runaway delay average and std. dev. on WAN
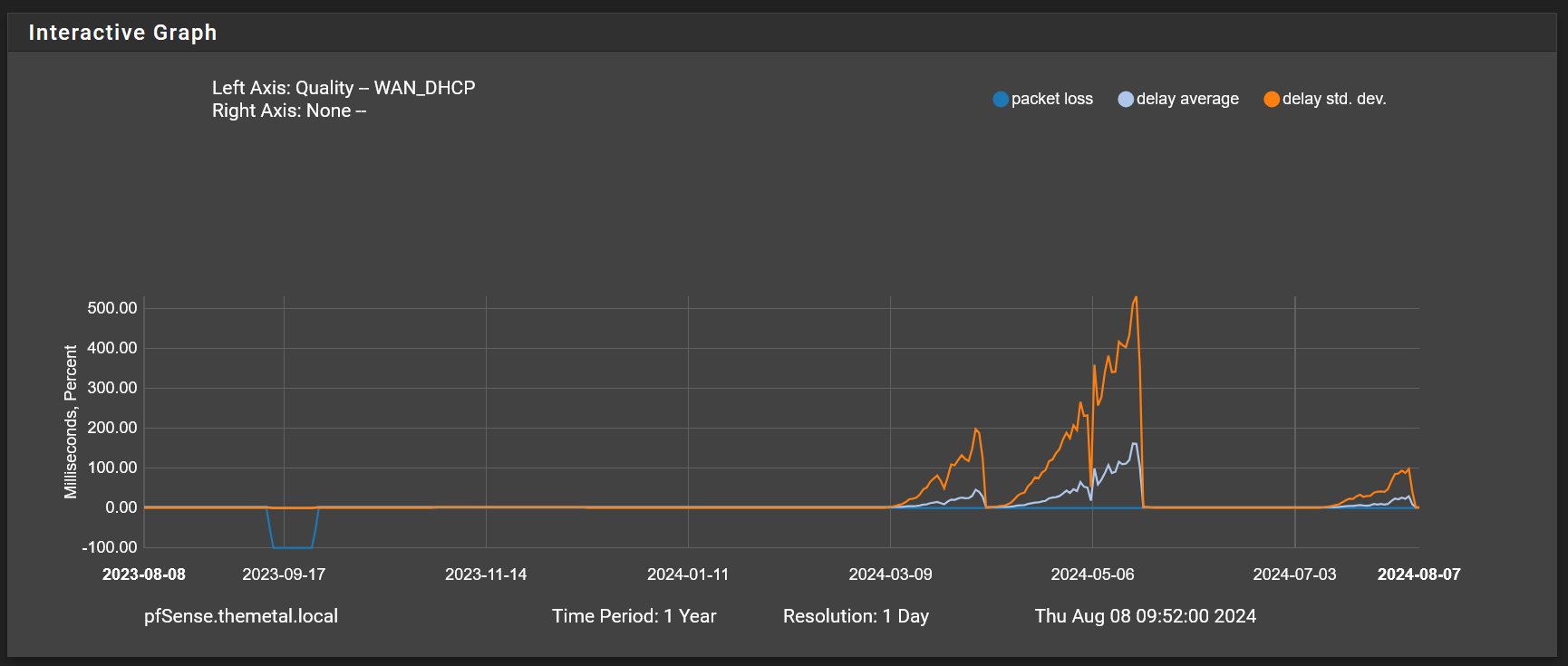
-
@stephenw10 said in runaway delay average and std. dev. on WAN:
@papaMURKS said in runaway delay average and std. dev. on WAN:
The condition is 'reset' by rebooting the AT&T box. (probably worth saying that idk if this actually resets it - due to the apparent exponential nature getting compounded, the issue may be present immediately following restart, albeit to a negligible extent).
Hmm, I would try reconnecting the cable between the AT&T device and 3100. See if that resets anything.
Then try reconnecting the upstream incoming WAN cable if you can. See if that has any effect.
If rebooting the AT&T router resets it though that seems like an issue there.
Thanks for the suggestion. Unfortunately I won't be able to determine if there is any effect using this method until the behavior presents itself again.
