Traffic Shaping Performance issues
-
The answers to your questions are out there. Searching this forum & Google can answer everything you are asking.
Sorry for the callousness, but I spent ~9 months researching traffic-shaping (mostly relating to pfSense) and I know for a fact that you can find the answers if you search & read. If, after exhaustively researching traffic-shaping, you still have an unsolved problem, please ask. I (and very likely others) will be interested in solving your problem.
but otherwise, much smarter & more educated people have already answered your questions. You simply need to find those answers. ermal's posts in this forum are a favorite resource of mine, but most of his topics may be too advanced. Easy solutions are rare. :)
Well, I did do some searching, and I THINK I've come up with the following, but allow me to bounce it off of you guys to amke sure:
In the "by interface" section under Traffic Shaping set both LAN and WAN to codelq
Set bandwidth on WAN interface to ~97% of upstream bandwidth
Set bandwidth on LAN interface to ~97% of downstream bandwidth.Now, I also read something interesting about maybe seeing better results of fair distribution of bandwidth (because apparently codel does this poorly) by setting the primary to fairq, and using codel in a child queue.
I may have to try this.
It would seem making edits to the pfsense Traffic Shaping wiki page with some of this information would be good. That's where I checked before I posted this thread, but it was lacking. Peoples eyes glaze over if they have to read through many-page forum threads before finding that needle in a haystack that answers their question. I'd do it myself, but I'm not convinced I have a complete enough understanding of how it works yet to do so.
-
You would need to share some detailed, repeatable steps that consistently show that "kbit" is actually "bit", then someone will either confirm the bug (and fix it) or have further questions.
I worked on this but right now I cannot reproduce this anymore. Originally the results were differing form the configured values by about factor 10. This is not the case in my setup anymore now.
I'll keep an eye on this.
-flo-
-
You would need to share some detailed, repeatable steps that consistently show that "kbit" is actually "bit", then someone will either confirm the bug (and fix it) or have further questions.
I worked on this but right now I cannot reproduce this anymore. Originally the results were differing form the configured values by about factor 10. This is not the case in my setup anymore now.
I'll keep an eye on this.
-flo-
Always reset the states, or even just restart pfSense, when playing with traffic-shaping.
Personally, my first few months playing with QoS & pfSense included lots of "why is it doing that?!" situations. Like you, I even thought that the bit/kbit/mbit might be inaccurate. Though, after lots reading & testing, eventually my configurations started to perform as I predicted.
-
The answers to your questions are out there. Searching this forum & Google can answer everything you are asking.
Sorry for the callousness, but I spent ~9 months researching traffic-shaping (mostly relating to pfSense) and I know for a fact that you can find the answers if you search & read. If, after exhaustively researching traffic-shaping, you still have an unsolved problem, please ask. I (and very likely others) will be interested in solving your problem.
but otherwise, much smarter & more educated people have already answered your questions. You simply need to find those answers. ermal's posts in this forum are a favorite resource of mine, but most of his topics may be too advanced. Easy solutions are rare. :)
Well, I did do some searching, and I THINK I've come up with the following, but allow me to bounce it off of you guys to amke sure:
In the "by interface" section under Traffic Shaping set both LAN and WAN to codelq
Set bandwidth on WAN interface to ~97% of upstream bandwidth
Set bandwidth on LAN interface to ~97% of downstream bandwidth.Now, I also read something interesting about maybe seeing better results of fair distribution of bandwidth (because apparently codel does this poorly) by setting the primary to fairq, and using codel in a child queue.
I may have to try this.
It would seem making edits to the pfsense Traffic Shaping wiki page with some of this information would be good. That's where I checked before I posted this thread, but it was lacking. Peoples eyes glaze over if they have to read through many-page forum threads before finding that needle in a haystack that answers their question. I'd do it myself, but I'm not convinced I have a complete enough understanding of how it works yet to do so.
You have it pretty right. My upload connection is ~760Kbit link-rate, with a real-world bitrate of ~666Kbit, so I set my queue to 640Kbit. My ADSL is very stable, so 640 works well enough.
