strange errorThere were error(s) loading the rules: pfctl: SIOCGIFGROUP: Device not configured

-
@pfsss said in strange errorThere were error(s) loading the rules: pfctl: SIOCGIFGROUP: Device not configured:
Feb 28 00:01:52 kernel re0: watchdog timeout
Feb 28 00:01:52 kernel re0: link state changed to DOWNOk, that looks like a NIC/driver issue. You should try using the kmod-realtek driver package.
-
Just got this in an (Notifications in this message: 1) email this morning.
16:33:32 There were error(s) loading the rules: pfctl: SIOCGIFGROUP: Device not configured - The line in question reads [0]:... BUT
I have been seeing a bouncing of the connection between the WAN Ethernet port on the dedicated unit that runs pfSense+ as it connects to the ISP bridge for PPOE. ever since I upgraded to:
Version 23.09.1-RELEASE (amd64) built on Wed Jan 10 7:58:00 -08 2024 FreeBSD 14.0-CURRENTI am running:
Intel(R) Celeron(R) N5105 @ 2.00GHz Current: 2795 MHz, Max: 1996 MHz 4 CPUs : 1 package(s) x 4 core(s)The BIOS version on my dedicated device is:
Vendor: Techvision, LLC. Version: 5.19 Release Date: Wed Sep 7 2022A log entry says:
Feb 28 16:33:41 php-fpm 76679 /rc.newwanip: Netgate pfSense Plus package system has detected an IP change or dynamic WAN reconnection - 58.69.150.45 -> 58.69.150.45 - Restarting packages.and then
Feb 28 16:33:42 php-fpm 72862 /rc.start_packages: Configuration Change: (system): pfBlockerNG: saving DNSBL changesBUT I have a static IP address from the ISP and is does NOT change. I have had this address for many years now and I never saw bouncing on a WAN interface until the latest BSD release.
PLEASE pay attention to this. -
Check the system log for link state changes.
-
@stephenw10
I did and you see all there is within the log file related to that in my post above. There are previous ones, but they are no different. None existed prior to the software upgrade, -
@stephenw10
I should also note that I have an active network monitoring system running on a server. I can see when something is bouncing. This is what that part of the map looks like when the interface is up.

It goes read and sounds an alarm with the interface goes down, and just so lucky iI caught the very end of it as I was writing this!
The log shows only this.
Feb 28 20:25:00 sshguard 25376 Exiting on signal. Feb 28 20:25:00 sshguard 64179 Now monitoring attacks. Feb 28 20:26:03 kernel arp: 00:0c:43:e1:76:29 is using my IP address 192.168.1.1 on igc3! Feb 28 20:26:05 kernel arp: 00:0c:43:e1:76:29 is using my IP address 192.168.1.1 on igc3! Feb 28 20:32:00 sshguard 64179 Exiting on signal.And like normal there was no "email" notification.
AND there is NO 00:0c:43:e1:76:29 seen when I type 'arp -n -a' on the pfSense+ unit. (I am happy to upload that is needed. :-) -
If the interface actually goes down, bounces as you say, then there will be log messages indicating that.
The logs you posted above show simply that the WAN reconnected at some point but not the cause of that which would have been before that in that logs.
What version did you upgrade from?
-
@stephenw10
I honestly don't remember the version but it was probably the most recent.Here is a sample from the system gateway log. Once again there errors did not appear before the upgrade I did in January. They started and the bouncing immediately following the upgraded version.
Feb 28 16:33:28 dpinger 4624 WAN_PPPOE 58.69.145.0: sendto error: 65 Feb 28 16:33:28 dpinger 4624 exiting on signal 15 Feb 28 16:33:38 dpinger 17224 send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% alarm_hold 10000ms dest_addr 58.69.145.0 bind_addr 58.69.150.45 identifier "WAN_PPPOE " Feb 28 23:18:21 dpinger 17224 WAN_PPPOE 58.69.145.0: Alarm latency 1607111us stddev 3527976us loss 0% Feb 28 23:18:23 dpinger 17224 WAN_PPPOE 58.69.145.0: sendto error: 65 Feb 28 23:18:23 dpinger 17224 WAN_PPPOE 58.69.145.0: sendto error: 65 Feb 28 23:18:24 dpinger 17224 WAN_PPPOE 58.69.145.0: sendto error: 65 Feb 28 23:18:24 dpinger 17224 exiting on signal 15 Feb 28 23:18:39 dpinger 89624 send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000m -
The system log at that time would show more. Again the gateway log only shows the consequences of something else. Latency hits 1.6s so it throws an alarm. Then 3s later dpinger is killed and then restarted presumably after the ppp session reconnects.
