Danger, Latency on WAN mildly loaded
-
Dear community,
Once again, I seek your expert guidance and advice on a recurring issue with my pfSense installation.
Overall, everything is fine and I experience very few issues with the platform. But this one is something I have no idea why happens:
Problem:
During load (windows updates, game downloads, etc.) between 200Mbps-1000Mbps, i have massive packetloss/latency errors and a non-functional internet basically. Of course at 1000Mbps I would be more accepting towards having a maxed out line, thus resulting in issues like this.I have no idea, why this happens or where the culprit is hidden. I tend to look towards my ISP and/or the modem just being bad at handling the traffic, but I'm not sure.
Any pointer or ideas, would be much appreciated. Please see attached screenshots.
Thanks
Jim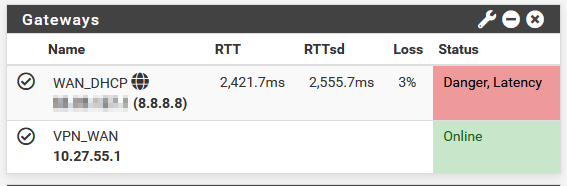
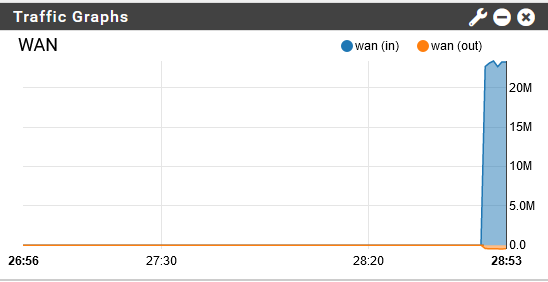

Specifications: - 1000/100 Mbps COAX WAN line, with SAGEM modem in bridge mode. - Qotom Dual-core i7-7500U CPU @ 2.70GHz / 16GB RAM / 256GB SSD / 6x1 Gbe - pfSense + 23.09-RELEASE (amd64) - Packages installed: acme arpwatch Avahi Backup Cron haproxy mailreport Notes openvpn-client-export pfBlockerNG-devel pimd RRD_Summary Service_Watchdog squid Status_Traffic_Totals System_Patches WireGuardBest regards
JimStill learning, correct me if I'm wrong please.
-
Could be a crappy modem. Could just be buffer bloat, though usually that doesn't drop packets like that.
Try an online buffer-bloat test first.
Steve
-
@stephenw10 said in Danger, Latency on WAN mildly loaded:
Could be a crappy modem. Could just be buffer bloat, though usually that doesn't drop packets like that.
Try an online buffer-bloat test first.
Steve
Hi Steve,
Thanks for your reply. I have tried the bufferbloat test, and it seems like that could be my culprit. Here's the result
How do I go about mitigating this issue in pfSense?
Thanks
Jim -
The only thing you can do in pfSense is to apply traffic shaping so that any buffering is done there where it can be controlled.
In situations where it's bad using CoDelQ can be quite effective:
https://docs.netgate.com/pfsense/en/latest/trafficshaper/altq-scheduler-types.html#codel-active-queue-managementI will point out that the 100ms shown in that test is far from the 2500ms seen by dpinger though.
-
@stephenw10 said in Danger, Latency on WAN mildly loaded:
The only thing you can do in pfSense is to apply traffic shaping so that any buffering is done there where it can be controlled.
In situations where it's bad using CoDelQ can be quite effective:
https://docs.netgate.com/pfsense/en/latest/trafficshaper/altq-scheduler-types.html#codel-active-queue-managementI will point out that the 100ms shown in that test is far from the 2500ms seen by dpinger though.
Thanks again, Steve. I will look into the traffic shaping, although it's never been needed before.
I'm also confused about the latency of the test, as it's nowhere near the problem depicted. Kinda lost as to where to start troubleshooting now.
/Jim
-
The route to the nearest 8.8.8.8 anycast host could be different to the test server so you might not be hitting the worst bloat there. I would try a few different test servers if you can.
-
Could be a crappy modem.
or how about just a crappy cable?
or wrong duplex being negotiated?
or wrong speed being negotiated?You won't potentially see the issue until you load it up.
-
@stephenw10 said in Danger, Latency on WAN mildly loaded:
The route to the nearest 8.8.8.8 anycast host could be different to the test server so you might not be hitting the worst bloat there. I would try a few different test servers if you can.
You mean changing my monitor IP for the gateway or doing bufferbloat test to another location, which I don't see as an option using the Waveform site?
@jrey said in Danger, Latency on WAN mildly loaded:
Could be a crappy modem.
or how about just a crappy cable?
or wrong duplex being negotiated?
or wrong speed being negotiated?You won't potentially see the issue until you load it up.
Thanks for your insight, jrey. You're right, sometimes it's the simplest things. I have checked the negotiated speeds and they're 1000Mbit full-duplex.