CODELQ is dirt simple, but yeah, there is no fair queueing. You can use either HFSC (Hierarchical Fair Service Curve) or FAIRQ and select the "CoDel Active Queue" check-box to get both fair queueing & codel.
Yeah… searching the forums can be annoying, but you gotta do it. We (pfSense forumites) are not very responsive when it's obvious that a poster has not searched for an answer.
-
The answers to your questions are out there. Searching this forum & Google can answer everything you are asking.
Sorry for the callousness, but I spent ~9 months researching traffic-shaping (mostly relating to pfSense) and I know for a fact that you can find the answers if you search & read. If, after exhaustively researching traffic-shaping, you still have an unsolved problem, please ask. I (and very likely others) will be interested in solving your problem.
but otherwise, much smarter & more educated people have already answered your questions. You simply need to find those answers. ermal's posts in this forum are a favorite resource of mine, but most of his topics may be too advanced. Easy solutions are rare. :)
Well, I did do some searching, and I THINK I've come up with the following, but allow me to bounce it off of you guys to amke sure:
In the "by interface" section under Traffic Shaping set both LAN and WAN to codelq
Set bandwidth on WAN interface to ~97% of upstream bandwidth
Set bandwidth on LAN interface to ~97% of downstream bandwidth.Now, I also read something interesting about maybe seeing better results of fair distribution of bandwidth (because apparently codel does this poorly) by setting the primary to fairq, and using codel in a child queue.