-
@stephenw10
I understand that the log 'should' but it doesn't. Do I need to send a larger snippet to prove it? -
I mean it's possible the WAN failed because of something upstream. Maybe your WAN latency is very sensitive to traffic? Check the Status > Monitoring graphs for traffic flow at that time.
-
@stephenw10
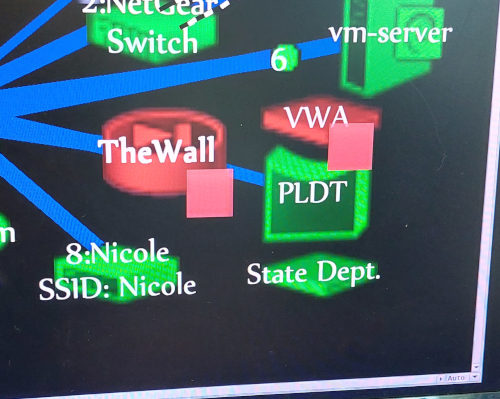
Do you see the RED "The Wall" in the second graphic above. That is what you see when an 'Device drops not an interface. And what is it monitoring? Intermapper is monitoring the address 192.168.1.1 on the device (the LAN port). So the drops are NOT an upstream issue. Maybe they're the phantom MAC address that is NOT on my system. (Unless you want to argue that the ISP bridge, on occasion forget's it's a bridge and starts announcing it self as my gateway.) So maybe? the drop can be related to an upstream issue, but it is the device does we see drop. The software I am using is Intermapper from Help Systems. It is getting its information via SNMP from the router/firewall.I never saw the issued related to the WAN port before, I never saw the device drops I see now, until the software upgrade occurred. The issues stared within hours.Until I got the 'email notification,' I had nothing in the logs other than a phantom MAC address that doesn't exist on my network to look at. But the email got me writing this.
For what it's worth the manufacturer associated with the MAC address does not have an obvious connection to the devices on my network..(See below). All such devices that are of the same tye but different manufacturer are assigned proper IP addresses and can be found on the network.
From https://en.wikipedia.org/wiki/Ralink
Ralink Technology, Corp. is a Wi-Fi chipset manufacturer mainly known for their IEEE 802.11 (Wireless LAN) chipsets. Ralink was founded in 2001 in Cupertino, California, then moved its headquarters to Hsinchu, Taiwan. On 5 May 2011, Ralink was acquired by MediaTek.Some of Ralink's 802.11n RT2800 chipsets have been accepted into the Wi-Fi Alliance 802.11n draft 2.0 core technology testbed. They have also been selected in the Wi-Fi Protected Setup (WPS) and Wireless Multimedia Extensions Power Save (WMM-PS) testbeds. Ralink was a participant in the Wi-Fi Alliance and the IEEE 802.11 standards committees.[1] Ralink chipsets are used in various consumer-grade routers made by Gigabyte Technology, Linksys, D-Link, Asus and Belkin, as well as Wi-Fi adaptors for USB, PCI, ExpressCard, PC Card, and PCI Express interfaces. An example of an adapter is the Nintendo Wi-Fi USB Connector which uses the Ralink RT2570 chipset to allow a Nintendo DS or Wii to be internetworked via a home computer.
-
OK well if it's monitoring the LAN side then the reported LAN IP conflict could certainly be causing it:
arp: 00:0c:43:e1:76:29 is using my IP address 192.168.1.1 on igc3How often do you see that logged?
Is igc3 the LAN interface?
Check the MAC address in the ARP table of the monitoring system when it shows as down.
The device is on your network somehow. Using that IP makes it likely to be a router/firewall of some sort.
-
@stephenw10
The MAC address does NOT appear on the arp table for: (1)the netgate device; (2) the DHCP server (a Linux server); (3) my desktop; the arp table of my managed switch. Angry IP scanner does not see it. There are 53 hosts plus mobile units, but in each case I know both the MAC address and the assigned IP.So either this is a phantom but real MAC address that only decided to come alive as soon as the last Netgate/FreeBSD code was installed (as nothing had at that time been added to the network, or it is the Netgate/FreeBSD code. Are you wanting to argue that the phantom MAC address and the attached gateway IP was always there and earlier Netgate/FreeBSD code wasn't good enough to see it? I am confused.
While at the same time, there was the appearance of the PPPoE issue regarding error 65 on the gateway.
