High interrupts on WAN/LAN interfaces?
-
Indeed, managed to get that working, and, I guess predictably, loss drops off when almost nothing is running across the (old, wired) WAN link:
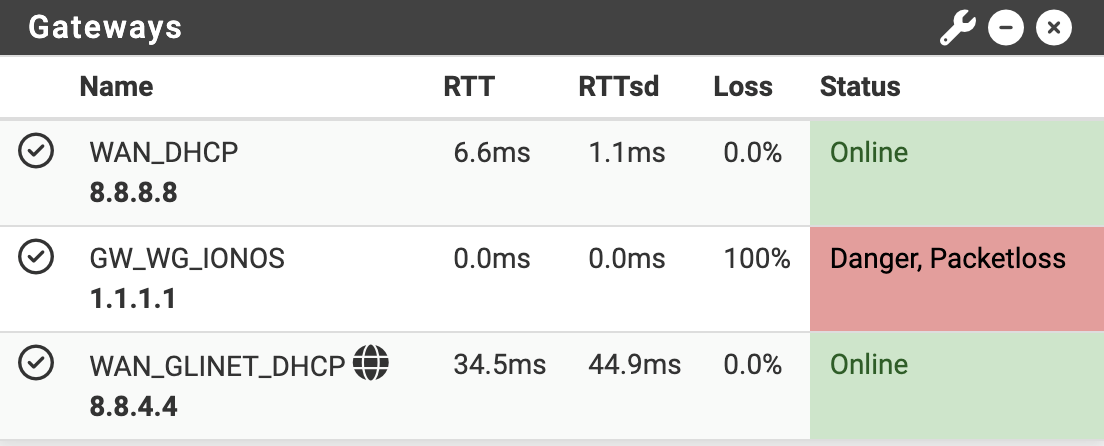
-
And actually, I take that back...
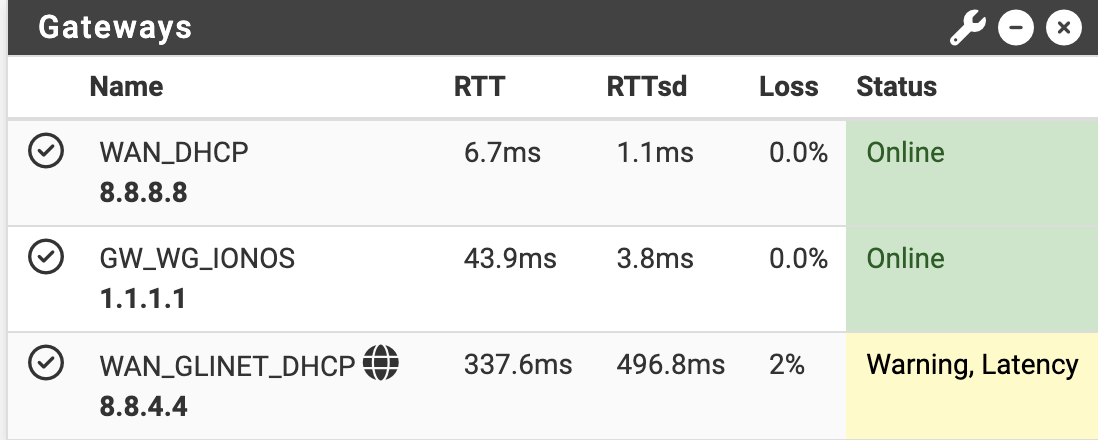
No reason to be seeing loss on that link (admittedly, it is connected via my neighbor next door, but I'm on it via the secondary router on a loss-free VoIP call) so I'm beginning to think it is, again, just an issue with this Topton box somehow... -
If it is a local issue you would still loss when it's monitoring just the local gateway IP rather than 8.8.4.4.
-
I had a similar issue when going from an older Qotom box to my current 'Hunsn' CWWK box with 6 i226v Intel network ports. I had set it up and just expected it to work correctly once I reassigned the network ports, but I had several 'packet loss' issues a day at a minimum. Working from home using ZOOM phone, calls would drop, Citrix would drop... ugg. I set the WAN on a different port, issue followed the WAN. Never had this issue on any other port (vlans on them) just the one connected to the Spectrum cable modem. I have a limiter setup and decided to tweak it being I am on a new device with different NICs, so read up on the 'latest recommendations' but they didn't work. Can't set PASS, have to set it to 'MATCH' for it to work at all, and someone also mentioned not to set ECN ON so I set both accordingly. Then I noticed, on the main STATUS page, NTP status, that time was off and it wasn't synching (sorry can't remember the exact verbiage) so I went to NTP to look. I had left the 4 PFSense pools and had added 4 NTP.ORG pools. I started thinking... they are pools, maybe I shouldn't put too many here, and left just one NTP.ORG pool and 3 PFSense pools, with only 2 pools checked. Now the NTP widget on the status page shows I am connected to a pool server and the time is synched. I did also zip tie a fan on the side of my janky Spectrum cable modem as it gets quite warm. Bingo NO MORE DROPS. I don't get it.
