"aws s3 cp" crashes the firewall when using squid web proxy
-
Netgate 3100
Happened in both 23.05 and 23.09.1
Squid 0.4.46Trigger:
export HTTP_PROXY=http://192.168.8.1:3128 export HTTPS_PROXY=http://192.168.8.1:3128 aws s3 cp --profile myprofile myfile.gz s3://mypath/myfilegz --grants read=uri=http://acs.amazonaws.com/groups/global/AllUsers --only-show-errors upload failed: ./myfile.gz to s3://mypath/myfile.gz HTTPSConnectionPool(host='mybucket.s3.amazonaws.com', port=443): Max retries exceeded with url: /myfile.gz?uploadId=2Np0o_30Su5ZrxamVzMYX.LQkPVMog7PupvQTUByny25FOXr7_9Jnz2cXvm0c3xxQ9I6qUPISyhwHhIc63lnlg0nzxiafHs93P_d8qJW3ImmEGyPO3GS0HXRDxcvclWp&partNumber=37 (Caused by ProxyError('Cannot connect to proxy.', ConnectionResetError(104, 'Connection reset by peer')))My 8GB file upload freezes after pushing about 500 MB of data.
Within an hour this results in a total crash requiring a power cycle, e.g:Dec 27 10:10:05 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached ---> MONITORING STARTED PICKING UP ISSUES Dec 27 10:14:16 netgate kernel: sonewconn: pcb 0xe2f8a000 (192.168.8.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (1 occurrences), euid 0, rgid 62, jail 0 Dec 27 10:15:05 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached Dec 27 10:15:16 netgate kernel: sonewconn: pcb 0xe2f8a000 (192.168.8.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (250 occurrences), euid 0, rgid 62, jail 0 (...) Dec 27 11:00:21 netgate kernel: sonewconn: pcb 0xe2f8a000 (192.168.8.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (18 occurrences), euid 0, rgid 62, jail 0 Dec 27 11:00:25 netgate kernel: sonewconn: pcb 0xe4a4f800 (127.0.0.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (4 occurrences), euid 0, rgid 62, jail 0 Dec 27 11:05:06 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached Dec 27 11:10:06 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached Dec 27 11:15:07 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached Dec 27 11:20:07 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached ---> FIREWALL BECAME COMPLETELY UNRESPONSIVE AND REQUIRED POWER CYCLINGSquid doesn't log much:
Wednesday, 27 December 2023 10:04:44.299 509 192.168.8.96 TCP_TUNNEL/200 8309 CONNECT mybucket.s3.amazonaws.com:443 - HIER_DIRECT/3.5.20.172 - Wednesday, 27 December 2023 10:09:19.934 403 192.168.8.96 TCP_TUNNEL/200 8297 CONNECT mybucket.s3.amazonaws.com:443 - HIER_DIRECT/52.217.95.145 - Wednesday, 27 December 2023 10:16:56.215 29216 192.168.8.96 TCP_TUNNEL/200 14710 CONNECT mybucket.s3.amazonaws.com:443 - HIER_DIRECT/54.231.229.41 -This seems fine:
# netstat -m 3255/1815/5070 mbufs in use (current/cache/total) 1590/940/2530/10035 mbuf clusters in use (current/cache/total/max) 1590/940 mbuf+clusters out of packet secondary zone in use (current/cache) 1/758/759/5017 4k (page size) jumbo clusters in use (current/cache/total/max) 0/0/0/1486 9k jumbo clusters in use (current/cache/total/max) 0/0/0/836 16k jumbo clusters in use (current/cache/total/max) 3997K/5365K/9363K bytes allocated to network (current/cache/total) 0/0/0 requests for mbufs denied (mbufs/clusters/mbuf+clusters) 0/0/0 requests for mbufs delayed (mbufs/clusters/mbuf+clusters) 0/0/0 requests for jumbo clusters delayed (4k/9k/16k) 0/0/0 requests for jumbo clusters denied (4k/9k/16k) 0/6/6656 sfbufs in use (current/peak/max) 0 sendfile syscalls 0 sendfile syscalls completed without I/O request 0 requests for I/O initiated by sendfile 0 pages read by sendfile as part of a request 0 pages were valid at time of a sendfile request 0 pages were valid and substituted to bogus page 0 pages were requested for read ahead by applications 0 pages were read ahead by sendfile 0 times sendfile encountered an already busy page 0 requests for sfbufs denied 0 requests for sfbufs delayedSame with historical mbuf usage and memory usage - no problems there.
