Another Netgate with storage failure, 6 in total so far
-
@andrew_cb Interesting point and I don’t know that pfSense does auto cleanup (yet?) since there have been several posts with full storage.
Link for reference:
https://docs.netgate.com/pfsense/en/latest/troubleshooting/filesystem-shrink.html -
@chrcoluk said in Another Netgate with storage failure, 6 in total so far:
I think you need to link to the article, the first line e.g. is incorrect terminology. Record size isnt the block size.
The article linked in an earlier post of @andrew_cb's makes clear that it's not confusing "block size" for
recordsize:The most important tuning you can perform for a database is the dataset block size—through the
recordsizeproperty. The ZFSrecordsizefor any file that might be overwritten needs to match the block size used by the application.Tuning the block size also avoids [ . . . ]
@chrcoluk said in Another Netgate with storage failure, 6 in total so far:
Laymans answer, high txg means batched writing, batched writing means larger record being written, larger record means more compression, less data hits disk, and as a bonus less metadata hits disk.
I have played with this in VMs which graph the i/o's, if it makes you feel better, that data has verified what I am posting.
But so basically you agree that increasing the
vfs.zfs.txg.timeoutparameter is a net good thing... -
@chrcoluk said in Another Netgate with storage failure, 6 in total so far:
Thank you for the detailed explanation. This fits how I understand it and what others have said.
My guess is that the actual write rate is even higher, and the 200-300KB/s rate is after ZFS has optimized the data stream using smaller ashift values and compression.
(c) depending how logs are written, if the entire filesize is written on every amendment to the log, a small txg will have very large write amplification.
This seems to be the primary factor, as making changes to txg has an immediate and significant effect on write rate.
-
I checked our firewalls and found that they all had boot environments, with many going back to 22.01. I deleted all the boot environments, and all firewalls showed an increase in disk size. Here are a few examples:
FW1 before:
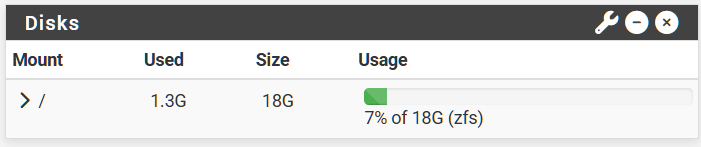
FW1 Boot environments:
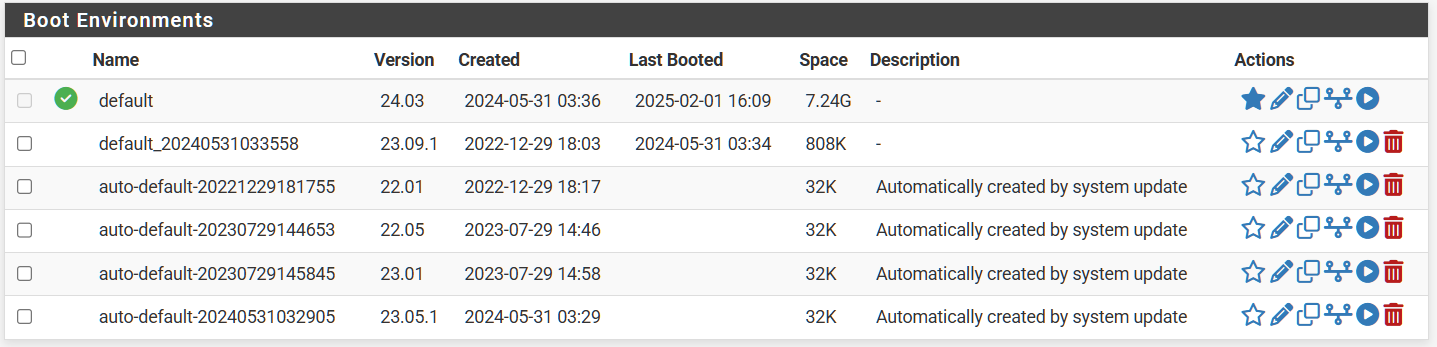
FW1 after deleting boot environments:
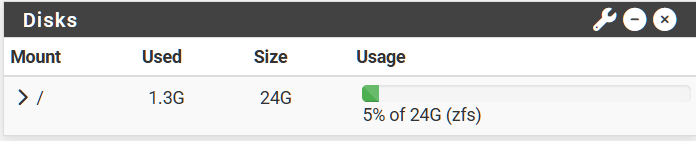
FW1 Result: 6GB more space after deleting 5 boot environments (avg 1.2GB per boot environment).
FW2 before:

FW2 Boot environments:

FW2 after deleting boot environment:

FW2 result: 1GB more space after deleting 1 boot environment (avg 1GB per boot environment).
FE3 before:
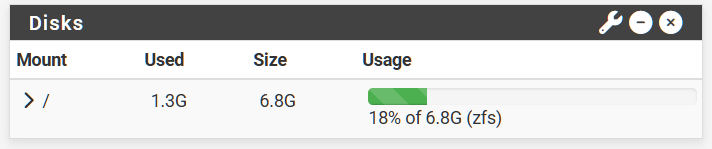
FW3 boot environments:

