Intermittently Unresponsive in Hyper-V
-
Hmm, nothing shown even at the console directly?
If it seems completely unresponsive try sending 'ctl+t'. That can show a stalled process when nothing else does.
-
Just locked up after about 6 hours of being up. Short version: Restart PHP-FPM seems to get it back online without reboot. Before doing that:
- VM console is non-responsive. Close and reopen and it's responsive again
- SSH dropped but I was able to reconnect
- I'm typing here, but I get no ping response from the firewall and no ping response from 8.8.8.8
- ctrl-t = load: 3.52 cmd: sh 61905 [ttyin] 481.55r 0.00u 0.00s 0% 3000k
Systemlog snippet:
Aug 17 18:31:00 firewall sshguard[45905]: Exiting on signal. Aug 17 18:31:00 firewall sshguard[27826]: Now monitoring attacks. Aug 17 18:49:00 firewall sshguard[27826]: Exiting on signal. Aug 17 18:49:00 firewall sshguard[14756]: Now monitoring attacks. Aug 17 19:00:02 firewall php[92820]: [pfBlockerNG] Starting cron process. Aug 17 19:00:11 firewall php[92820]: [pfBlockerNG] No changes to Firewall rules, skipping Filter Reload Aug 17 19:00:11 firewall php[92820]: Aug 17 19:00:12 firewall rc.gateway_alarm[18784]: >>> Gateway alarm: GW_LAN (Addr:192.168.1.1 Alarm:1 RTT:752.940ms RTTsd:2054.985ms Loss:0%) Aug 17 19:00:12 firewall check_reload_status[37018]: updating dyndns GW_LAN Aug 17 19:00:12 firewall check_reload_status[37018]: Restarting IPsec tunnels Aug 17 19:00:12 firewall check_reload_status[37018]: Restarting OpenVPN tunnels/interfaces Aug 17 19:00:12 firewall check_reload_status[37018]: Reloading filter Aug 17 19:00:14 firewall php-fpm[32927]: /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed IP addresses. Reloading endpoints that may use GW_LAN. Aug 17 19:01:15 firewall rc.gateway_alarm[82776]: >>> Gateway alarm: GW_LAN (Addr:192.168.1.1 Alarm:0 RTT:3.048ms RTTsd:9.669ms Loss:0%) Aug 17 19:01:15 firewall check_reload_status[37018]: updating dyndns GW_LAN Aug 17 19:01:15 firewall check_reload_status[37018]: Restarting IPsec tunnels Aug 17 19:01:15 firewall check_reload_status[37018]: Restarting OpenVPN tunnels/interfaces Aug 17 19:01:15 firewall check_reload_status[37018]: Reloading filter Aug 17 19:01:16 firewall php-fpm[98132]: /rc.openvpn: OpenVPN: One or more OpenVPN tunnel endpoints may have changed IP addresses. Reloading endpoints that may use GW_LAN. Aug 17 19:14:00 firewall sshguard[14756]: Exiting on signal. Aug 17 19:14:00 firewall sshguard[78498]: Now monitoring attacks. Aug 17 19:33:35 firewall sshd[61656]: Accepted keyboard-interactive/pam for admin from 192.168.1.195 port 23034 ssh2 Aug 17 19:42:12 firewall sshd[65753]: Accepted keyboard-interactive/pam for admin from 192.168.1.195 port 23297 ssh2 Aug 17 19:43:31 firewall rc.php-fpm_restart[65387]: >>> Restarting php-fpm Aug 17 19:43:31 firewall check_reload_status[66343]: check_reload_status is starting. Aug 17 19:43:51 firewall php-fpm[65793]: /index.php: Session timed out for user 'admin' from: 192.168.1.195 (Local Database) Aug 17 19:43:57 firewall php-fpm[65793]: /index.php: Successful login for user 'admin' from: 192.168.1.195 (Local Database) Aug 17 19:45:03 firewall sshguard[78498]: Exiting on signal. Aug 17 19:45:03 firewall sshguard[38855]: Now monitoring attacks. -
At what point in the log did it stop responding?
