2x pfsense 24.11 hard crashes in under a week - Netgate 1537
-
We have had two of our netgate 1537s crash in under a week with the same symptoms. Posting here incase anybody else runs into something similar since we have no explanation after >140 days of uptime on both units. Netgate support is stumped and has no explanation.
We have two identical netgate 1537s in a HA pair. A week ago our standby firewall went non-unpingable, either via it's LACP connections or via the crossover cable between the two firewalls. Physical console via VGA connector/USB keyboard showed months old system messages, but otherwise no response to keyboard input. Numlock would go on/off when pressed. Control-Alt-Delete did not respond.
When the firewall went offline our core switch suspended the port:
Jul 23 21:01:18 sw-core sw-core-1: Jul 24 01:01:16.729: %EC-5-UNBUNDLE: STANDBY:Interface Te1/2/1 left the port-channel Po21
Jul 23 21:01:19 sw-core sw-core-1: Jul 24 01:01:17.953: %EC-5-UNBUNDLE: STANDBY:Interface Te2/2/1 left the port-channel Po21
Jul 23 21:01:19 sw-core sw-core-1: Jul 24 01:01:19.474: %EC-5-UNBUNDLE: Interface Te1/2/1 left the port-channel Po21
Jul 23 21:01:21 sw-core sw-core-1: Jul 24 01:01:20.507: %EC-5-UNBUNDLE: Interface Te2/2/1 left the port-channel Po21
Jul 23 21:01:25 sw-core sw-core-1: Jul 24 01:01:24.759: %EC-5-L3DONTBNDL2: Te1/2/1 suspended: LACP currently not enabled on the remote port.
Jul 23 21:01:27 sw-core sw-core-1: Jul 24 01:01:26.059: %EC-5-L3DONTBNDL2: Te2/2/1 suspended: LACP currently not enabled on the remote port.Although the console appeared unresponsive, it does seem like the system was partially alive. This was found in the syslog after we hard power cycled, and is consistent with the time period we had the crash cart plugged in mashing random keys/enter, before hitting the reset button:
Jul 24 00:18:02 fw1 login[31213]: login on ttyv0 as root
Jul 24 00:18:03 fw1 login[44763]: login on ttyv0 as root
Jul 24 00:18:06 fw1 login[56358]: login on ttyv0 as root
Jul 24 00:18:07 fw1 login[70702]: login on ttyv0 as root
Jul 24 00:18:40 fw1 login[88262]: login on ttyv0 as root
Jul 24 00:18:42 fw1 login[99619]: login on ttyv0 as root
Jul 24 00:18:43 fw1 login[11870]: login on ttyv0 as root
Jul 24 00:18:52 fw1 login[72783]: login on ttyv0 as root
Jul 24 00:18:54 fw1 login[85355]: login on ttyv0 as root
Jul 24 00:19:13 fw1 login[12470]: login on ttyv0 as root
Jul 24 00:19:14 fw1 login[25801]: login on ttyv0 as root
Jul 24 00:19:20 fw1 syslogd: exiting on signal 15Uptime was 141 days and 144 days for the units. Presumably from when we upgraded to 24.11.
The units are in a colo facility, we see no temperature deviations during the time. The primary and secondary units are plugged into different power sources. We do not have IMPI configured, when we can get physical access to the facility we'll likely see if there's anything in the IMPI logs. I do doubt this is a hardware issue though given the unit was capable of logging to syslog/disk.
The units successfully failed over, however not having any explanation gives us concern about the reliability of PfSense or the ability to diagnose a crash. I can't think of a time when I've lost a cisco firewall and didn't have enough info w/ Cisco TAC to figure out the cause (mostly software bugs). We have another identically configured facility with similar uptimes and has not shown this issue yet.
A possible shot in the dark, we've been bit by the bsnmpd leaking memory bug pretty badly. Supposedly 24.11 fixed this, but as we've reported to netgate, the upgrade fixed the FD leak, but not the memory leak. Both units probably at some point OOMED and ran out of swap before the kernel killed bsnmpd to survive. We have since automated a bsnmpd restart weekly. We would have deployed this auto restart 3 months ago atleast. Perhaps we should have rebooted the units before now, but they were solid for probably 6 months since we realized bsnmpd was still leaking.
Any help appreciated!
Thanks,
-Joe -
@joekislo said in 2x pfsense 24.11 hard crashes in under a week - Netgate 1537:
Both units probably at some point OOMED and ran out of swap before the kernel killed bsnmpd to survive
As long as disk (partition) space isn't an issue, these kind of events can be found in the system log.
For memory (RAM), as soon as the system is running again, look at Status > Monitoring ans select System => Memory. -
This post is deleted! -
@Gertjan Gertjan No evidence of OOMs before the event, disk space was plenty good as well. FWIW the OOMs were months ago, and I sent all the details to Netgate. Memory has been stable since we started the weekly bnsmpd restarts.