I am open to any other investigation or troubleshooting techniques that may help identify the issue until then :)
-
Do you actually see that delay against external hosts? Is your WAN monitoring using the WAN IP directly?
-
@stephenw10 said in runaway delay average and std. dev. on WAN:
Do you actually see that delay against external hosts? Is your WAN monitoring using the WAN IP directly?
I might show my ignorance in this response, but I'll take a crack at it:
The monitoring is not monitoring my WAN gateway directly. (i.e., if my WAN IP is 55.55.55.55, my WAN gateway is 55.55.55.1, and I'm monitoring 123.45.67.1)
I gathered that monitoring address by doing a Traceroute and selected the first hop after the local IP of the RG. (i.e., 1st hop is 192.168.1.254, and 2nd hop is 123.45.67.1)
I'm not sure how to answer whether I see the delay against external hosts.
-
Well in part of that graph you are seeing ping latency >100ms. So if you ping, for example, 8.8.8.8 you will very clearly see that. If you only see it against the monitoring target that implies something other than just a delay in the route may be happening.
-
@stephenw10 yes there is definitely a delay from reaching external hosts. noticeable by pinging an ip directly, as well as by pinging a domain. (i use Unifi Wifiman which has a neat little UI for monitoring pings in real time to facebook, google, x, and i added 8.8.8.8 and 1.1.1.1 as well. those pings to my local gateway are normal, ~4ms)
-
Ok cool. Then I guess wait for it to grow to something clearly visible then try to reset it without rebooting the AT&T router. If nothing else resets it the issue pretty much has to be there.
-
@stephenw10 so, unexpected behavior...
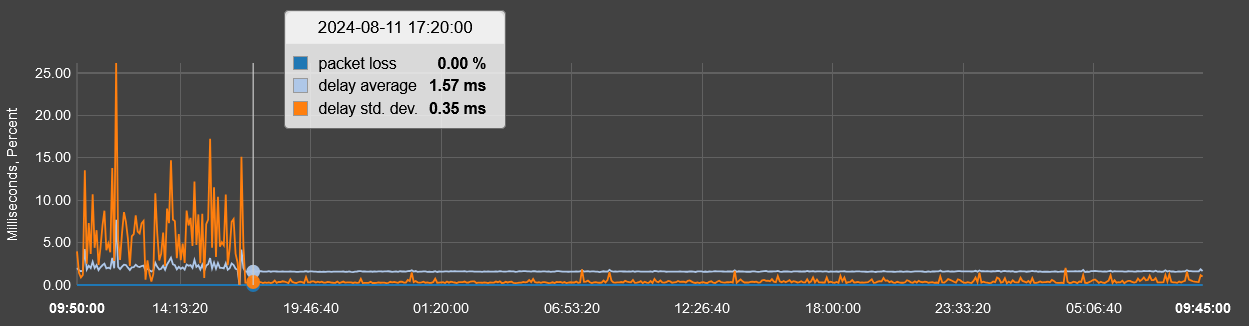
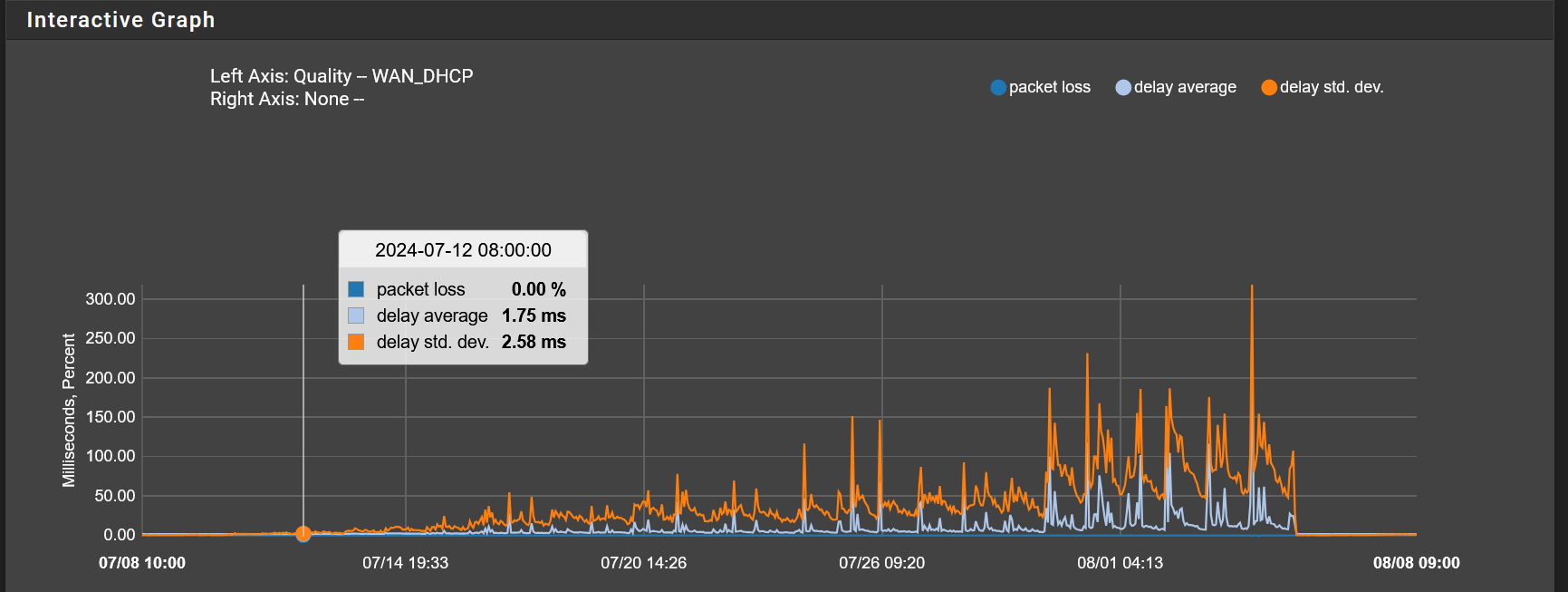
above graph is last 2 days...around 5pm on 8/11 my rtt ping statistics improved drastically (i.e., to expected levels and consistent with times immediately following a RG reboot) with NO (known) INTERVENTION BY ME
in reviewing my logs, i see a HUGE amount of arpresolve logs in the times leading up to and following the good RTT pings:
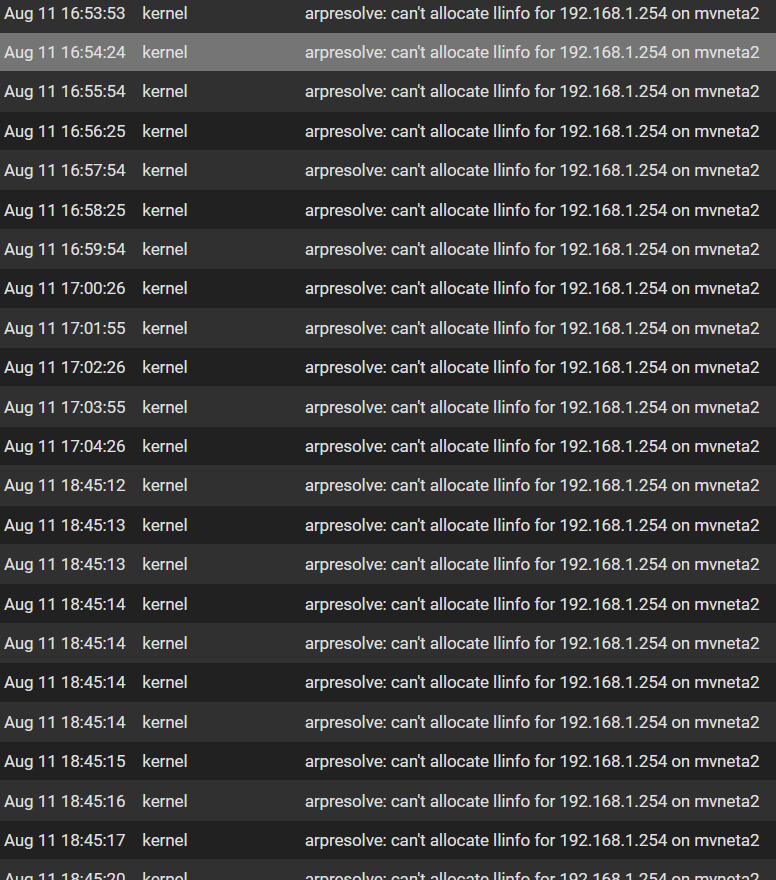
For context, the logs in the above image are only displaying 500 lines and the first line starts Aug 11 @ 16:45. so this created ~480 entries between 1645 and 1652...
