Intermitent loss of WAN routing
-
Since updating to pfSense+ 24.03-RELEASE on my Netgate 4100 I'm experiencing an intermitent loss of WAN connectivity for periods less than 20mins about once a day. I leaning towards a Netgate 4100/pfSense+ configuration/software issue but I'm not certain and I'm hoping a description of the problem here may illicit some suggestions.
The problem
When the problem occurs, ICMP Echo Requests sent from pfSense+ or from any host on the LAN to the ISP default gateway/router do not receive a reply (All LAN and VLAN routing through pfSence+ remains ok). Traffic sent to any other Internet host does not get a reply either. It's as if the ISP default gateway/router is no longer responding. Service dpinger is monitoring the ISP default gateway/router and identifies this loss of connectivity. However, sending a single ICMP Echo Request to another ISP host on the same subnet as their default gateway/router immediately restores ALL WAN routing. I find myself leaning towards a Netgate 4100/pfSense+ configuration/software issue as opposed to an ISP issue due to the following. Immediately prior to sending the ICMP Echo Request packet to the other ISP host pfSense+ broadcasts an ARP request on the WAN for the address to which the ICMP Echo Request is being sent. It is the generation/transmission of this ARP packet which reliably coincides with restoration of WAN routing. i.e. WAN routing resumes BEFORE an ARP reply is received and thus before the ICMP Echo Request is sent.
Further info
The problem was occurring almost daily until I selected 'Disable Gateway Monitoring' and 'Disable Gateway Monitoring Action' via the System|Routing|Gateways|Edit page. I've found little documentation on what Actions are executed by the latter but understand it's purpose is to failover to/from the alternate WAN interface. With only one WAN connection, having it enabled seemed inappropriate and so it has been disabled and Gateway Monitoring enabled. Since that change the problem, when it occurs, seems to heal itself and within 20mins. Notably 20mins is 1200secs = ARP refresh interval. One test I am yet to do is watch the ARP timeout value for the ISP default gateway/router and confirm that the restoration of routing coincides with expiry and refresh. Although easy to do, timing is difficult due to the intermitent nature of the problem and remaining timeout period.
When Gateway Monitoring Action's were enabled and the problem occurred it was noticeable that on checking there were NO WAN entries in the Netgate 4100 ARP cache, not even for its local WAN interface. However, with only 'Gateway Monitoring Action' disabled I've noted that the local WAN interface and the ISP default gateway/router remain present in the ARP cache. The former being 'Permanent' and the latter tagged as expiring in nnnn seconds. The MAC address of the ISP default gateway/router is always the same.
Promiscuous mode packet captures made with pfSense+ during the problem show packets being sent on the WAN interface but nothing being received until the ARP broadcast packet after which, incoming traffic is observed.
Early investigation led me to think the problem was related to DHCP and the service provider blocking access before expiry/renewal. This was the hypothesis when I made a post here a few weeks ago entitled 'Using dpinger to force DHCP lease renewal'. Subsequently I confirmed that it's transmission of an ARP Request that restores routing and it's unrelated to DHCP or the ISP blocking access.
Summary
So I'm thinking that either the Netgate 4100 or pfSense+ at some level ceases to recognise incoming WAN traffic until, and possibly coincidentally, there is a WAN entry change in its ARP cache. Seems strange I know, but these are the symptoms I'm seeing.
Any thoughts what may be causing this behavior? If you have got here, at the bottom of this long post, congratulations and thank you for reading.
Andrew
-
@AGawthrope
You can leave Gateway Monitoring enabled but disable Gateway Monitoring Action.
Gateway monitoring Action is unfortunately enabled by default (which it really shouldn't be but that's another story) so it makes sense when there is an issue with the monitored IP that triggers a gateway failure and the restarting of packages , etc...So maybe i missed it but whats the problem now that you have monitoring action disabled? You are still losing WAN connectivity?
-
@michmoor Hi. With 'Gateway Monitoring' enabled and 'Gateway Monitoring Action' disabled. I'm seeing the intermitent WAN routing issue described. i.e. generating an ARP Request appears to bring the reception of traffic on the WAN interface back to life.
Andrew
-
@AGawthrope what IP are you monitoring? Something on the internet or your providers gateway (public IP i would assume)
-
@michmoor The service providers gateway. That known to pfSense+ as its default gateway and obtained via DHCP.
