100% /usr/local/sbin/check_reload_status after gateway down
-
@serbus
Great suggestion !
Just set this up on my 23.09.1
We'll see how it behaves. -
@adamw said in 100% /usr/local/sbin/check_reload_status after gateway down:
Dec 10 10:10:05 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached ---> MONITORING STARTED PICKING UP ISSUES
Dec 10 10:14:16 netgate kernel: sonewconn: pcb 0xe2f8a000 (192.168.8.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (1 occurrences), euid 0, rgid 62, jail 0
Dec 10 10:15:05 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached
Dec 10 10:15:16 netgate kernel: sonewconn: pcb 0xe2f8a000 (192.168.8.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (250 occurrences), euid 0, rgid 62, jail 0
(...)
Dec 10 11:00:21 netgate kernel: sonewconn: pcb 0xe2f8a000 (192.168.8.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (18 occurrences), euid 0, rgid 62, jail 0
Dec 10 11:00:25 netgate kernel: sonewconn: pcb 0xe4a4f800 (127.0.0.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (4 occurrences), euid 0, rgid 62, jail 0
Dec 10 11:05:06 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached
Dec 10 11:10:06 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached
Dec 10 11:15:07 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached
Dec 10 11:20:07 netgate kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached ---> FIREWALL BECAME COMPLETELY UNRESPONSIVE AND REQUIRED POWER CYCLINGRight, so this crash wasn't caused by check_reload_status and high CPU usage.
It happened again today:
Dec 13 17:08:04 kernel [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached Dec 13 17:10:36 kernel sonewconn: pcb 0xe2939c00 (192.168.8.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (1 occurrences), euid 0, rgid 62, jail 0 Dec 13 17:11:37 kernel sonewconn: pcb 0xe2939c00 (192.168.8.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (998 occurrences), euid 0, rgid 62, jail 0 Dec 13 17:12:37 kernel sonewconn: pcb 0xe2939c00 (192.168.8.1:3128 (proto 6)): Listen queue overflow: 193 already in queue awaiting acceptance (520 occurrences), euid 0, rgid 62, jail 0 (...)This is the trigger:
export HTTP_PROXY=http://192.168.8.1:3128 export HTTPS_PROXY=http://192.168.8.1:3128 aws s3 cp --profile xxx xxx.gz s3://xxx/xxx.gz --grants read=uri=http://acs.amazonaws.com/groups/global/AllUsers --only-show-errors upload failed: ./xxx.gz to s3://xxx/xxx.gz HTTPSConnectionPool(host='xxx.s3.amazonaws.com', port=443): Max retries exceeded with url: /xxx.gz?uploadId=2Np0o_30Su5ZrxamVzMYX.LQkPVMog7PupvQTUByny25FOXr7_9Jnz2cXvm0c3xxQ9I6qUPISyhwHhIc63lnlg0nzxiafHs93P_d8qJW3ImmEGyPO3GS0HXRDxcvclWp&partNumber=37 (Caused by ProxyError('Cannot connect to proxy.', ConnectionResetError(104, 'Connection reset by peer')))Squid doesn't seem to have logged anything.
Has anybody seen it before?
-
@adamw said in 100% /usr/local/sbin/check_reload_status after gateway down:
kernel: [zone: mbuf_cluster] kern.ipc.nmbclusters limit reached
That is a problem. The firewall has exhausted the mbufs which will impact all traffic through it.
What does this show for the current available and used mbufs:
netstat -m -
# netstat -m 3255/1815/5070 mbufs in use (current/cache/total) 1590/940/2530/10035 mbuf clusters in use (current/cache/total/max) 1590/940 mbuf+clusters out of packet secondary zone in use (current/cache) 1/758/759/5017 4k (page size) jumbo clusters in use (current/cache/total/max) 0/0/0/1486 9k jumbo clusters in use (current/cache/total/max) 0/0/0/836 16k jumbo clusters in use (current/cache/total/max) 3997K/5365K/9363K bytes allocated to network (current/cache/total) 0/0/0 requests for mbufs denied (mbufs/clusters/mbuf+clusters) 0/0/0 requests for mbufs delayed (mbufs/clusters/mbuf+clusters) 0/0/0 requests for jumbo clusters delayed (4k/9k/16k) 0/0/0 requests for jumbo clusters denied (4k/9k/16k) 0/6/6656 sfbufs in use (current/peak/max) 0 sendfile syscalls 0 sendfile syscalls completed without I/O request 0 requests for I/O initiated by sendfile 0 pages read by sendfile as part of a request 0 pages were valid at time of a sendfile request 0 pages were valid and substituted to bogus page 0 pages were requested for read ahead by applications 0 pages were read ahead by sendfile 0 times sendfile encountered an already busy page 0 requests for sfbufs denied 0 requests for sfbufs delayed -
Hmm OK, well that looks fine there.