The same "aws s3 cp" command runs fine when it's forced to bypass proxy.
Is anybody else able to reproduce the issue? -
 A adamw referenced this topic on
A adamw referenced this topic on
-
Are you able to reproduce this on an amd64/arm64 system? If not, that could mean the issue is specific to armv7.
-
Jumbo packets/frames require a different MTU size
"MTU: MTU is short for Maximum Transmission Unit, the largest physical packet size, measured in bytes, that a network can transmit. Any messages larger than the MTU are divided into smaller packets before transmission.
Jumbo: Jumbo frames are frames that are bigger than the standard Ethernet frame size, which is 1518 bytes (this includes Layer 2 (L2) header and FCS). The definition of frame size is vendor-dependent, as these are not part of the IEEE standard.
Baby giants: The baby giants feature allows a switch to pass or forward packets that are slightly larger than the IEEE Ethernet MTU. Otherwise, the switch declares big frames as oversize and discards them" (CISCO).
@adamw said in "aws s3 cp" crashes the firewall when using squid web proxy:
3255/1815/5070 mbufs in use (current/cache/total)
1590/940/2530/10035 mbuf clusters in use (current/cache/total/max)
1590/940 mbuf+clusters out of packet secondary zone in use (current/cache)
1/758/759/5017 4k (page size) jumbo clusters in use (current/cache/total/max)
0/0/0/1486 9k jumbo clusters in use (current/cache/total/max)
0/0/0/836 16k jumbo clusters in use (current/cache/total/max)
3997K/5365K/9363K bytes allocated to network (current/cache/total)
0/0/0 requests for mbufs denied (mbufs/clusters/mbuf+clusters)
0/0/0 requests for mbufs delayed (mbufs/clusters/mbuf+clusters)
0/0/0 requests for jumbo clusters delayed (4k/9k/16k)
0/0/0 requests for jumbo clusters denied (4k/9k/16k)
0/6/6656 sfbufs in use (current/peak/max)Works Cited:
Configure Jumbo/Giant Frame support on Catalyst Switches. (2022, September 7). Cisco. https://www.cisco.com/c/en/us/support/docs/switches/catalyst-6000-series-switches/24048-148.htmlDonato, R. (2020, February 21). MTU, Jumbo Frames and MSS explained. Packet Coders. https://www.packetcoders.io/mtu-jumbo-mss/
Is jumbo clusters the same thing??
-
Found more info.. I got mixed up...
I would play with traffic shaping.
I use a traffic shaper to keep my traffic at the ISP limit I have it's a 6M DSL line. Or the limit or your hardware.. My SG-2100 gets..
CPU: The Dual core ARM v8 Cortex-A53 1.2 GHz delivers 2.20 Gbps routing for common iPerf3 traffic and over 964 Mbps of firewall throughput.
So if I only get a 6meg line I have a limiter in place because my wifi n and firewall want more speed my traffic shaper buffers it all for me.
The jumbo cluster size can be equal to a CPU page size (4K for i386 and amd64), 9K, or 16K. The 9K and 16K jumbo clusters are used mainly in local networks with Ethernet frames larger than usual 1500 bytes, and they are beyond the scope of this article (nginx).
You may increase the clusters limits on the fly using:
sysctl kern.ipc.nmbclusters=200000
sysctl kern.ipc.nmbjumbop=100000@adamw said in "aws s3 cp" crashes the firewall when using squid web proxy:
193 already in queue awaiting acceptance (250 occurrences),
Do you have high loads? If so add a traffic shaper, or different queue management algorithm.
Link to Queue Info:
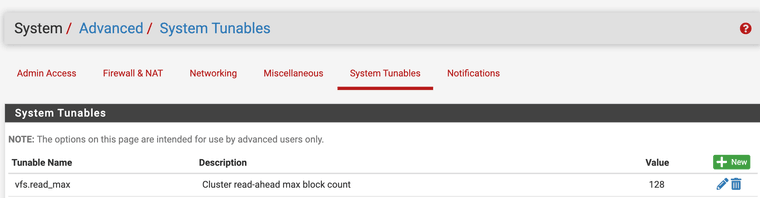
https://forum.netgate.com/topic/171842/queue-management-algorithms-differencesI also use this, vfs.read_max=128 it helped Squid's performance for me.
"Some users have reported better performance by using the ufs cache filesystem setting. When using ufs filesystem, vfs.read_max=32 may be increased to vfs.read_max=128 in System/Advanced, Sytem Tunables tab" (PfSense).