192.168.1.254 is the LAN address of the RG. I don't recall seeing this message before, but almost certainly not to this extent.
-
Hmm, seems like it might have rebooted? Unable to allocate local link info like that generally means pfSense doesn't have a IP in that subnet. So like it lost it's DHCP lease or the WAN went down.
Though I'd expect to see some monitoring ping failures if that was the case.
-
Aug 11 16:47:17 kernel arpresolve: can't allocate llinfo for 192.168.1.254 on mvneta2 Aug 11 16:47:20 php-fpm 836 /rc.newwanip: Removing static route for monitor [FIRST HOP] and adding a new route through [WAN GATEWAY] Aug 11 16:47:21 php-fpm 836 /rc.newwanip: Gateway, NONE AVAILABLE Aug 11 16:47:22 php-fpm 836 /rc.newwanip: Gateway, NONE AVAILABLE Aug 11 16:47:22 php-fpm 836 /rc.newwanip: IP Address has changed, killing states on former IP Address 0.0.0.0.also
Aug 11 16:49:41 php-fpm 836 /rc.newwanip: Netgate pfSense Plus package system has detected an IP change or dynamic WAN reconnection - 0.0.0.0 -> [WAN IP] - Restarting packages.does this look like the WAN went down and was recovered?
EDIT: extra info, the RG renews the DHCP lease for the pfsense appliance every 24 hours
-
Does the DHCP log show anything for the dhclient at that time?
It should renew without any interruption but clearly it lost an IP entirely at one point.
-
well, my DHCP log is flooded with hundreds of dhcpd entries so the log only goes back to the last hour. Most are DHCPREQUESTs and DHCPACK for LAN devices and their MAC addresses. also dhcp lease renew and ipv6 advertise address entries.
there are no entries for dhclient
-
You can filter that for the dhclient process:
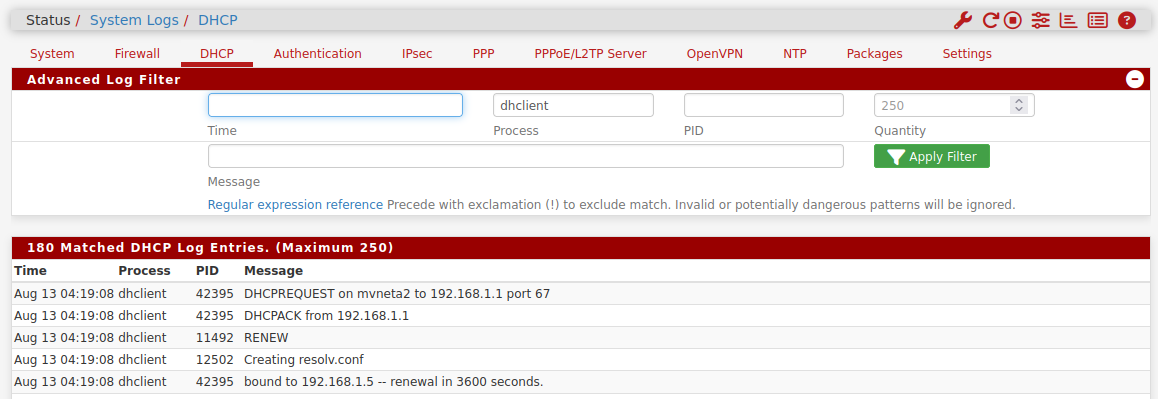
-
@stephenw10 thanks! attached are the dhclient logs (forum flagged the pasted logs as spam...)
dhcplogs.txt -
Hmm, well the only thing there is that at that point the logs show it pulled a private IP:
Aug 11 16:45:02 dhclient 34520 bound to 192.168.1.64 -- renewal in 15 seconds.That is usually a sign that the mode lost it's upstream connection and started handing out IPs itself. So if that did happen here that implies the line issues were reset by that upstream link reset/resync.