FW3 after deleting boot environments:
FW3 result: 5.2GB more free space after deleting 4 boot environments (avg 1.3GB per boot environment).
-
@andrew_cb said in Another Netgate with storage failure, 6 in total so far:
FW1 Result: 6GB more space after deleting 5 boot environments (avg 1.2GB per boot environment).
FWIW that's pretty typical, it just depends on how much changed on disk in between. The "32K" or whatever shows in the GUI is very misleading there, IMO.
-
@SteveITS said in Another Netgate with storage failure, 6 in total so far:
@andrew_cb said in Another Netgate with storage failure, 6 in total so far:
FW1 Result: 6GB more space after deleting 5 boot environments (avg 1.2GB per boot environment).
FWIW that's pretty typical, it just depends on how much changed on disk in between. The "32K" or whatever shows in the GUI is very misleading there, IMO.
Yes, I figured that the 32K was not accurate.
The size of the current boot environment decreases to 1.7-1.9GB after the other boot environments are deleted, which is more in line with the actual space consumed. -
@tinfoilmatt said in Another Netgate with storage failure, 6 in total so far:
But so basically you agree that increasing the
vfs.zfs.txg.timeoutparameter is a net good thing...For sure.
-
As someone about to buy a 4200, does anyone know if Netgate has implemented any of these strategies in their latest pfSense Plus? If not, can somebody summarize the recommended tweaks?
-
@valnar buy a plus, set the vfs.zfs.txg.timeout to a value of between 15 and 30 seconds, connect it to an apc ups and use apcupsd package to initiate low power safe shutdown.
A bonus would be to buy a fan so it runs cool. Not necessary by any means but would probably help with overall service life.
My feeble understanding is that Netgate is working on zfs adjustments to address the poor ssd life but has released nothing yet.
-
@Mission-Ghost Thank you.
-
@valnar said in Another Netgate with storage failure, 6 in total so far:
summarize the recommended tweaks
See this post:
https://forum.netgate.com/topic/195990/another-netgate-with-storage-failure-6-in-total-so-far/21 -
S SteveITS referenced this topic on
-
@valnar For now, I recommend these two changes:
Navigate to System > Advanced > System Tunables and add a new tunable:
- Tunable
vfs.zfs.tgx.timeout - Value
30
Navigate to Diagnostics > Command Prompt and run
zfs set sync=always pfSense/ROOT/default/cf - Tunable
-
Thanks for the easy step-by-step instruction!
Quick question - Do you have to run the zfs set command on each subsequent reboot or just the first time after adding the tunable?
-
@andrew_cb said in Another Netgate with storage failure, 6 in total so far:
Navigate to Diagnostics > Command Prompt and run
zfs set sync=always pfSense/ROOT/default/cfNote: the command should read:
zfs set sync=always pfSense/ROOT/Default/cfDefaultstarts with a capital D.
-
@azdeltawye said in Another Netgate with storage failure, 6 in total so far:
Quick question - Do you have to run the zfs set command on each subsequent reboot or just the first time after adding the tunable?
I'd be interested in the answer as well. The freeBSD help and Google Gemini (which is often wrong but never in doubt) suggests it's a one-time setting.
I missed this setting in earlier discussions, so I just executed it and it's set in the zfs config now. I haven't rebooted. Yet.
-
@Mission-Ghost said in Another Netgate with storage failure, 6 in total so far:
I missed this setting in earlier discussions, so I just executed it and it's set in the zfs config now. I haven't rebooted. Yet.
If you make a entry in the "system tuning" the setting will survive even a system upgrade (if still necessary)...
-
Even though I have a Kingston mSATA SDD with 2.1 years power on hours, life is down to 90%
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 9 Power_On_Hours 0x0000 100 100 000 Old_age Offline - 18867 169 Remaining_Lifetime_Perc 0x0000 090 090 000 Old_age Offline - 90sysctl vfs.zfs.txg.timeout=30Lower case "default" on 2.7.2 CE
zfs list NAME USED AVAIL REFER MOUNTPOINT pfSense 24.1G 205G 96K /pfSense pfSense/ROOT 1.11G 205G 96K none pfSense/ROOT/default 1.11G 205G 1.10G / pfSense/ROOT/default/cf 6.88M 205G 6.88M /cf pfSense/ROOT/default/var_cache_pkg 336K 205G 336K /var/cache/pkg pfSense/ROOT/default/var_db_pkg 5.42M 205G 5.42M /var/db/pkg pfSense/home 108K 205G 108K /home pfSense/reservation 96K 227G 96K /pfSense/reservation pfSense/tmp 1.37M 205G 1.37M /tmp pfSense/var 35.9M 205G 3.45M /var pfSense/var/cache 96K 205G 96K /var/cache pfSense/var/db 2.38M 205G 2.38M /var/db pfSense/var/empty 96K 205G 96K /var/empty pfSense/var/log 29.8M 205G 29.8M /var/log pfSense/var/tmp 136K 205G 136K /var/tmp zfs set sync=always pfSense/ROOT/default/cf -
@valnar said in Another Netgate with storage failure, 6 in total so far:
If not, can somebody summarize the recommended tweaks?
These are my settings:
vfs.zfs.txg.timeout=120 (you can increase this value as you wish - I was gone until 2400 in experiments with no problems) zfs set sync=disabled zroot/tmp (pfSense/tmp) zfs set sync=disabled zroot/var (pfSense/var)Regards,
fireodoKettop Mi4300YL CPU: i5-4300Y @ 1.60GHz RAM: 8GB Ethernet Ports: 4
SSD: SanDisk pSSD-S2 16GB (ZFS) WiFi: WLE200NX
pfsense 2.8.1 CE
Packages: Apcupsd, Cron, Iftop, Iperf, LCDproc, Nmap, pfBlockerNG, RRD_Summary, Shellcmd, Snort, Speedtest, System_Patches. -
@elvisimprsntr Interesting. Why the inconsistency, I wonder?
-
@fireodo said in Another Netgate with storage failure, 6 in total so far:
If you make a entry in the "system tuning" the setting will survive even a system upgrade (if still necessary)...
Sweet. Thanks.