I may have to try this.
It would seem making edits to the pfsense Traffic Shaping wiki page with some of this information would be good. That's where I checked before I posted this thread, but it was lacking. Peoples eyes glaze over if they have to read through many-page forum threads before finding that needle in a haystack that answers their question. I'd do it myself, but I'm not convinced I have a complete enough understanding of how it works yet to do so.
You have it pretty right. My upload connection is ~760Kbit link-rate, with a real-world bitrate of ~666Kbit, so I set my queue to 640Kbit. My ADSL is very stable, so 640 works well enough.
CODELQ is dirt simple, but yeah, there is no fair queueing. You can use either HFSC (Hierarchical Fair Service Curve) or FAIRQ and select the "CoDel Active Queue" check-box to get both fair queueing & codel.
Yeah… searching the forums can be annoying, but you gotta do it. We (pfSense forumites) are not very responsive when it's obvious that a poster has not searched for an answer.
Hmm, so I finally got around to working on this today.
I did several speed tests in a row to establish downstream at about 152Mb/s and upstream at about 161Mb/s.
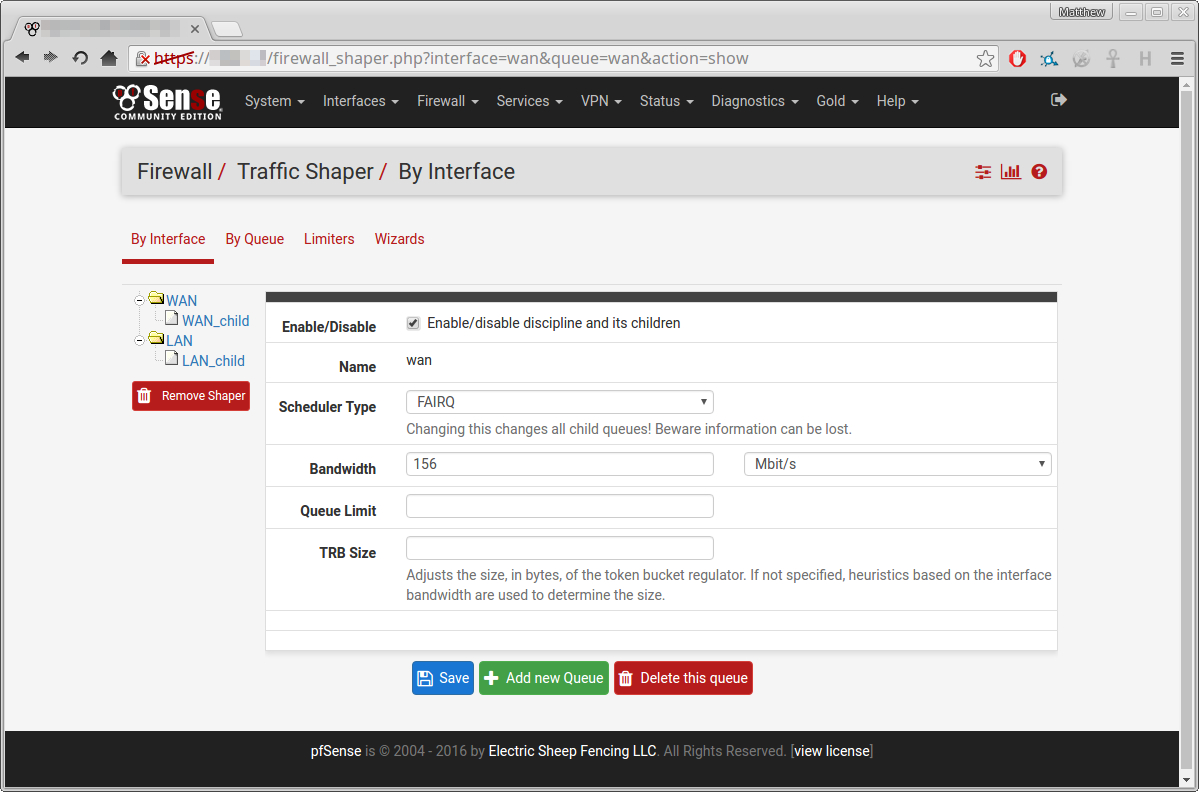
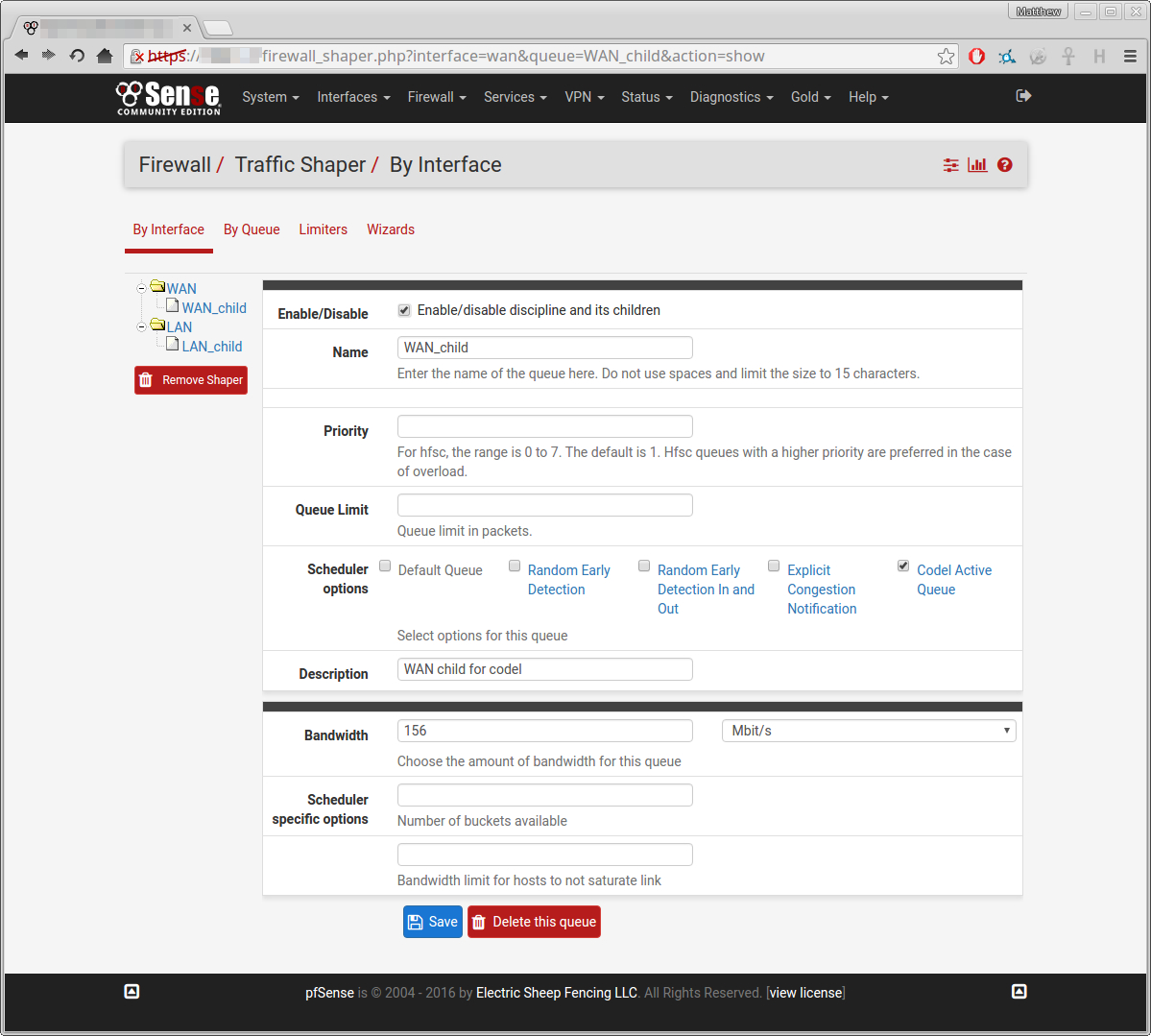
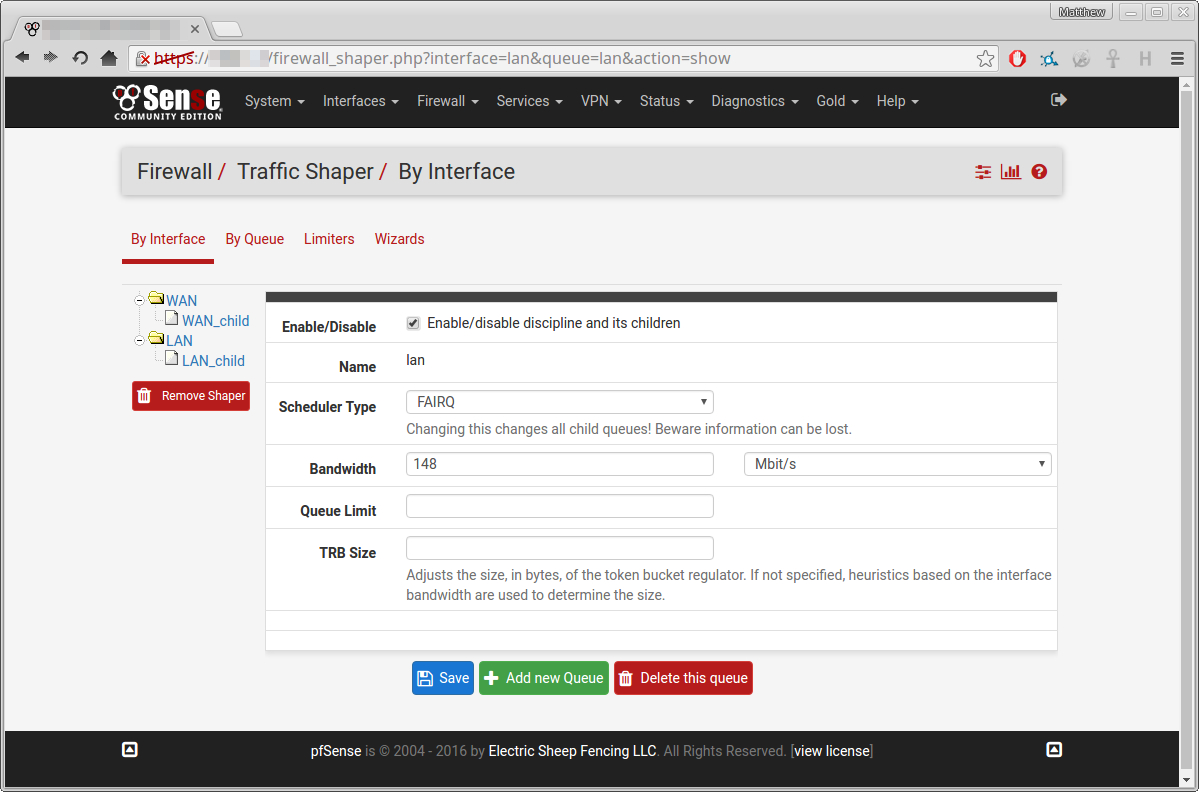
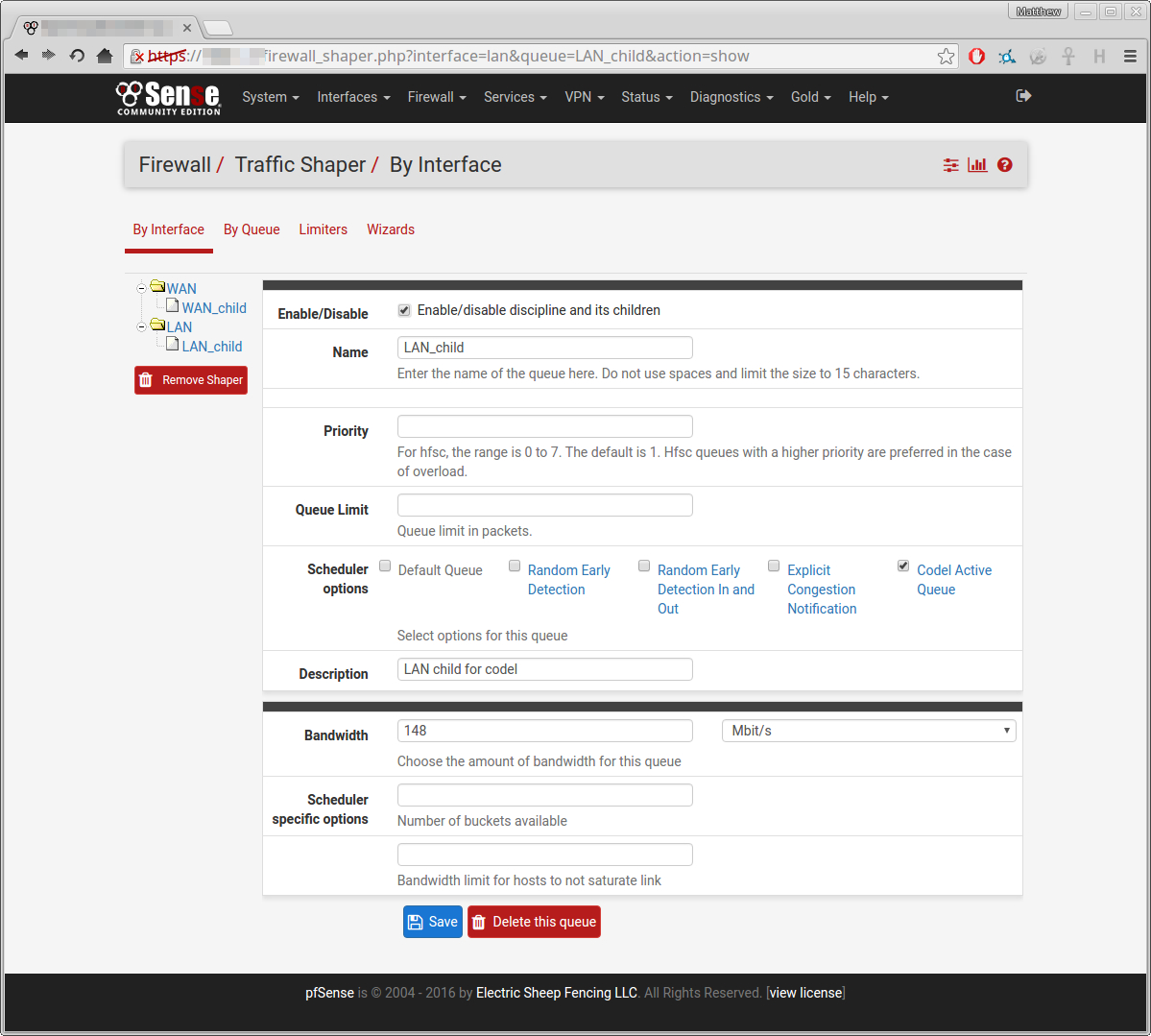
Here is how I set it up: (click for full size)
After which I saved all my settings, and made sure to reload the firewall rules.