Works Cited:
Tuning FreeBSD for the highload. (n.d.). https://nginx.org/en/docs/freebsd_tuning.htmlPackages — cache / Proxy — Tuning the Squid package | PfSense Documentation. (n.d.). https://docs.netgate.com/pfsense/en/latest/packages/cache-proxy/tune.html
Make sure to upvote
-
No, I only have 3 x Netgate 3100 boxes running pfSense.
-
The load is pretty low 99.9% of the time and looks something like this:
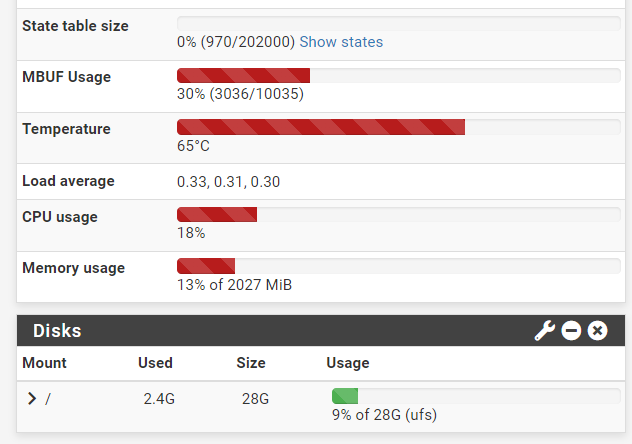
Both crashes happened during particularly quiet times.
I'm assuming that for making the tweaks permanent I should change:
/boot/defaults/loader.conf #kern.ipc.maxsockets="" # Set the maximum number of sockets available #kern.ipc.nmbclusters="" # Set the number of mbuf clusters #kern.ipc.nsfbufs="" # Set the number of sendfile(2) bufsCorrect?
TBH I don't think I'll be messing around with it any time soon.
The firewall is in production and I have a sensible workaround in place.Hopefully one of pfSense devs will get to the bottom of this and provide a proper fix or at least a detailed explanation.
-
@adamw That's a nice state table and memory use, that shouldn't be the issue.
-
You still only ever see:
0/0/0 requests for mbufs denied (mbufs/clusters/mbuf+clusters) 0/0/0 requests for mbufs delayed (mbufs/clusters/mbuf+clusters) 0/0/0 requests for jumbo clusters delayed (4k/9k/16k) 0/0/0 requests for jumbo clusters denied (4k/9k/16k)Zero denied clusters?
-
This post is deleted! -
@stephenw10 he does show some 1 Jumbo in the list above, but no denied, would MTU on the Amazon side cause this?
-
I would not expect it to. Unless I've misunderstood this the Squid instance is local and AWS here is remote. So the MTU of the link between them is very unlikely to be more than 1500B, probably less.
The problem seems more likely to be that it's trying to cache the full file and then stops accepting traffic.
Do you see the same thing if you try to upload that file to somewhere else? Or any file >500MB to anywhere?
-
To recap:
Squid is local and runs on our LAN firewall / gateway.
AWS S3 bucket is obviously remote.
"Aws s3 cp" tries to copy from a LAN Debian machine to that bucket.
Transfer goes through fine if it bypasses Squid.
When it's told to use web proxy it crashes the firewall after uploading 0.5 / 8 GB.I've just successfully uploaded a 8 GB file to Google Drive involving Squid.
The transfer took several minutes. CPU usage remained at 50-60%.
MBUF Usage reached 30% (3036/10035) and stayed there.
No crash or any noticeable impact on other services and connectivity. -
@adamw What port is used? You need to add that to safe ports in Squid.. I had issues with the college ports needed to be marked safe in Squid that was in use without them it failed any connections
-
@JonathanLee
TCP 443 in both cases (aws s3 cp and Google Drive upload). -
Is Squid set as Custom SSL MITM or Transparent or both??