-
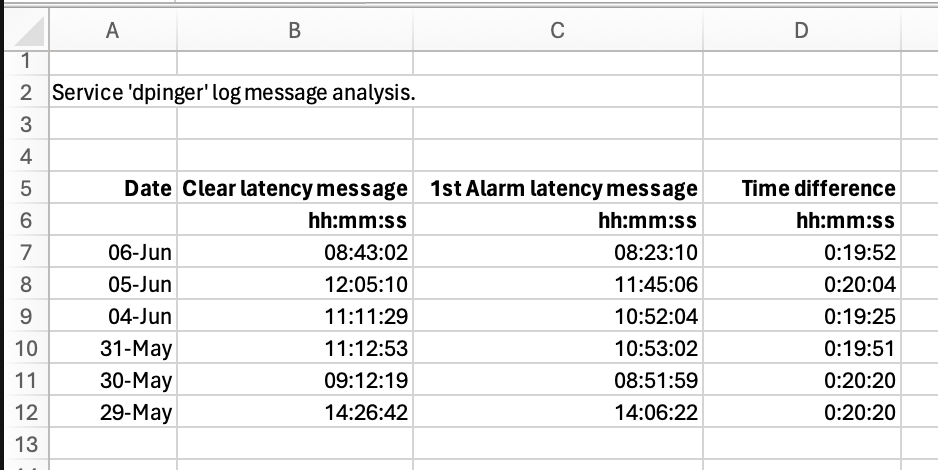
A little further info from some analysis of the 'dpinger' log over the last six days. The problem has occured each day and healed itself after 20mins of outage. The times in the table are those from the log i.e. 'Status|System Logs|System|Gateways' so I'm not surprised the difference between the first Alarm latency message and the corresponding Clear latency isn't exactly 20mins.
Each outage is very close to 20mins or the ARP refresh timeout.....
Edit: I should add that there were no alarm messages logged between the 1st to 3rd June.
-
If you see outgoing traffic but no replies that sounds like an ARP issue upstream. Perhaps something else sometimes using your IP address.
One thing you can try is setting
net.link.ether.inet.max_ageto something shorter than 1200 and seeing what difference that makes. -
@stephenw10 Thank you. Possibly, but that feels a little esoteric. My earlier investigations looked at the provision of an IP address and the ISP DHCP server always provides me with the same IPv4 address. If it was also providing it to another then I'd expect some variance from time to time.
Would I be correct in thinking that I could set the max_age variable via the System Tunables page?
Thanks
Andrew -
Yes you can set that as a system tunable.
It doesn't have to be the ISP handing out your address via DHCP. Just some other device sending ARP packets with your IP. Potentially.
-
@stephenw10 Thanks for that and understood. Getting anything sensible from the ISP regarding duplicate IP's is a non-starter. Their technical 'support' haven't even heard of IPv6! I'll leave changing the ARP timeout for a few days as I'm keen to see if there is any pattern to the problem.
I'm also keen to hear what others may suggest.
Thanks
Andrew -
I wanted to post an update to close-off this thread for now.
Further analysis has identified that the problem is only occuring Monday through Friday and during working hours. This alone makes me suspicious that its an ISP triggered event that is the root cause.
Nominally my pfSense+ WAN interface receives an ARP Request from the ISP virtual gateway/router (the client facing interface of a VRRP group router) every 60 secs. pfSense+ is configured with a 1200sec ARP table timeout. Because pfSense+ relearns the MAC address of the ISP gateway/router from these 60sec exchanges it does not originate its own ARP Request every 1200secs. So when the intermitent problem occurs - which it is still doing - and ALL packets, including ARP Requests from the ISP virtual gateway/router cease the ARP table entry in pfSense+ ages for 19/20mins until its expiry at which point pfSense+ originates an ARP Request and nominal service/routing is fully restored - including the 60sec reception of ARP Requests from the ISP.
If during the period when no traffic is being received from the ISP and before the pfSense+ ARP table timeout of the ISP gateway/router, any traffic is sent to the ISP gateway/router no response will be received.
On expiry of the ARP table entry in pfSense+ or by forcing pfSense+ to originate a new ARP Request (for any ISP host on the same subnet as the pfSense+ WAN interface that is not already in the pfSense+ ARP table) nominal service is immediately restored with the resumption of all incoming traffic - including the 60sec, ISP ARP Requests.
For now, I'm thinking that something is occurring on the ISP side which stops them originating ARP Requests and they quickly loose layer-2 addressing knowledge of my pfSense+ interface. Hence when pfSense+ transmits an ARP request the ISP is able to relearn the Ethernet and IPv4 address of the pfSense+ WAN interface and thus able to start passing traffic again.
As trying to communicate this to the ISP will be hell, I plan to explore all possible causes on my side. So my next step is to monitor all traffic passing between the Netgate 4100 and the ISP ONT on a separate computer with promiscusous interface. If when the problem occurs, I don't see incoming traffic then I'm confident its an ISP problem; If I do see incoming traffic then I know it's a pfSense+ problem.
@stephenw10 suggested reducing the ARP timeout period. I'm confident this would reduce the duration during which no traffic is received but the timeout would need to be very short and thus would create a high volume of ARP traffic to provide a usable workaround.
For now I'm running a script which ping's the ISP default router/gateway and when no response is received it ping's a different host on the same subnet and which is not in the pfSense+ ARP table. This restores service within the ping period (1 sec) making a usable workaround.Andrew
-
Fun! If you just have something pinging continually against another host does that also fail? Since it would already be in the arp table, if it's a real host.
-
@stephenw10 Yes, indeed :-). When pinging something continually and the problem occurs it will fail until pfSense+ ages and renews the ARP table entry or, as with my script, any ARP Request containing the layer-2 and layer-3 addresses of the pfSense+ WAN interface is transmitted to the ISP.
Thanks @stephenw10.
Andrew