-
@spittlbm said in Intermittently Unresponsive:
rc.gateway_alarm[18784]: >>> Gateway alarm: GW_LAN (Addr:192.168.1.1 Alarm:1 RTT:752.940ms RTTsd:2054.985ms Loss:0%)
You really have a gateway in the LAN subnet at 192.168.1.1? That isn't the LAN address? Added as an IPSec routing work-around perhaps?
-
@stephenw10 said in Intermittently Unresponsive:
At what point in the log did it stop responding?
I don't know exactly when it quit, but it was sometime between the 19:14 and 19:33 entries.
The Lan address of pfsense is 192.168.1.1 and it's had that GW since it was setup in 2011. That seems consistent with the docs "On most networks a gateway resides in the same subnet as one of the interfaces on a host."
-
pfSense is the gateway for other hosts in the LAN subnet but it should not itself have a gateway defined there. You would only have gateway on LAN if you have other downstream routers there that pfSense needs to route traffic to. The only other reason would be the workaround for IPSec:
https://docs.netgate.com/pfsense/en/latest/vpn/ipsec/access-firewall-over-ipsec.html#static-route-workaroundBut in both those cases if you have a LAN side gateway you need to make sure the default IPv4 gateway in System > Routing > Gateways is set specifically to WAN. If it's set to automatic there the system may swtch to using the LAN gateway as default which will obviously fail.
Steve
-
This post is deleted! -
@stephenw10 errant GW disabled. System processed traffic overnight with the exception of nginx going down with a 502 Bad Gateway. Restart PHP-FPM got it back online.
System.log was full of this to the point it rolled over
Aug 18 09:45:05 firewall check_reload_status[66343]: Could not connect to /var/run/php-fpm.socketnignx had a few
Aug 18 09:47:10 firewall nginx: 2023/08/18 09:47:10 [error] 12916#100237: *2631 connect() to unix:/var/run/php-fpm.socket failed (61: Connection refused) while connecting to upstream, client: 192.168.1.195, server: , request: "GET / HTTP/2.0", upstream: "fastcgi://unix:/var/run/php-fpm.socket:", host: "192.168.1.1"kern.ipc.soacceptqueue = 128, so I bumped that up to 1024 via a system tunable and verified it applied.
-
Hmm, nothing logged to show why php stopped responding?
I suspect bumping that sysctl won't help if php never responds.
-
@stephenw10 what's the best way to increase logging for PHP?
-
There's no easy way to do that. You can check /tmp/php_errors.txt but I'd expect any php errors to be shown as an alert.
-
Logged in tonight to see SWAP was at 52%.
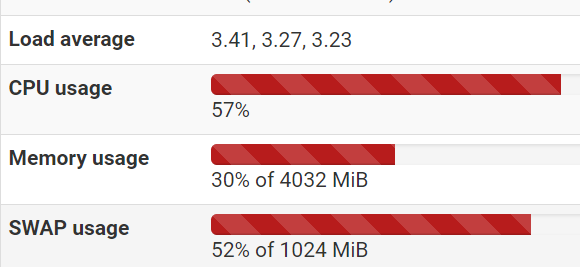
Ran top and see this:
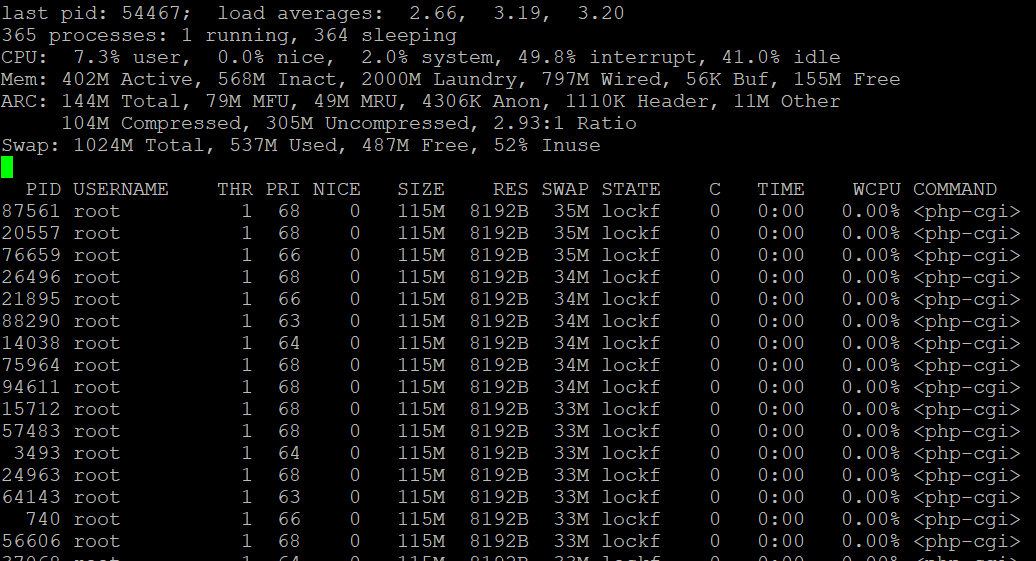
-
Ah, so some stuck script using all the RAM. Interesting.