-
@Ellis-Michael-Lieberman said in strange errorThere were error(s) loading the rules: pfctl: SIOCGIFGROUP: Device not configured:
The MAC address does NOT appear on the arp table for: (1)the netgate device; (2) the DHCP server (a Linux server); (3) my desktop; the arp table of my managed switch. Angry IP scanner does not see it.
That is when the firewall shows as down in the monitoring system?
It could be coincidental that the monitoring system stops being able to pull responses from the firewall and the firewall is logging another device using it's IP.
I would guess something is falling back to a default config or perhaps using that IP/MAC when it boots and then switching to something else.
However something on the LAN using the same IP would not cause a problem on the WAN side. That assumes igc3 is the LAN as I asked above?
-
@stephenw10
"It could be coincidental that the monitoring system stops being able to pull responses from the firewall and the firewall is logging another device using it's IP."But it never did for well over a year before the upgrade? And it don't do that for other devices? And an SNMP query can do that? Yeah, I'm not buying that.
"I would guess something is falling back to a default config or perhaps using that IP/MAC when it boots and then switching to something else."
It could be but power is stable and nothing here when running has that MAC address.
"That assumes igc3 is the LAN as I asked above?"
Yes igc3 is the LAN side. So both the LAN side and the WAN side are producing weirdness that they never produced before. How likely is that?
-
still no easy way to resolve this problem?
-
@pfsss
The problem persists.Mar 4 03:09:34 kernel arp: 00:0c:43:e1:76:29 is using my IP address 192.168.1.1 on igc3! Mar 4 03:09:36 kernel arp: 00:0c:43:e1:76:29 is using my IP address 192.168.1.1 on igc3!This MAC address does NOT exist on the LAN. I have a list of every MAC address on this LAN.
All the while here is the speed test on a 200GB fiber connection:
Speedtest by Ookla [error] Error: [101] Network unreachable Server: Panay Broadband (BCATVi) - Iloilo (id: 9935) ISP: Philippine Long Distance Telephone Idle Latency: 27.69 ms (jitter: 0.11ms, low: 27.62ms, high: 27.82ms) Download: 212.02 Mbps (data used: 296.8 MB) 27.88 ms (jitter: 7.20ms, low: 27.38ms, high: 296.45ms) Upload: 218.33 Mbps (data used: 221.7 MB) 28.66 ms (jitter: 0.79ms, low: 28.17ms, high: 36.35ms) Packet Loss: 0.0% Result URL: https://www.speedtest.net/result/c/47d96817-22ce-4051-87eb-22c8c191eff7Which makes no sense as I am getting a great through speed while at the same time am told "Network unreachable."
-
@Ellis-Michael-Lieberman said in strange errorThere were error(s) loading the rules: pfctl: SIOCGIFGROUP: Device not configured:
Mar 4 03:09:34 kernel arp: 00:0c:43:e1:76:29 is using my IP address 192.168.1.1 on igc3!
Mar 4 03:09:36 kernel arp: 00:0c:43:e1:76:29 is using my IP address 192.168.1.1 on igc3!Does it always appear like that with 2s between two warnings?
I'd be amazed if that's not a real conflict. I've never seen that alert triggered as a false positive.
I'd still guess it's something using that MAC at bootup, maybe trying to PXE boot. Something with a Ralink SoC probably.
Anything else that sees those broadcasts and updates it's ARP table would lose connectivity until it gets updated again. However you said you checked the ARP table on the monitoring system whilst it showed as down and it was correct. So it could be unrelated.
-
@stephenw10
First, not it is not always twice. It is often once. As is:Mar 3 20:25:00 sshguard 80813 Exiting on signal. Mar 3 20:25:00 sshguard 70235 Now monitoring attacks. Mar 3 20:29:29 kernel arp: 00:0c:43:e1:76:29 is using my IP address 192.168.1.1 on igc3! Mar 3 20:34:00 sshguard 70235 Exiting on signal. Mar 3 20:34:00 sshguard 47918 Now monitoring attacks. Mar 3 20:43:00 sshguard 47918 Exiting on signal.- Nothing was booting on the LAN. I have a log for that on the network monitoring tool.
- Everything that boots has a known MAC address which isn't that one.
I know each and every item on this LAN. I put these things on the LAN. Every item is accounted for and its MAC address is know. There is no Ralink devices here. - The reporting of a Down interface is on 30 second sweeps. The connection between the arp table and the DOWN map is not at the same time. The event had passed. The event was millisecond or two and then the Router has to regain the PPPoE traffic.
-
Ok likely unrelated then.
You should still find out what is sending from that MAC though. Something on that segment is and clearly it's something you don't know about.