Then, just as a sanity check I ran another speed test:

This suggests that it isn't working, as it is allowing this single process to exceed the bandwidth limits (the 148 and 156 respectively)
Any idea what I might be doing wrong?
Thanks,
Matt -
Did you reset the firewall states?
-
Did you reset the firewall states?
Yeah, the box at the top of the window after you apply the settings tells you to click here to reload the firewall rules in order for it to become effective. I did that.
Is there anything in addition to that I should be doing?
-
Did you reset the firewall states?
Yeah, the box at the top of the window after you apply the settings tells you to click here to reload the firewall rules in order for it to become effective. I did that.
Is there anything in addition to that I should be doing?
Try a temporary bitrate (like 20Mbit) that will not be as easily confused with your internet connection's bitrate. The official pfSense wiki's data should work.
-
Try a temporary bitrate (like 20Mbit) that will not be as easily confused with your internet connection's bitrate. The official pfSense wiki's data should work.
Good idea, I'll try that, thank you.
Meanwhile, could these alerts be related?
Error occurred SHAPER: no default queue specified for interface wan. The interface queue will be enforced as default. @ 2016-05-02 04:09:45 SHAPER: no default queue specified for interface lan. The interface queue will be enforced as default. @ 2016-05-02 04:09:46 SHAPER: no default queue specified for interface wan. The interface queue will be enforced as default. @ 2016-05-02 04:09:47 SHAPER: no default queue specified for interface lan. The interface queue will be enforced as default. @ 2016-05-02 04:09:48 SHAPER: no default queue specified for interface wan. The interface queue will be enforced as default. @ 2016-05-02 04:09:49 SHAPER: no default queue specified for interface lan. The interface queue will be enforced as default. @ 2016-05-02 04:09:50 -
You need to set one of your queues to be the default. All states must be put into a queue, if you don't supply one, PFSense will, and you won't be able to control it.
-
You need to set one of your queues to be the default. All states must be put into a queue, if you don't supply one, PFSense will, and you won't be able to control it.
Yeah, it looks like that might have been it. I selected to make the child queues above the default, and I saw an effect. Unfortunately it was more of an effect than I was hoping to see. With this configuration I was down to 138/150mbit.
At first I thought the fairq interface queue might be to blame, but when I deleted the child queues and set the interface queues to "codelq" i had the same performance loss. Maybe this is how it works? I'm not sure I want to give up THAT much bandwidth though.
-
You need to set one of your queues to be the default. All states must be put into a queue, if you don't supply one, PFSense will, and you won't be able to control it.
Yeah, it looks like that might have been it. I selected to make the child queues above the default, and I saw an effect. Unfortunately it was more of an effect than I was hoping to see. With this configuration I was down to 138/150mbit.
At first I thought the fairq interface queue might be to blame, but when I deleted the child queues and set the interface queues to "codelq" i had the same performance loss. Maybe this is how it works? I'm not sure I want to give up THAT much bandwidth though.
The interface bitrate needs to be lower than your real-world maximum, so tune it as close as possible.
-
You're set to 148Mb and getting 138Mb. 93% of your total bandwidth is pretty close. In theory, you cannot go above 148, so your average must be below it. The real question is what your bufferbloat is at. Check dslreports.com's speedtest. You can always increase your rates to see how it affects your traffic. The more stable your internet connection, the closer to 100% you can get without getting blips of latency or packetloss.
-
You're set to 148Mb and getting 138Mb. 93% of your total bandwidth is pretty close. In theory, you cannot go above 148, so your average must be below it. The real question is what your bufferbloat is at. Check dslreports.com's speedtest. You can always increase your rates to see how it affects your traffic. The more stable your internet connection, the closer to 100% you can get without getting blips of latency or packetloss.
How do we define stable in this case?
The last mile service seems to be very stable. Anything within my ISP's network will saturate my links without a problem. Depending on where I cross my ISP's networks edge routers, I'll have anywhere from excellent performance to OK performance, but the sum total of multiple connections from different locations seems to pretty much always max out my connection, at ~152Mbit down and ~161 Mbit up (advertised as 150/150).