-
@stephenw10 can you please clarify, do you mean it's a sign that the RG lost its upstream connection?
and by line issues, do you mean att -> my house ONT, ONT -> RG, or RG -> pfsense?
if the RG is handing out IPs itself, does that create a problem? (i believe it's possible for me to disable DHCP server in the RG if that could be the source of the issues...) it hasn't handed out any IPs except passing the WAN IP to pfsense.

-
I mean something upstream of the AT&T router/gateway. Those usually only hand out private IPs themselves when they can't connect to the upstream server.
-
@stephenw10 thanks, sorry do you consider upstream in the direction of the ONT or in the direction of my pfsense firewall
-
Yes sorry in the direction of the ONT.
-
@stephenw10 below is my gateway monitoring and i'm definitely experiencing client-side performance issues as of today (random stuff like Amazon loading, Twitch loading, Youtube thumbnails delayed load, etc.)
pings to google and cloudflare as well as facebook, google, twitter all idle around 20+ms (higher than normal) but often spike to 60+ ms.
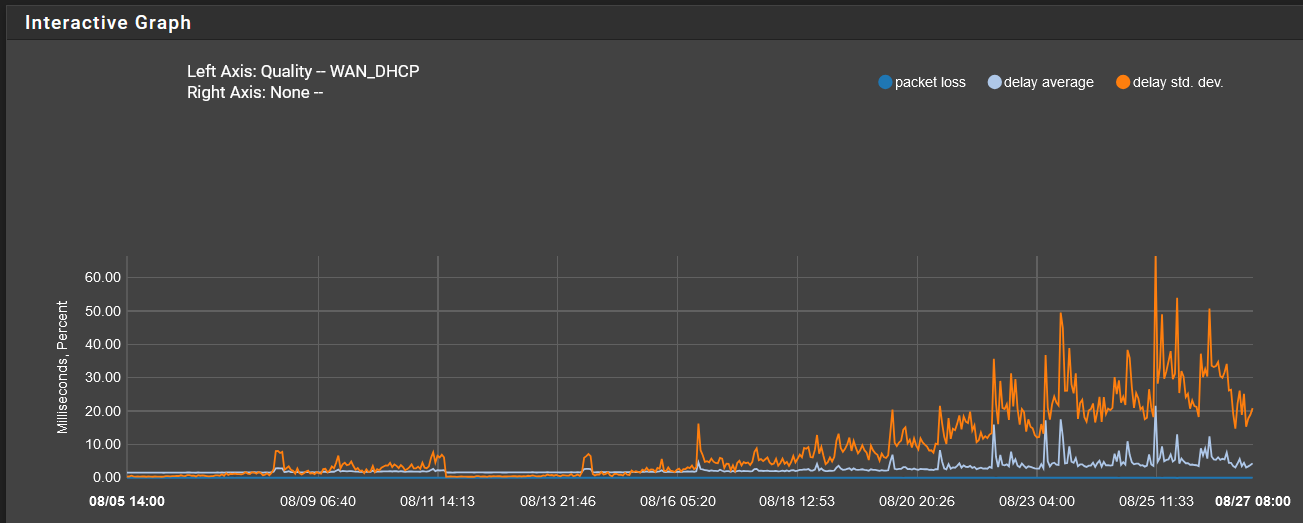
Going to pull the ethernet from 3100 -> RG, monitor, and update the thread.
-
pulling ethernet from:
- 3100 -> RG: no effect
- RG -> ONT: no effect
pulling power from ONT: no effect
restart RG via the web UI: appears to reset the issuealso definitely had gateway monitoring alarms leading up to this morning.