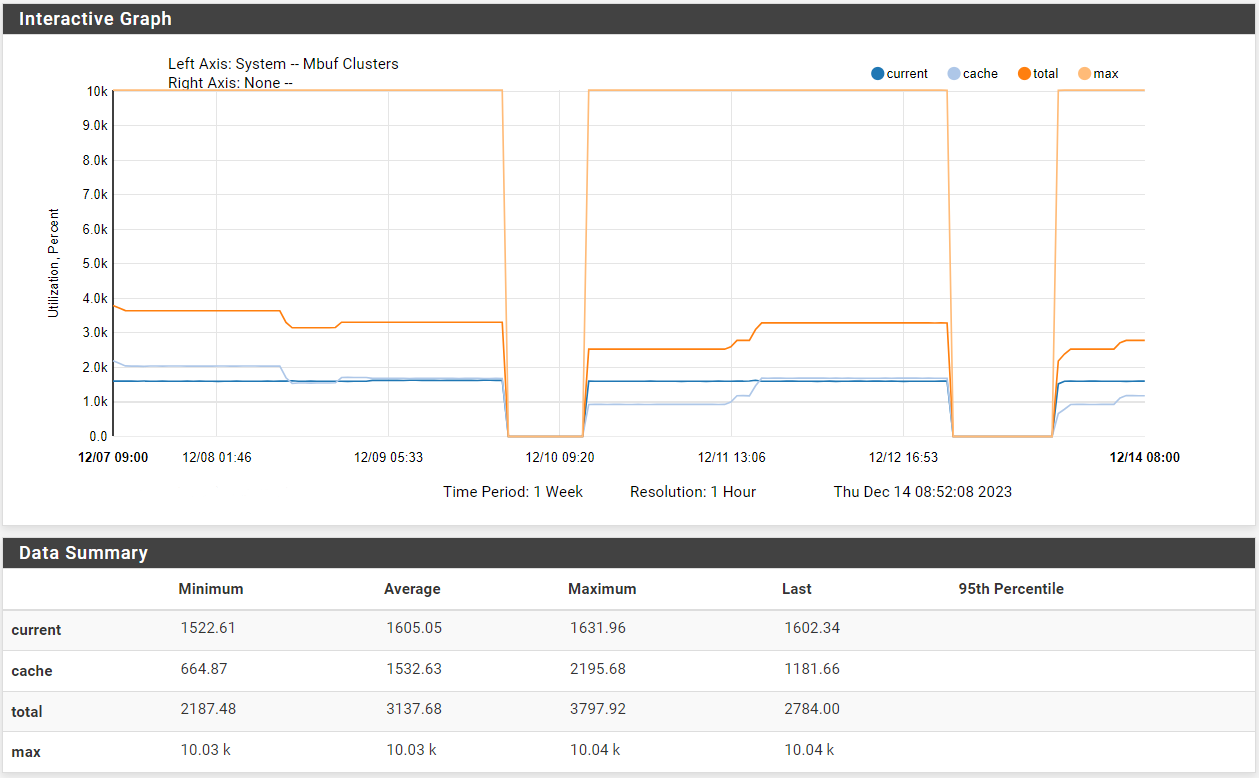
Check the historical mbuf usage in Status > Monitoring.
-
-
Hmm, the total never get's near the max though.