Try running top as
top -HaSPthat may show more.You might also try running
ps -auxwwdthat may show you hat script is running. -
SWAP use is down to 5% a few (15) hours later without my intervention:
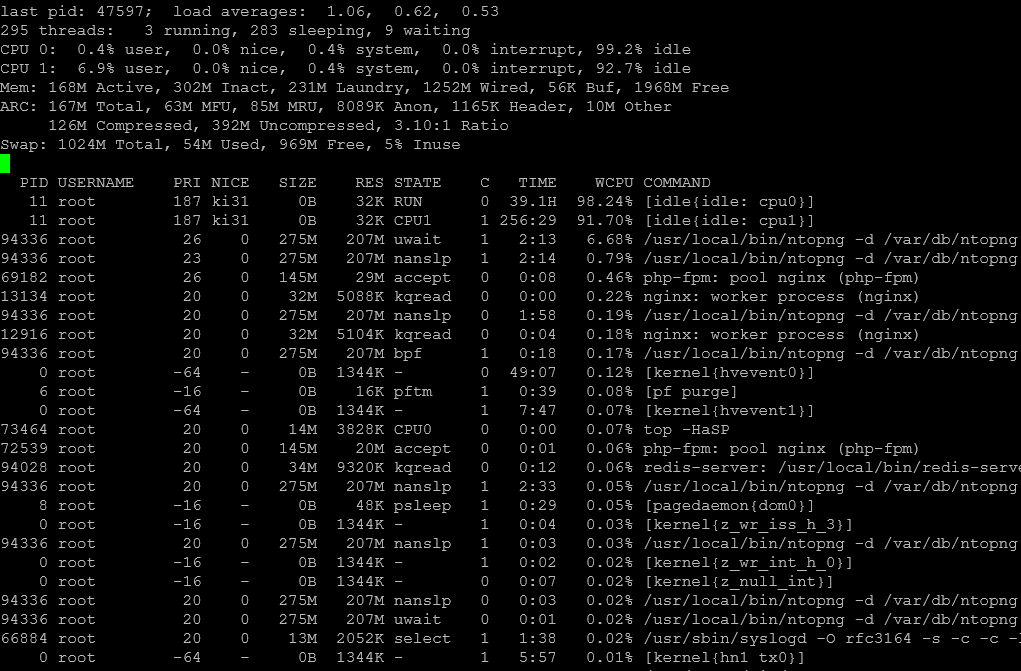
Sorted and filtered for Swap:
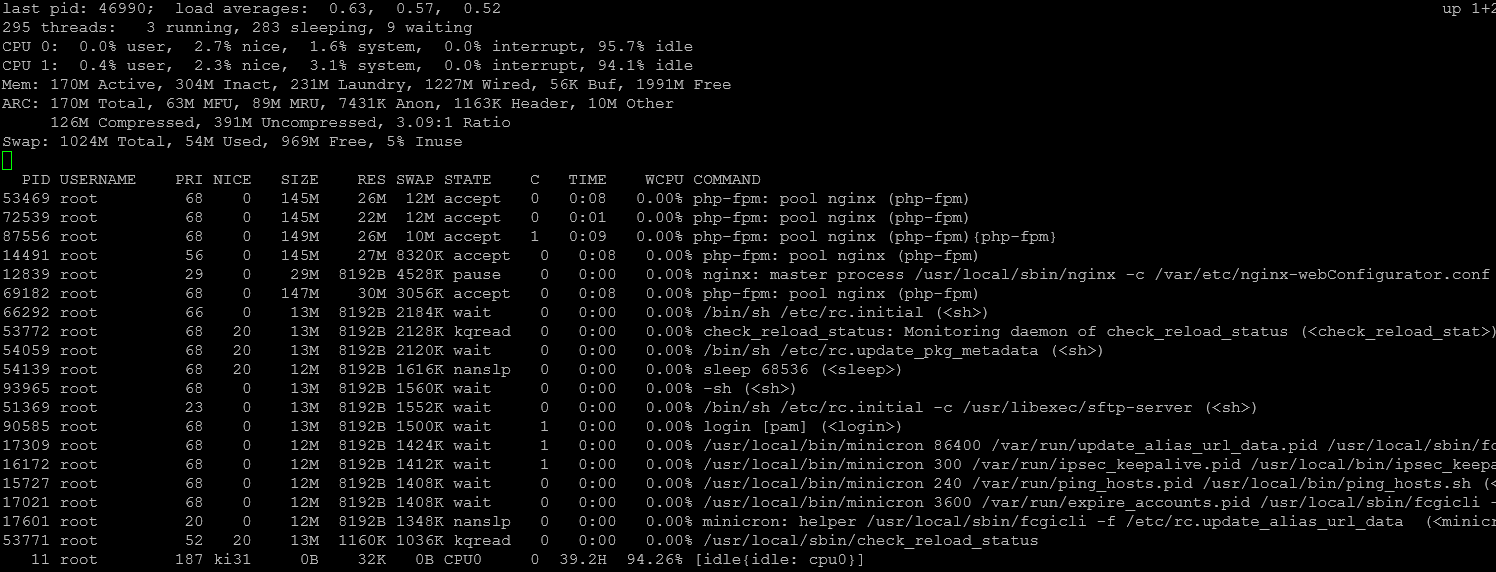
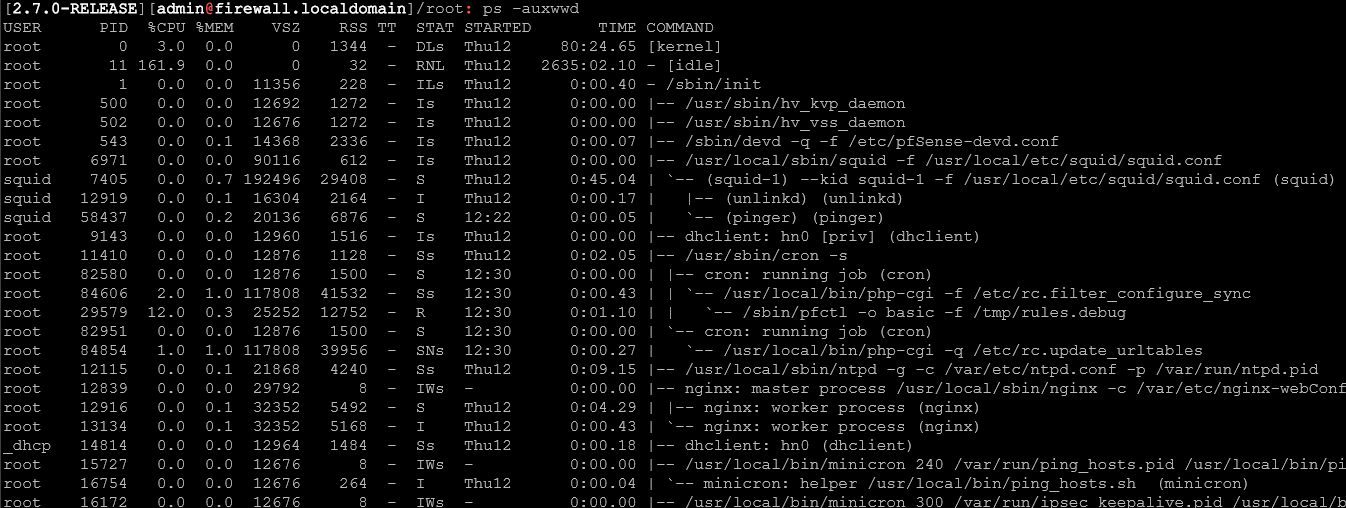
ps -auxwwd results:
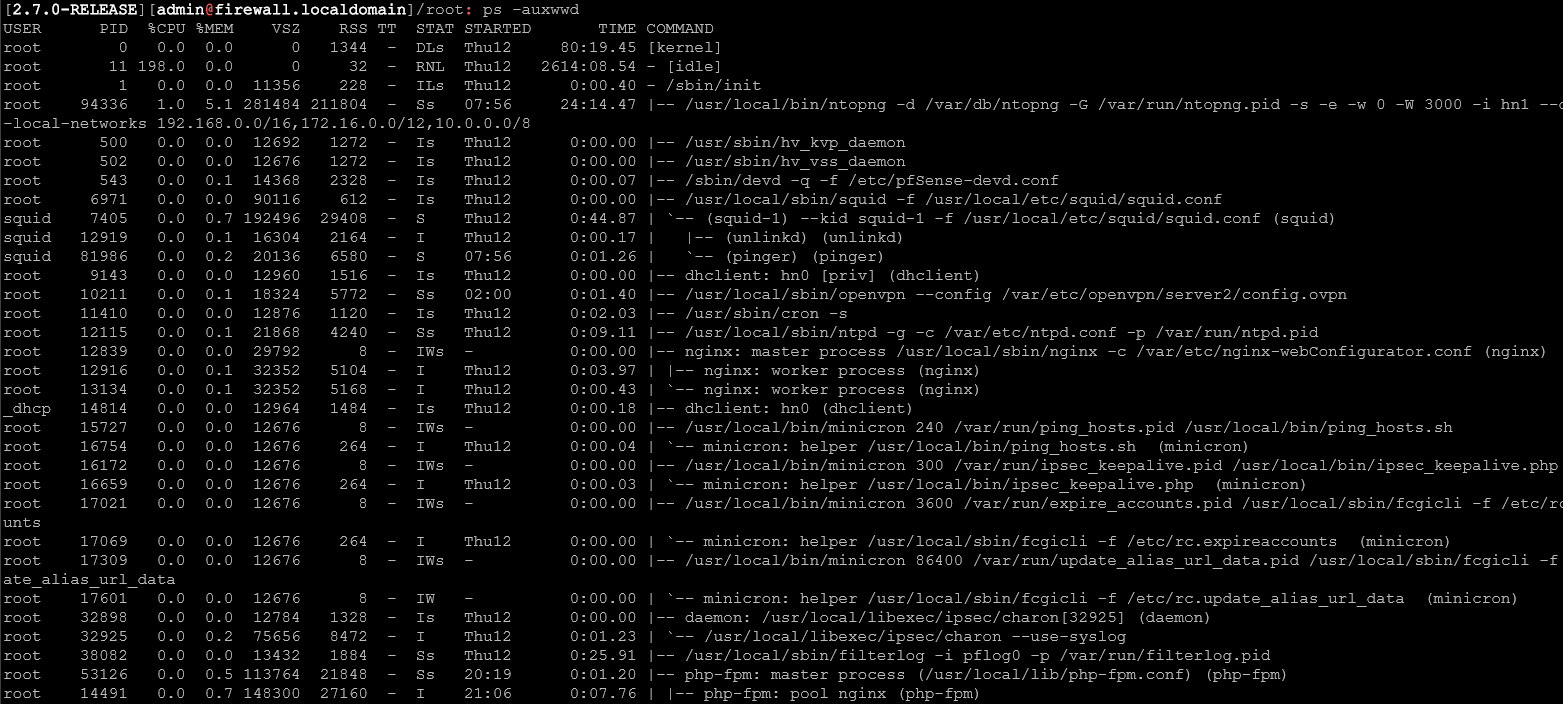
Stopped ntopng service and the stats seem similar:
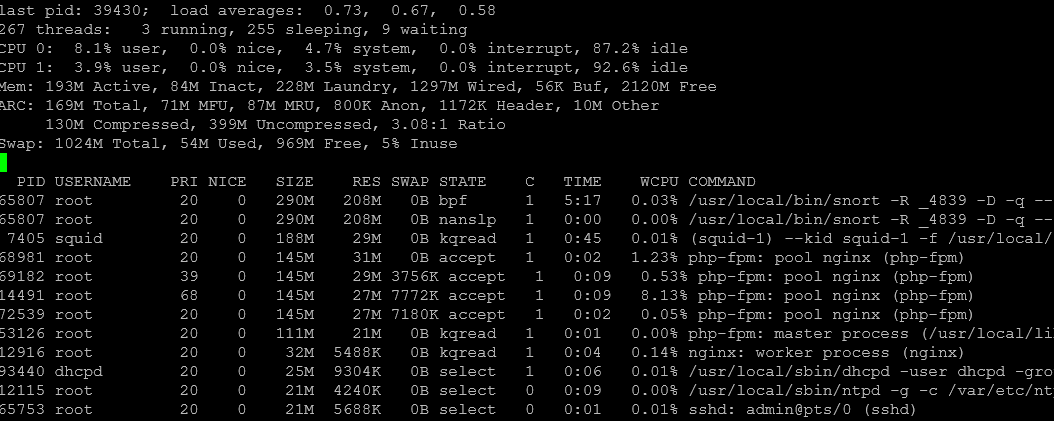