Some have said on other forums that the power supply that comes with these are sketchy so I had bought another online and had used it from the beginning, but switched it back at some point (don't remember if it was before or after my issues resolved). The one mine came with is 'Dajing' branded and is the same one that my old Qotom came with and it worked fine on that router.
Hope some bit of my ramblings help you out but I couldn't go a day without at least 3 periods of drops, that could last from 10 seconds to a minute or more. Maybe I should have 'started new' with settings instead of importing and fixing, but I really didn't want to start over...
-
@stephenw10 I have tried that, repeatedly, to no avail. However, I went away for a holiday and came back to see my graphs nearly entirely clean (up to .5% loss, occasionally, but I'll take that as within the bounds of reasonable). However, my download speeds were capped at 35Mbps, which struck me as odd. It seems, just before I left, I added a limiter (950 down, 35 up on my 1000/40 circuit), but I applied it on a LAN to any rule so I guess it was backwards. Reapplied it in the other direction and stable circuit stayed but my downloads jumped back to 920+:

Since it seems this fixed it, what can I do to streamline/better setup this rule:
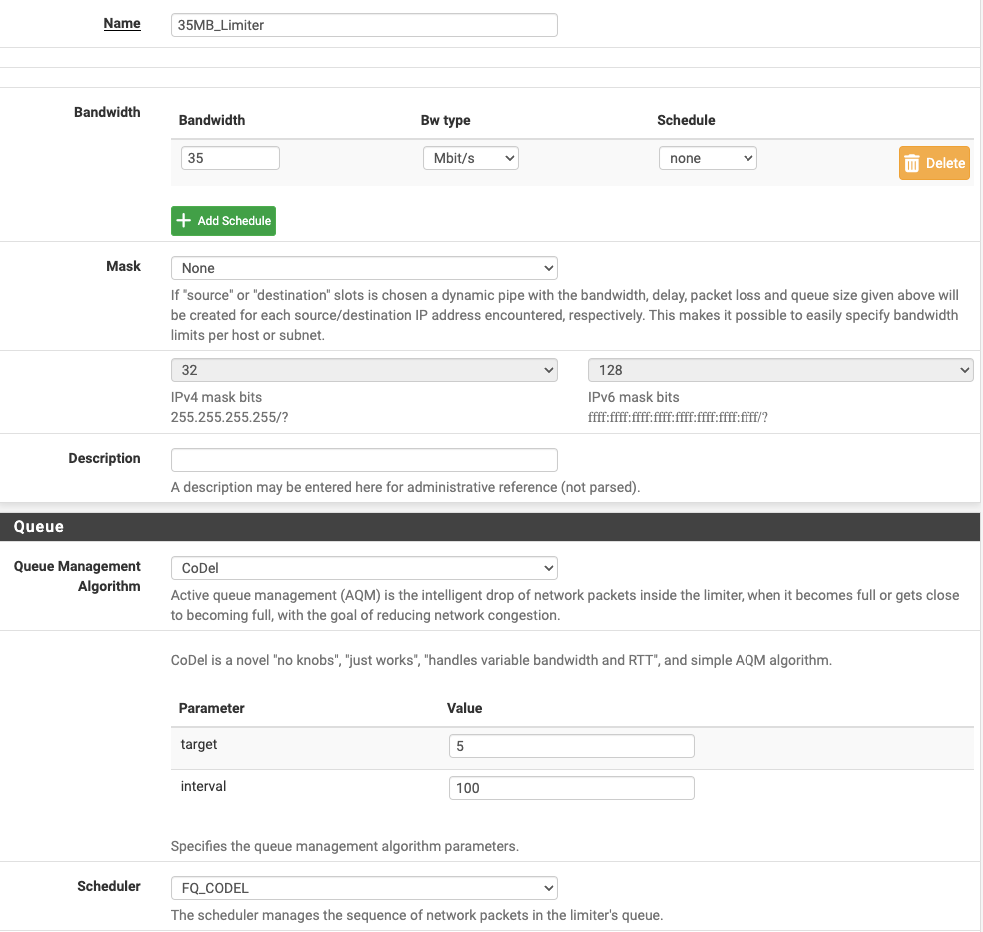
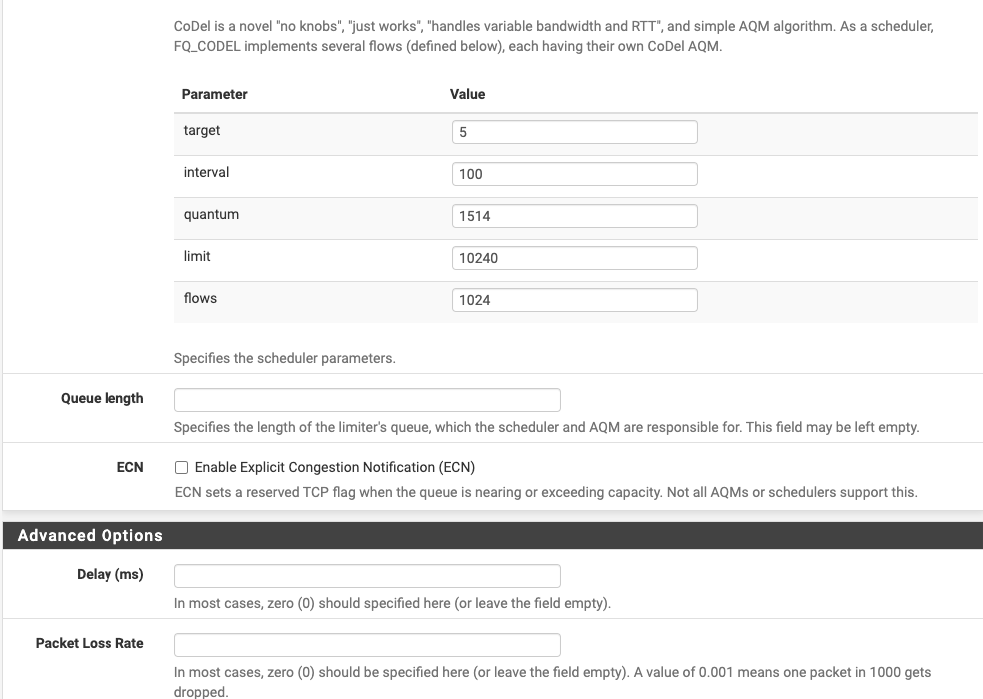
I also imagine I should be applying this to a floating rule, not on the LAN? Does that just get applied to WAN traffic in or out with that limiter applied in the opposite direction?