The dip is the unit hard reset.
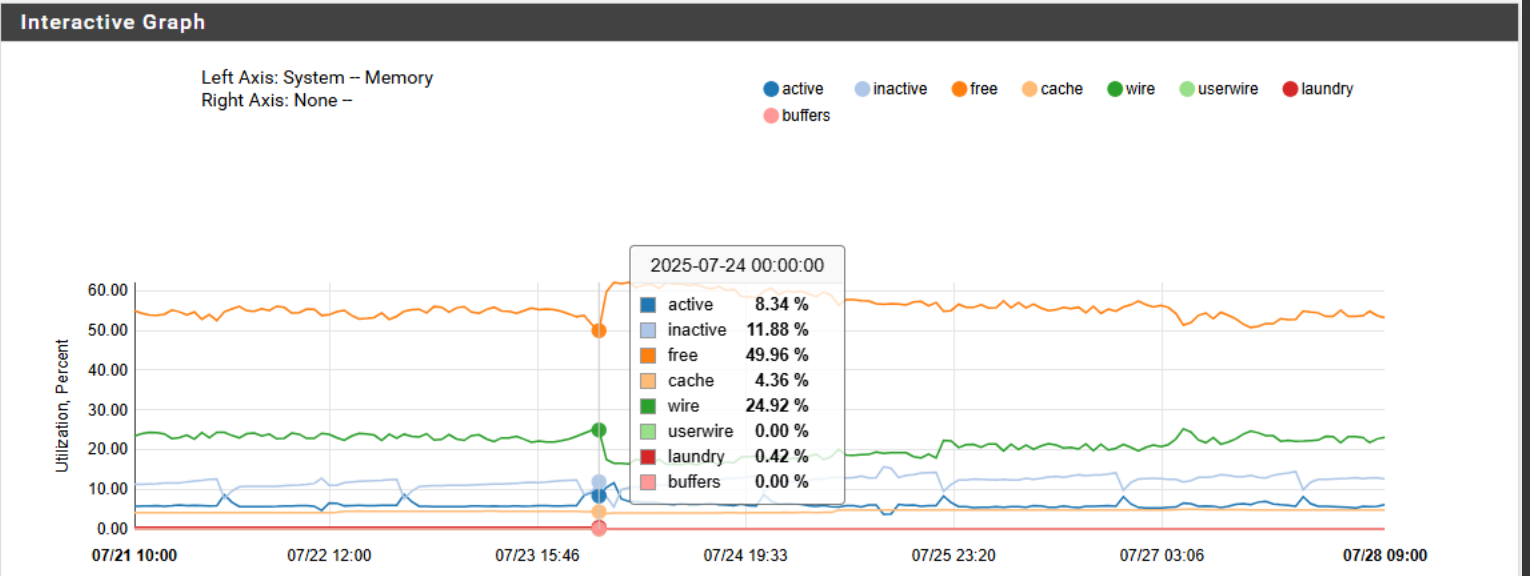
-
Did you try entering
ctl+tat the console when it wasn't responding? That can sometimes show output when nothing else will.Has this only happened once? On each node?
-
@joekislo said in 2x pfsense 24.11 hard crashes in under a week - Netgate 1537:
Jul 24 00:19:20 fw1 syslogd: exiting on signal 15
Just to confirm you think this entry is when you hit the Reset button to reboot?
We have a 4200 that put itself in standby (according to its LED) on its own, and logged that at the time, like it shut itself down. Haven't seen that anywhere/anytime else, though.
-
@SteveITS Was there anything in the logs regarding going to Standby? I didn't see any power event logged.
-
@jcleaves Nothing mentioned standby, shutdown, etc., in fact nothing for the previous hour before the "exiting." However we were running a RAM disk on it which we normally do. But the 4200 has a standby LED pattern. Our occurrence was in early June. TAC had us reinstall it.
Edit: I understand our situation may not be relevant here.
-
If you press the ATX power button that's what you would see logged:
Jul 28 21:57:35 php-fpm 8456 /index.php: Successful login for user 'admin' from: 172.21.16.8 (Local Database) Jul 29 00:21:11 syslogd exiting on signal 15 Jul 29 00:23:07 syslogd kernel boot file is /boot/kernel/kernel Jul 29 00:23:07 kernel ---<<BOOT>>--- Jul 29 00:23:07 kernel Copyright (c) 1992-2024 The FreeBSD Project. Jul 29 00:23:07 kernel Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994You can disable that by setting the sysctl
hw.acpi.power_button_state=none -
@stephenw10 In our case a button was not pressed, per the one person in the office. It would be nice if it logged a "button push" event.
-
@stephenw10 This was definitely not a button push on ours either. Both units are in locked cabinets in a colo. Any access to the facility is logged.
@SteveITS As for it going to standby or hibernating, the person who went on site the LEDs were normal. Nothing indicating a state change or issue.