top sorted by size:
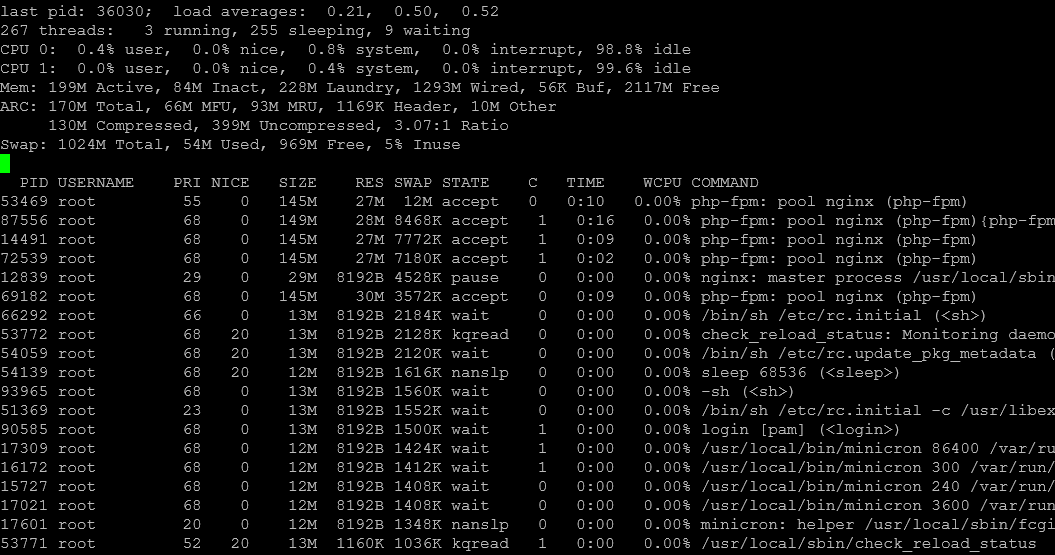
top sorted by Swap:
and lastly:
-
Nothing shown in the process tree under php-fpm in the ps output?
-
Not nothing...

Sorry for truncating that output in the previous message.
-
Hmm, dissapointing, I was hoping it might show there.
I'm not really aware of anything that behaves like that but don't run Hyper-V. You might ask in the virtualisation sub forum.
-
Just posting here to let you know that I've also had similar issues with a system has been running stable for 5+ years on Hyper-V. Since upgrading to 23.05 (and now 23.05.1) this has begun happening to me. The only difference is that it occurs after about 14 days of uptime, so not easy to reproduce or troubleshoot.
I just had it happen about 45 minutes ago, but log rotation has already purged the relevant system logs. I also send syslog to another server, but of course it didn't receive anything during the outage. I doubled the log size for rotation and extended the retained logs to 21. I'll post another update to this thread next time it happens, and see if I can capture the relevant logs before they get purged.
-
Unless anyone is seeing this on another platform this thread would probably be better in the virtualization sub.
-
We've been stable for 4-5 days without touching anything. If it happens again, I'll hop to the other sub. Don't love that something is using a bit of swap and always at 2gb+ ram usage, but it's working well.