Using Speedtest.net I tested all the test points in my state and a few in nearby neighboring ones (n~20). The fastest one is not on my ISP's network, but on an adjacent one, and it is the one that consistently seems to give me 152/161Mbit, the highest I get anywhere. I can make the figure go down by intentionally choosing less fast test servers, but this suggests that I am at least getting a consistent 152/161 total from all sources down my last mile pipe.
So, individual connections may vary over time depending on routing and which peering point they cross to get where they are going, but the sum total is incredibly stable.
Since traffic shaping is all about balancing multiple connections and making them able to coexist, by guess would be that the last mile total is the figure that is the most interesting for traffic shaping purposes, correct?
-
How do we define stable in this case?
Loosely. Your description makes it sound "stable". TCP can be finicky, and small blips of loss could reduce your average quite a bit. In my case I say my connection is stable because I have a 100Mb connection, and if I don't do any shaping on my end, my sustained single TCP flow can maintain 99.5Mb/s +- 0.25Mb/s when looking RRD's 1min avg. By "maintain", I mean for hours on end during peak hours. I actually shape to 98.5Mb/s on my download and I get about 95-96Mb/s while staying around 1ms of bloat.
An interesting tid-bit about my ISP is they don't shape my Ethernet port, they shape at their router. Their Cisco router, which is very new and shiny and full of 100Gb+ ports, does not police the bandwidth, but kind of "jitters" it, which works really really well. Instead of getting the standard TCP saw-tooth, I get their very mild fluctuation of +-0.1Mb/s while averaging my 100Mb for the most part. They used to use the built in ONT rate limiter which is a strict policer and gave the TCP saw-tooth pattern, which hurt my average performance by strictly dropping packets the instant my link tried to go over the provisioned rate.
The TCP caw-tooth pattern is bad for average throughput during saturation with many flows. A dumb FIFO buffer causes this, and your max throughput will approach ~80%. With anti-buffer bloat, you can start to approach 95%. It's possible your ISP can supply you a "stable" 152Mb/s when averaged over a large window because of large buffers, but at any given moment, may be "unstable", which could hurt your performance when you're also doing your own shaping and setting yet an additional cap.
Since traffic shaping is all about balancing multiple connections and making them able to coexist, by guess would be that the last mile total is the figure that is the most interesting for traffic shaping purposes, correct?
Correct. The main issue of bufferbloat is to concern yourself about the bloat on your connection to your ISP, not the possible N peering routes your ISP may have with congestion.
-
How do we define stable in this case?
Loosely. Your description makes it sound "stable". TCP can be finicky, and small blips of loss could reduce your average quite a bit. In my case I say my connection is stable because I have a 100Mb connection, and if I don't do any shaping on my end, my sustained single TCP flow can maintain 99.5Mb/s +- 0.25Mb/s when looking RRD's 1min avg. By "maintain", I mean for hours on end during peak hours. I actually shape to 98.5Mb/s on my download and I get about 95-96Mb/s while staying around 1ms of bloat.
An interesting tid-bit about my ISP is they don't shape my Ethernet port, they shape at their router. Their Cisco router, which is very new and shiny and full of 100Gb+ ports, does not police the bandwidth, but kind of "jitters" it, which works really really well. Instead of getting the standard TCP saw-tooth, I get their very mild fluctuation of +-0.1Mb/s while averaging my 100Mb for the most part. They used to use the built in ONT rate limiter which is a strict policer and gave the TCP saw-tooth pattern, which hurt my average performance by strictly dropping packets the instant my link tried to go over the provisioned rate.
The TCP caw-tooth pattern is bad for average throughput during saturation with many flows. A dumb FIFO buffer causes this, and your max throughput will approach ~80%. With anti-buffer bloat, you can start to approach 95%. It's possible your ISP can supply you a "stable" 152Mb/s when averaged over a large window because of large buffers, but at any given moment, may be "unstable", which could hurt your performance when you're also doing your own shaping and setting yet an additional cap.
Since traffic shaping is all about balancing multiple connections and making them able to coexist, by guess would be that the last mile total is the figure that is the most interesting for traffic shaping purposes, correct?