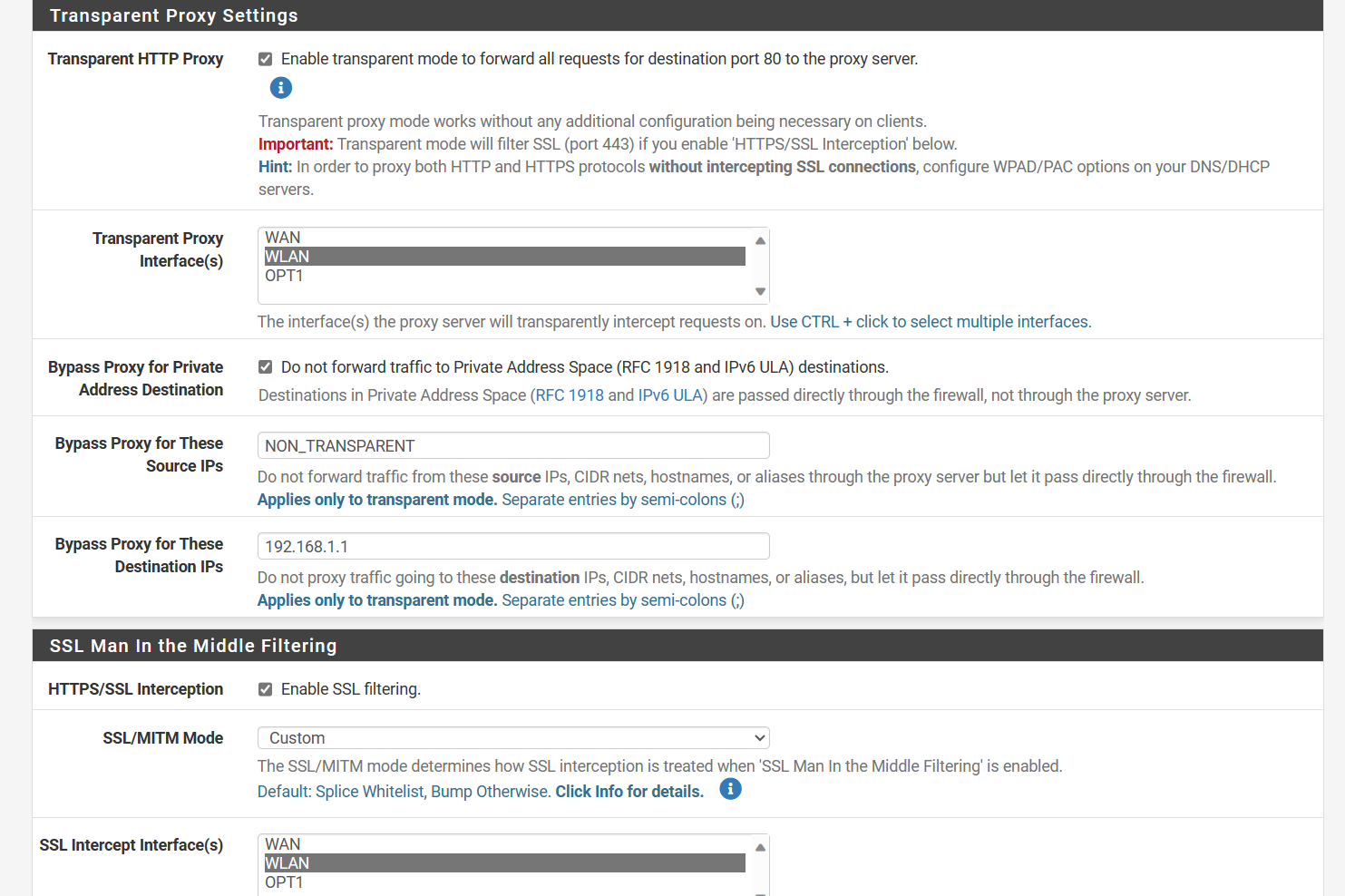
Some sites need to be splice only add this as a splice only
I do this with advanced
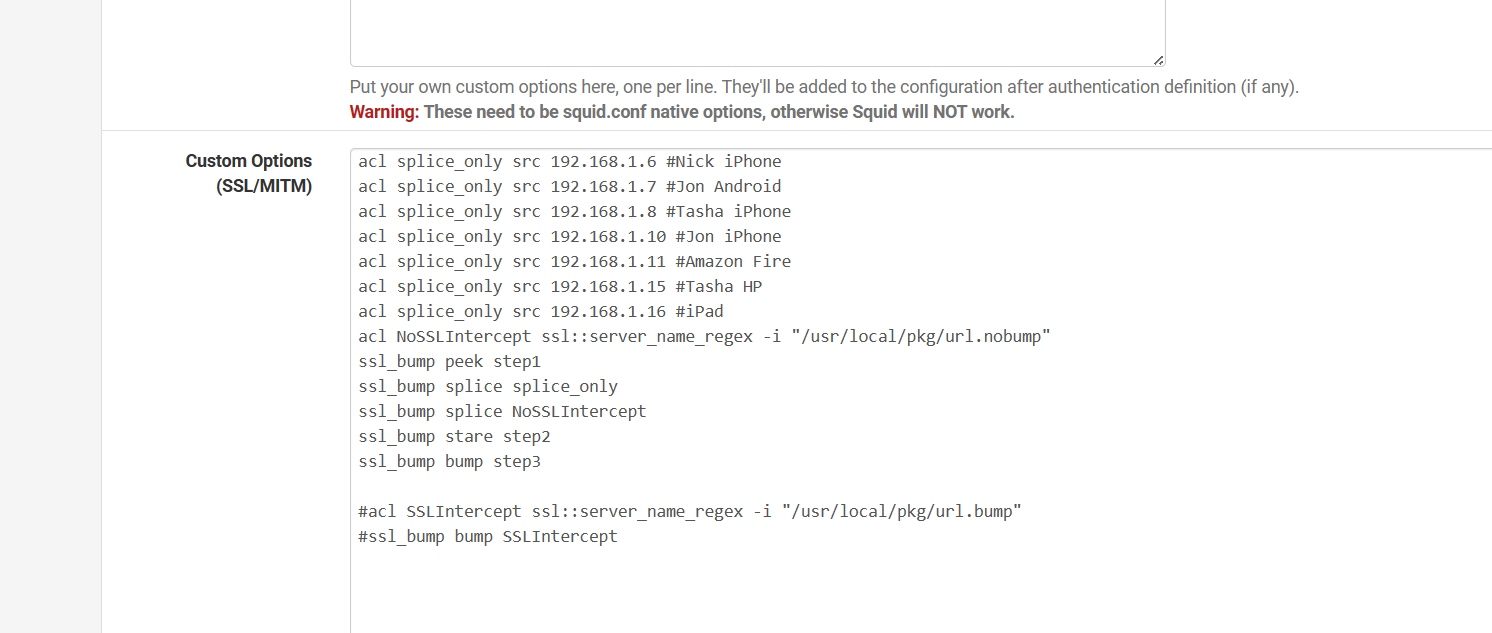
I have a regex splice file that has sites always set to splice
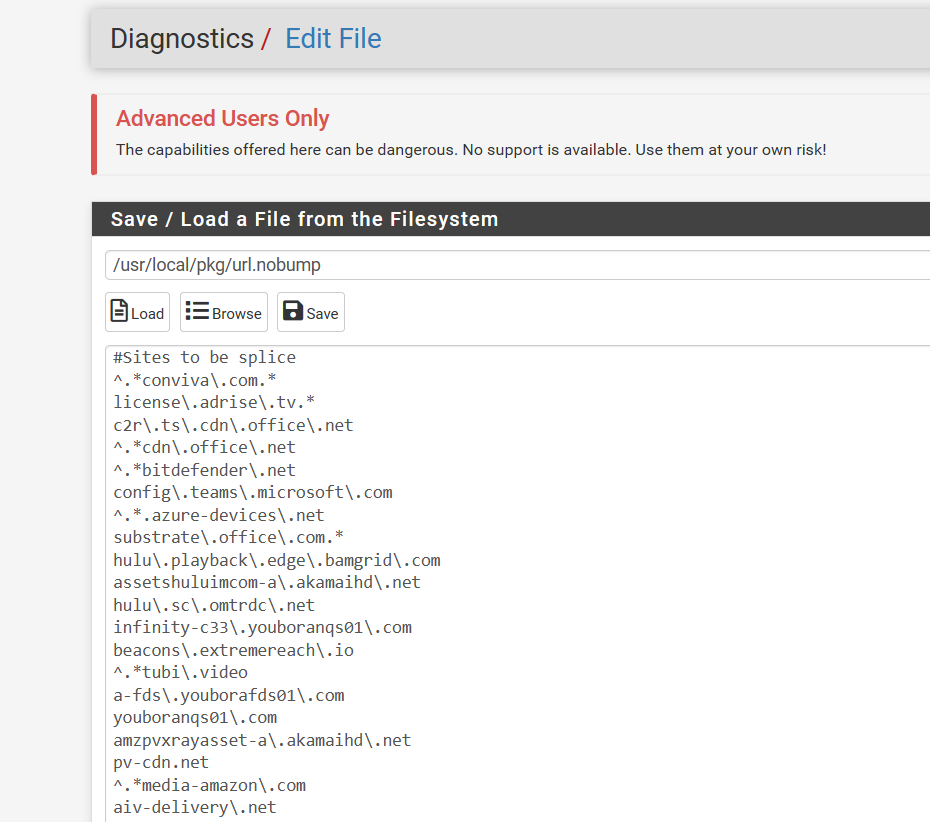
-
My settings:
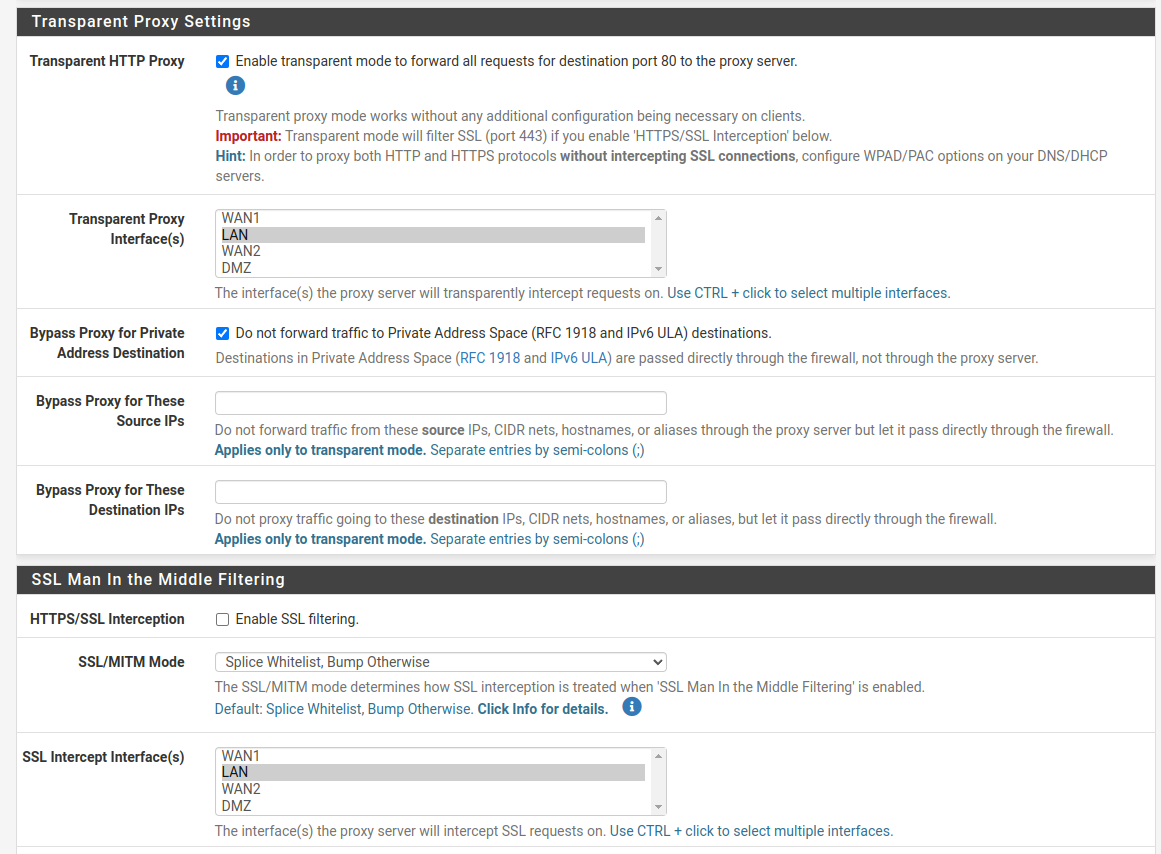
Making it bypass proxy has basically solved my problem but thanks for the suggestions.
-
-
@adamw IP addresses that are set to already use the proxy don’t need to be transparent also because they know the proxy addresses already. That is what my bypass is so it doesn’t double them.
-
@JonathanLee said in "aws s3 cp" crashes the firewall when using squid web proxy:
@adamw @mcury I also bypass destination of my firewall IP that helped me with weird firewall logs showing up. I have my 192.168.1.1 as go to firewall rules
If you are going to use transparent proxy for some users and explicit proxy for others, as I used to do back in my Squid days, the best way I found was :
Bypass Proxy for These Source IPs: Include all IPs that are going to use explicit proxy.
Bypass Proxy for These Destination IPs: Inlucde here all the local networks, advice would be to add 10.0.0.0/8;172.16.0.0/12;192.168.0.0/16For users using explicit mode, do the same bypass but in the client settings (Browser and/or OS, or through the .pac file directly).
-
Just a quick reminder that the thread is not about bypassing squid but about a sensible https request crashing the firewall requiring a power cycle :)