using 33%.
I stopped the syslogd service temporarily and something was still writing to disk excessively so it's not the culprit.
This command shows zfskern writing a lot but what and why is it writing?
top -m io -o write -IS -d 1last pid: 97225; load averages: 0.17, 0.17, 0.14 up 2+20:53:44 20:25:57 80 processes: 2 running, 76 sleeping, 2 waiting CPU: 0.3% user, 0.1% nice, 1.2% system, 0.2% interrupt, 98.2% idle Mem: 89M Active, 191M Inact, 1383M Wired, 2166M Free ARC: 842M Total, 678M MFU, 91M MRU, 2298K Anon, 9317K Header, 59M Other 699M Compressed, 1473M Uncompressed, 2.11:1 Ratio Swap: 1024M Total, 1024M Free PID USERNAME VCSW IVCSW READ WRITE FAULT TOTAL PERCENT COMMAND 6 root 2207881 26057 313 1142462 0 1142775 82.97% zfskern 54361 root 35902 7684 313 151637 80 152030 11.04% php-fpm 359 root 34589 8604 111 76066 28 76205 5.53% php-fpm 14040 dhcpd 969664 20228 12 2585 20 2617 0.19% dhcpd 84008 root 3607 224 0 2060 0 2060 0.15% syslogd 358 root 36037 7802 54 400 35 489 0.04% php-fpm 82882 root 2927 152 0 353 0 353 0.03% php_pfb 18850 _dhcp 5303 182 0 287 0 287 0.02% dhclient 80651 root 235 53 0 216 0 216 0.02% vnstatd 3607 root 258782 7119 0 25 0 25 0.00% ntpd 98600 unbound 857611 289739 1 7 8 16 0.00% unbound 4737 root 14994 5587 71 4 2 77 0.01% nginx 38639 root 9 4 7 2 5 14 0.00% login 5065 root 4456 2591 4 2 1 7 0.00% nginx 80827 root 18 3 0 2 0 2 0.00% sh 4892 root 5399 2003 0 2 0 2 0.00% nginx 63231 root 18 3 0 2 0 2 0.00% sh 22895 root 282285 17201 0 0 2 2 0.00% filterlog 1 root 272 7 85 0 15 100 0.01% init 357 root 243687 8432 1 0 0 1 0.00% php-fpm 67497 root 3140 244 5 0 8 13 0.00% tcsh 397 root 626 182 1 0 4 5 0.00% check_reload_status 0 root 92073647 98734 42 0 0 42 0.00% kernel 41040 root 10 26 5 0 4 9 0.00% sh 62768 root 9323 597 2 0 9 11 0.00% sshd 83376 root 6 1 4 0 5 9 0.00% iperf3 38864 root 4 2 1 0 0 1 0.00% getty 2194 root 13892 1543 1 0 0 1 0.00% cron 42041 root 14 1 1 0 0 1 0.00% sh 66300 root 9007 859 0 0 2 2 0.00% qemu-ga 12509 root 10 1 1 0 0 1 0.00% sshd -
@michmoor If you look closelt in that report, it says %used = 3%
So there is lots and lots of life left in your SSD :-) -
@keyser you sure percentage used isn’t taking about disk space?
-
@michmoor said in SSD read/write - how long will it last:
@keyser you sure percentage used isn’t taking about disk space?
Well, pretty much 100%. The SSD itself cannot know how much diskspace the OS considers allocated and used - especially not if the OS does not support TRIM. Also, the S.M.A.R.T. Health tools always reports on the actual physical state of the SSD, not the filesystem state on the SSD.
-
@adriftatlas said in SSD read/write - how long will it last:
PID USERNAME VCSW IVCSW READ WRITE FAULT TOTAL PERCENT COMMAND 6 root 2207881 26057 313 1142462 0 1142775 82.97% zfskernWRITE is a counter, I believe? So it should increment forever. I pulled up a router on 2.6 with ZFS and see 5315859 (incrementing slowly) but that's 284 days of uptime. zfskern should include the ZFS scrub.
What does
iostat -xshow? On that same router, which is also using a RAM disk, I see:: iostat -x extended device statistics device r/s w/s kr/s kw/s ms/r ms/w ms/o ms/t qlen %b ada0 0 0 0.0 1.2 6 0 24 3 0 0 cd0 0 0 0.0 0.0 0 0 1 1 0 0 pass0 0 0 0.0 0.0 4 1 79 22 0 0 pass1 0 0 0.0 0.0 0 0 0 0 0 0 -
I would go with a small RaspBerry PI 3/4 with 2/4 GB and a
big mSATA or M.2 SSD with TRIM support as a logging server. -
extended device statistics device r/s w/s kr/s kw/s ms/r ms/w ms/o ms/t qlen %b da0 0 11 2.1 149.9 0 0 5 1 0 0 pass0 0 0 0.0 0.0 0 0 0 0 0 0I'd like to understand what is writing though. I'd rather not resort to using a RAM disk as it can cause other issues. There is no reason anything should be writing that much on a mostly idle router.
-
@adriftatlas The usual HUGE suspects are pfSense add-on packages (in order of typical write activity:)
1: Suricata
2: Snort
3: pfBlockerNG (especially with reply logging turned on)
4: NtopNGAll of them has measures to manually configure how much (or little) logging they actually do.
-
@adriftatlas Hmm yeah that’s 149x more. Not that I have a comparison handy.
Re:suspects, also any package mentioning SSD here:
https://www.netgate.com/supported-pfsense-plus-packages