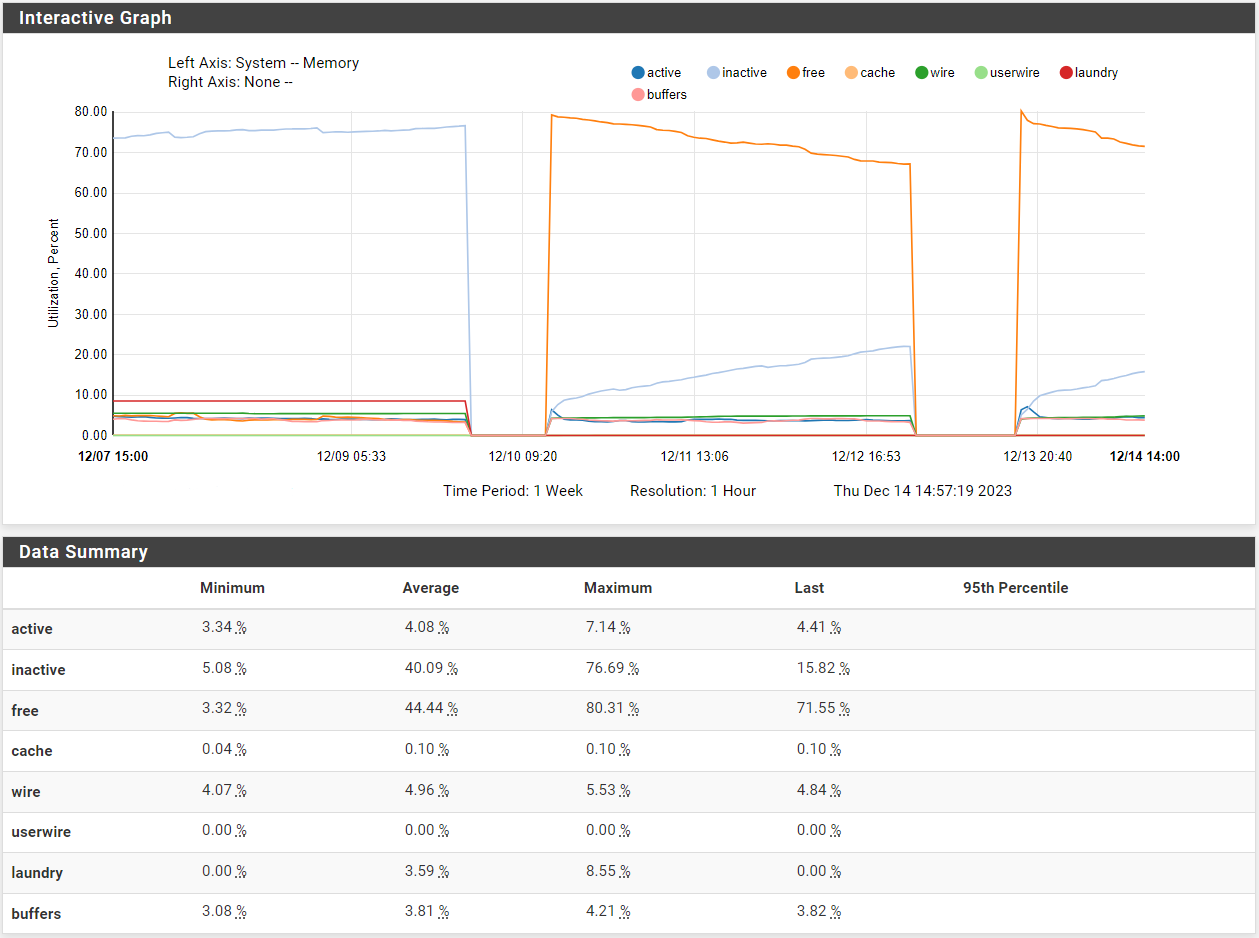
Check the memory usage over that time. It may be unable to use mbufs if the ram is unavailable.
-
-
Hmm, so using memory but no where near used.
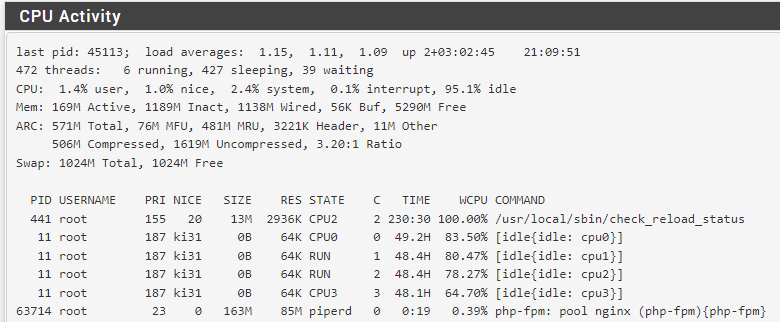
Nothing else logged when it fails? -
I've retried it today on 23.09.1.
A total crash happened again after uploading about 500 MB of data:Dec 27 12:52:42 kernel [zone: mbuf_cluster] kern.ipc.nmbclusters limit reachedThe culprit is definitely the web proxy (squid 0.4.46) which hasn't logged much:
Wednesday, 27 December 2023 12:44:44.299 509 192.168.8.96 TCP_TUNNEL/200 8309 CONNECT mybucket.s3.amazonaws.com:443 - HIER_DIRECT/3.5.20.172 - Wednesday, 27 December 2023 12:49:19.934 403 192.168.8.96 TCP_TUNNEL/200 8297 CONNECT mybucket.s3.amazonaws.com:443 - HIER_DIRECT/52.217.95.145 - Wednesday, 27 December 2023 12:56:56.215 29216 192.168.8.96 TCP_TUNNEL/200 14710 CONNECT mybucket.s3.amazonaws.com:443 - HIER_DIRECT/54.231.229.41 -The "aws s3 cp" deals with large files fine when it's forced to bypass proxy.
Since it doesn't seem related to check_reload_status, shall I start a new topic and for the last few entries to be removed from here?
-
Yes, should be in a different thread. Unlikely unique to Netgate hardware either.
-