Correct. The main issue of bufferbloat is to concern yourself about the bloat on your connection to your ISP, not the possible N peering routes your ISP may have with congestion.
Ahh, thanks for that, that is great info.
So how do you go about measuring buffer bloat? Just ping a known source (maybe the first hop outside my router in a traceroute?) and then load up the connection and see how the ping changes?
-
That is the simplest way without any external tools. DSLReports.com has a nice speedtest with a decent bufferbloat ability, which pretty much does what you said, except with websockets, which is technically less accurate than ICMP/UDP pings. It still gets within single millisecond precision and seems sane and reproducible, so I assume accurate.
-
That is the simplest way without any external tools. DSLReports.com has a nice speedtest with a decent bufferbloat ability, which pretty much does what you said, except with websockets, which is technically less accurate than ICMP/UDP pings. It still gets within single millisecond precision and seems sane and reproducible, so I assume accurate.
I checked out the DSLreports test. It is pretty good. I wish it would keep the max buffer bloat raw numbers for upstream and downstream rather than turn it into a grade though.
So, with codel turned on, I only get 139.5 down and 146.4 up, but my buffer bloat is non-existent, (1-2 ms if watching the live chart)
With codel disabled - however - I get 146.9 down and 163.6 up, but buffer bloat is horrific. ~80ms during download and ~225ms during upload.
So, the improved buffer bloat is what I was expecting, but at what cost? A loss of ~10Mbps up and down? That's more than some peoples entire connections… I wonder if it is worth it. I also wonder how I would perform with buffer bloat if I rather than using codel, just put a static bandwidth limit at the level of performance reported with codel on. I wonder if it is actually the codel that is helping, or just the fact that the bandwidth is less utilized that reduces the buffer bloat...
-
That is the simplest way without any external tools. DSLReports.com has a nice speedtest with a decent bufferbloat ability, which pretty much does what you said, except with websockets, which is technically less accurate than ICMP/UDP pings. It still gets within single millisecond precision and seems sane and reproducible, so I assume accurate.
I checked out the DSLreports test. It is pretty good. I wish it would keep the max buffer bloat raw numbers for upstream and downstream rather than turn it into a grade though.
So, with codel turned on, I only get 139.5 down and 146.4 up, but my buffer bloat is non-existent, (1-2 ms if watching the live chart)
With codel disabled - however - I get 146.9 down and 163.6 up, but buffer bloat is horrific. ~80ms during download and ~225ms during upload.
So, the improved buffer bloat is what I was expecting, but at what cost? A loss of ~10Mbps up and down? That's more than some peoples entire connections… I wonder if it is worth it. I also wonder how I would perform with buffer bloat if I rather than using codel, just put a static bandwidth limit at the level of performance reported with codel on. I wonder if it is actually the codel that is helping, or just the fact that the bandwidth is less utilized that reduces the buffer bloat...
CoDel itself should not make that big of a difference, especially if you are using the "Codel Active Queue" check-box with HFSC, FAIRQ, CBQ, or PRIQ.
If you are using CODELQ, tune your interfaces' bitrate.
Regardless, traffic-shaping limits your max bandwidth. Personally, I limit my upload to 98% of my maximum (which I find tolerable), but I forego any download traffic-shaping because my bufferbloat only grows to ~50ms (during saturation) from ~15ms (idle), so I prefer maximum download speed.
-
So, the improved buffer bloat is what I was expecting, but at what cost? A loss of ~10Mbps up and down? That's more than some peoples entire connections…
The loss of bandwidth is proportional to the stability of your connection. You may be "losing" 10Mb/s of your bandwidth to maintain a low bloat, but I only need to lose about 1.5Mb/s.
And when you say "at what cost", it almost sounds sarcastic because the cost is so low. So you lose 7% of your bandwidth, but now your ping will be between 80ms and 200ms lower during saturation of your connection. You can still play games. And some connections are latency sensitive, like HTTPS. With 11 round trips, a 200ms ping increase will take 2.2 seconds before your web page starts to download. With a 2ms ping, it will take 22ms. That's the difference between instant and twiddling your thumbs.