By cable I assume you mean the one going from the modem to the WAN port of pfSense, right? I understand that it could in theory be all cables, ranging from the one in my PC, to the installations in the attic and of course panels, switches, etc. OOF :)
Best regards
JimStill learning, correct me if I'm wrong please.
-
@jim82 said in Danger, Latency on WAN mildly loaded:
from the modem to the WAN port of pfSense
If you are seeing the problem on all clients (which it appears you are based on the gateway screen showing the packet loss) then yes, that cable.
might have been pinched, crimped whatever. doesn't hurt to just try a different one.
I had a streaming device at the house once upon a time that when I was on a cable provider never showed a problem. (the cable speed wasn't fast enough to push the limit anyway) However. when I switch to fibre at the house, the streaming device lost it, couldn't attain any real speed even though it should. J Just a speed test, it was limping bad.
Pull out the trusty cable tester, well darn a twisted / broken wire. Chopped off the end, crimped on a new one - issue resolved. No throttle required the device can now hit the limit of the network card with no jitter / packet drop etc -
so yup sometimes just a simple thing, like a cable. -
@jim82 said in Danger, Latency on WAN mildly loaded:
You mean changing my monitor IP for the gateway or doing bufferbloat test to another location
I meant test against some other speedtest server that reports latency under load. But changing the monitoring IP is also a good test here.
-
I have attached a "flent" graph I made from an ubuntu host. I'm not really sure if it's good, or bad?
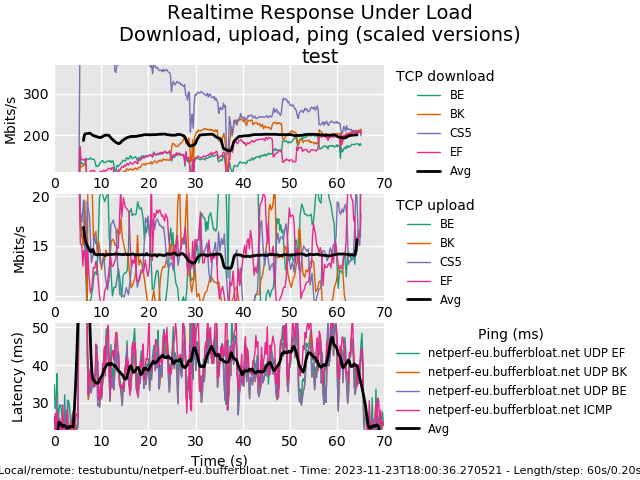
-
@jim82 Google is no longer a reliable target for latency/loss monitoring. They seem to have become cranky about people doing this, and have started dropping packets.
FWIW, I personally use a regional router inside my ISP for dpinger monitoring. I suggest using
traceroute -I 1.1.1.1to discover a suitable target. If you have multiple WAN interfaces, add the -s option to traceroute to ensure you are looking at the correct interface
For people who absolutely need a target beyond their ISP, I generally recommend Cloudflare (1.1.1.1) instead of Google.
-
go with stephenw10 suggestion
But changing the monitoring IP is also a good test here.
The trace route might reveal a lot.
I have never had a problem with 8.8.8.8 and would likely not pick 1.1.1.1 based on what is normal at my location.
of course in both cases, hops 1-3 are my gateway and my ISP - so hop 4 is where the fun begins.
so in my case pick up the trace route at hop4 first to 1.1.1.1
4 209.249.67.221.IDIA-251658-ZYO.zip.zayo.com (209.249.67.221) 14.524 ms 14.654 ms 14.438 ms 5 * * * 6 * * * 7 208.184.122.49.IPYX-330228-005-ZYO.zip.zayo.com (208.184.122.49) 15.811 ms 16.006 ms * 8 172.70.124.4 (172.70.124.4) 18.895 ms 16.237 ms 16.229 ms 9 one.one.one.one (1.1.1.1) 15.829 ms 15.918 ms 15.884 msthe above is pretty typical of things coming out of yayo going anywhere on their path 5 and 6 are pretty much always stars with no meat on the bones.
now pick up from hop 4 to 8.8.8.8 the ping time basically doubles from hop 3 to hop 4, pretty consistent typically anything inside my ISP is <2ms and jumps to 4ish at hop 4. "so I blame google"
4 google.ip4.torontointernetxchange.net (206.108.34.6) 4.254 ms 4.606 ms 4.395 ms 5 108.170.250.241 (108.170.250.241) 5.659 ms 5.508 ms 5.254 ms 6 216.239.35.233 (216.239.35.233) 5.358 ms 5.430 ms 5.000 ms 7 dns.google (8.8.8.8) 4.239 ms 4.606 ms 4.458 msI've not really noticed any specific throttle by google and have used them as the monitor IP for months. Of course this will vary by location. Drop a trace or two.
Day over day, month over month these are pretty typical results here.
-
@jrey said in Danger, Latency on WAN mildly loaded:
I have never had a problem with 8.8.8.8
I tend to hear about these issues. While you may not have experienced or noticed it, a number of people have run into issues with Google recently. I do not recommend using it as a target for monitoring.