-
Ok, further update. That did not, indeed, fix things, but it added a few curious data points to my issue:
- I have both a Plex server and internal host that is being explicitly routed out a Wireguard GW group down 3 WG tunnels
- When I'm not home the latter is not being used at all
- When I wasn't at home the issue wasn't there
- There doesn't seem to be a connection between whether I'm using the WG tunnel and whether the connection has issues, but when I wasn't at home it wasn't a problem.
I've flipped the rule back to the backwards 30/950 to no avail, though, so it does seem that, somehow, when I'm home things break and when I'm away things don't. I have absolutely no idea how that's related...
-
And one more question while I'm at it. My inside IP space is 172.18.122.0/24, outside a public IP via bridge mode through the FW. But pFTop shows me 192.168.1 addresses as destinations-what could be causing this...?
pfTop: Up State 68-106/251928, View: default, Order: none, Cache: 10000 14:20:46 PR DIR SRC DEST STATE AGE EXP PKTS BYTES udp In 172.18.122.20:41641 176.58.90.147:3478 MULTIPLE:MULTIPLE 243:28:59 00:11:30 20812 1332088 tcp Out xx.xx.xx.xx:16606 192.168.1.64:443 SYN_SENT:CLOSED 00:21:00 00:39:00 1 44 udp Out xx.xx.xx.xx:12279 176.58.90.147:3478 MULTIPLE:MULTIPLE 243:28:59 00:11:30 20452 1308952 tcp In 172.18.122.12:47417 192.168.1.28:443 CLOSED:SYN_SENT 00:21:00 00:39:00 1 44 -
Looks like an internal device trying to reach things in the 192.168.1.X subnet and getting routed out of the WAN as the default route.
-
@stephenw10 Shiiiiiiiiiit...so I have a Raspberri Pi running MagicMirror on it with an ARP sensing program to see if my phone is online in order to turn the screen on. When I turn off the MagicMirror program (but leave the Raspberry Pi on) the packet loss stops. Restarted the MagicMirror program after putting in an explicit block rule from LAN > 192.168.1.0/24 and the loss entirely clears up. How in the heck could a service running on a Raspberry Pi, connected to wireless that's getting dumped onto the WAN with packets destined for 192.168.1.0/24 causing packet loss on my provider router!? The fact that I wasn't home explains (somewhat) why the loss wasn't occuring when I wasn't home, though the underlying MagicMirror program should have been running anyway, the screen was just off, so heaven knows...
-
Causing some sort of ARP poisoning perhaps? That's quite a significant impact! Good catch though,
-
Odd if so, as, again, I'm not using 192.168.1.0/24 internally. But regardless, adding the explicit deny from LAN > * to 192.168.1.0/24 has fixed the issue, now to sort out what on that Raspberry Pi is running sweeps searching for things...
-
A day later and, indeed, can confirm one of the modules in the MagicMirror was doing a nmap sweep of 192.168.1.0/24 (legitimately, just not clear why the static IP range) confirmed by shutting the module off and temporarily corrected by putting an explicit block rule on LAN > * for 192.168.1.0/24. Still not quite clear what, exactly, loads of requests on :80, :443, ICMP to 192.168.1.0/24 hosts being dumped out on my ISP router ended up doing. Likely, though, the fact that my router was in bridge mode contributed, though I never tried in route/NAT mode, so I can't be sure. Regardless, it's fixed now, but what a nightmare! Thanks @stephenw10 for all the patient help, even if it didn't end up being a PFSense issue in the end! At least it's fairly well documented here so hopefully anyone with similar issues in future will have a reference for other potential problems...