-
@dennypage said in Danger, Latency on WAN mildly loaded:
While you may not have experienced or noticed it
So are you saying that if that is the gateway monitor is using 8.8.8.8 and has run into a problem, it wouldn't be logged.. That seems wrong.
that would imply that dpinger isn't noticing it, and we both know that's not the case.
Not saying I have never seen a drop or issue with google, just not in a very long time.
my last loss record in the log is
Aug 30 16:34:03 dpinger 29452 WANGWE 8.8.8.8: Clear latency 7182us stddev 19975us loss 5%and that wasn't really a "google" issue, that was the ISP tech guy playing outside LOL
My gateway hasn't dropped in months, and oh, it would be noticed 24/7 if not by dpinger as you seemed to suggest (JK) then numerous others would. On the other hand if I switch to 1.1.1.1 the gateway monitor will show lag and drop problems (mostly packet loss) constantly (even though the gateway is actually still up). Just look at the packet trace, not hard to figure out why.
Since the for IP addresses google uses 4 of them (2 ipv4 and 2 ipv6) for public are mapped to the nearest operational server by anycast routing, maybe the problem as you are hearing it, is just specific to locations experiencing latency.
The best recommendation is not one or the other, but rather something that works best at a given location. As you suggest something inside the local ISP would be best for a lot of users, I have two options hops 2 and 3, but displaying sub 2ms response times gets boring, so I opt for the 4ms choice inside google.
Google is not to my knowledge specifically throttling or blocking. I could ask. I'm well connected to a bunch of folks there. I can start the conversation with "So I hate google" Those friends always like that and then I end up buying a round. So on second thought - who cares right.
Pick what's best for your own situation and move on.
I'd like to comment on how simple it would be for dpinger to support a group monitor as has been suggested elsewhere today. But clearly there is no pressing need seen to add the feature and appears that it is already dead in the water. So moving on.
-
@jrey said in Danger, Latency on WAN mildly loaded:
So are you saying that if that is the gateway monitor is using 8.8.8.8 and has run into a problem, it wouldn't be logged.. That seems wrong.
I think it's pretty clear what I am saying: A a number of people have run into problems using Google as a target, and I do not recommend its use. That is all. Your mileage may vary.
-
@dennypage
I would think your local ISP would be your best test for your local (ISP) LAN leg all else you have no control over. I use and like QUAD9 for DNS. It is maybe a little slower, but it serves a purpose.
I would not use Cloudflare for anything. -
@coxhaus said in Danger, Latency on WAN mildly loaded:
I would not use Cloudflare for anything.
Just out of curiosity, why is that? While I strongly recommend against using any of the general public services for latency/loss monitoring, I have found Cloudflare to be the most reliable among the public services for small ICMP packets. Have you had a bad experience with Cloudflare and ICMP packets?
-
@jrey said in Danger, Latency on WAN mildly loaded:
Google is not to my knowledge specifically throttling or blocking. I could ask.
Just FYI, Google will throttle DNS queries when the QPS goes above 1500 QPS for a sustained period of time (multiple seconds in a row). Short bursts above that are permitted. A ping is not considered as a DNS query.
Of course the choice of which monitor IP to use always depends on location.
Out of curiosity do you happen to know which anycast addresses 1.1.1.1 uses by location?
I'd actually like to see if I can find out why 1.1.1.1 is such a flaming pile of .. from this location, short of the zayo.com hole noted above (which is consistent) we can't use it for anything (way to slow). It is not something I need to fix, just curious. the 8.8.8.8 anycast addresses (and there are 4 of those that apply to my location) is less than 100km on the end of the fibre.
The wan never actually dropped through any of this, however the alarm is pretty much constantly spewing this for 1.1.1.1
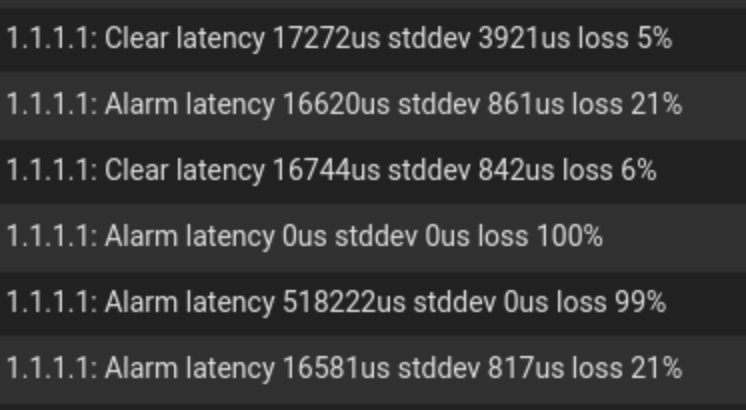
Thanks
-
@jrey Can you show traceroute info for 1.1.1.1 from your location? Both with and without -I.