NTP Issue
-
The apple timeserver responded instantly and the 1100 totally ignored the two locals.
It will put the other two as a 'hot spare'.
Check for yourself (example) :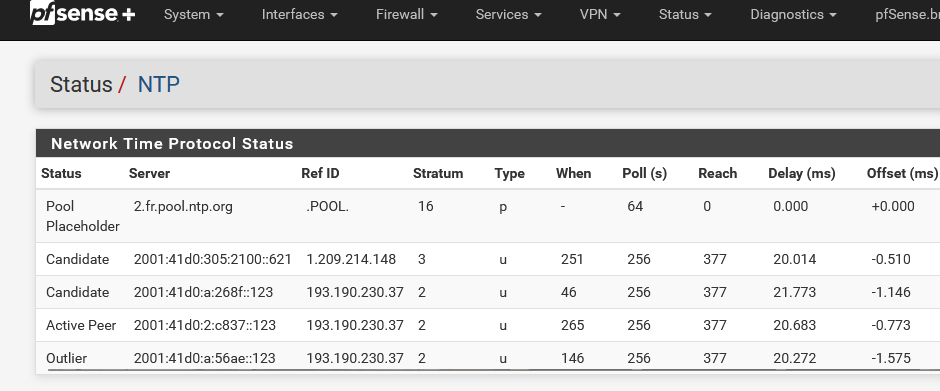
Btw : look at that : NTP went IPv6 only also ...
I updated it to the latest Pfsense Plus
24.11.
the same three timeservers
Normally, you shouldn't use 3 'off something' (DNS, NTP, whatever) as it created problems.
See it like this : you have to buy a new car, but you want to think about it, so your interrogations @home and discuss it with your wive.
What would happen if you had 3 wives ?
I can tell you what will happen. You won't drive any car any soon (you couldn't afford one anyway ^^)So :
NTP : pick a 'pool'.
DNS : stick to 'root servers' (a pool actually).
etc etc.latest legacy 2.3.5
An APU ? 32 bits ??
it to 2.4 so
2.4 ?
-
- Go and read the entire thread, start to finish. Pay particular attention to what I have already posted.
- Go and read how NTP actually works.
Not SNTP.
The REAL complete NTP and learn EXACTLY WHY you put in multiple NTP sources.
Then maybe go and read why Industry Best Practice requires four.
-
And sadly, the issue still exists with 2.8
There's just no way that I can find to get pfsense back to taking notice of any NTP servers on the LAN.
-
Ok reading back a few things are unclear here.
The configures internal ntp server(s) just show as unreaching in pfSense?
A pcap on the ntp server shows requests from pfSense and responses from the server?
But the state table on the firewall only shows one way traffic?
Does a pcap on pfSense show the replies from server?
Does it do the same thing if there are no other servers configured?
-
It still works fine for me here from 2.8 and 25.03:
[2.8.0-RELEASE][admin@cedev-2.stevew.lan]/root: ntpq -np remote refid st t when poll reach delay offset jitter ============================================================================== *172.21.16.1 .GPS. 1 u 43 64 377 0.378 -0.347 2.602Now the jitter is crap on that server because it's a USB connected GPS. My real GPS device failed a while back

So in a list it doesn't get selected as the active peer. But it still polls it just fine:
[2.8.0-RELEASE][admin@t70.stevew.lan]/root: ntpq -np remote refid st t when poll reach delay offset jitter ============================================================================== -172.21.16.1 .GPS. 1 u 43 64 377 0.404 -2.999 0.919 2.pfsense.pool. .POOL. 16 p - 64 0 0.000 +0.000 0.000 +217.154.60.177 139.143.5.31 2 u 26 64 377 8.644 +1.450 0.256 *85.199.214.99 .GPS. 1 u 22 64 377 6.458 +1.507 0.204 +185.83.169.27 .GPS. 1 u 22 64 377 10.610 +1.119 0.366That also includes whether or not the server is WAN or LAN side, as long as the ACLs allow it.
-
A brief recap of the situation.
I run two LAN based GPS ntp servers.
They used to run fine before I updated to 2.7.
They would instantly get selected as peer and next best within a very short time.
Other ntp servers on the internet were also selected so as to show internet conditions within the state, country and various parts of the world.
As soon as the 2.7 update happened, the LAN based NTP servers became unreachable.
There have been at least three other people in the world who had this exact same issue.The NTP servers each remain available to each of the 72 devices currently on the home network.
My particular box does not like USB GPS devices and the serial port is an RJ45 port, which never responded to any combination of mapping the PPS, so that option is out of the window.So with your real GPS device failed, how can you be sure that your install still works with a LAN based NTP server?
-
That is an LAN based ntp server I've shown above. It's a crap ntp server but it's still local and is reachable just fine.
So something about your servers is different, hence my list of questions. When I read back through the thread at one point you said the state table showed one way traffic. That implies some network issue rather than anything ntp specific.
I'll try and repair my true GPS module. That used pps over a real serial port. Unfortunately the antenna connector was pulled off the board so it requires some delicate surgery!
-
@stephenw10
Well, I'm amazed that you have a LAN based NTP server turning up as being available.I can see that my pfsense box is contacting both my ntp servers because they report the last 100 hosts.
I have opt 2 configured with zero firewall rules and it goes to the second port of the main NTP server. That port serves only port 123, so it's a handy test.
That port of the NTP server is configured to broadcast NTP every thirty seconds AND I can see that traffic turn up as measured by the firewall, every 30 seconds. I ditched the broadcast and seeing as nothing but NTP traffic is on that port, it clearly shows traffic going to and from the NTP server.
So we know that the the network is just fine between the firewall and three ports between both NTP servers.A little while ago, I disabled all the LAN firewall rules, then restarted the NTP service.
As per usual, all of the LAN NTP servers were unreachable and yet time.apple.com quickly was selected out of the six other options.
(For anyone who cares, I logged various NTP servers around the world for over two and half years at my work. time.apple.com is by far the most reliable and fastest. I'm pretty sure they have a decent time server in most countries, even if the traceroute takes you back to the USA. Not ONE of ANY of the public pools of NTP servers were reliable. I would NEVER recommend using pools of any NTP servers.
I've established several times to my satisfaction that my firewall is contacting both NTP servers and totally ignoring them.
I'm thinking that it's a kernel level problem now. -
I'm thinking that it's a kernel level problem now.
no its not.. I use a local ntp server - and there are zero issues syncing time from it both on 24.11 and 2.8..
There are many people here running their own local ntp - its not a pfsense issue.. Its something unique to your setup.
"Anyway, the second NTP server has two interfaces which can be independently configured"
Why would you have your ntp server mult-homed. But that could be a problematic if firewall is blocking it because of changes in rules - where traffic not allowed unless you set states back to floating.

the only way I can duplicate your problem is if I set custom acl so that my ntp server is ignored
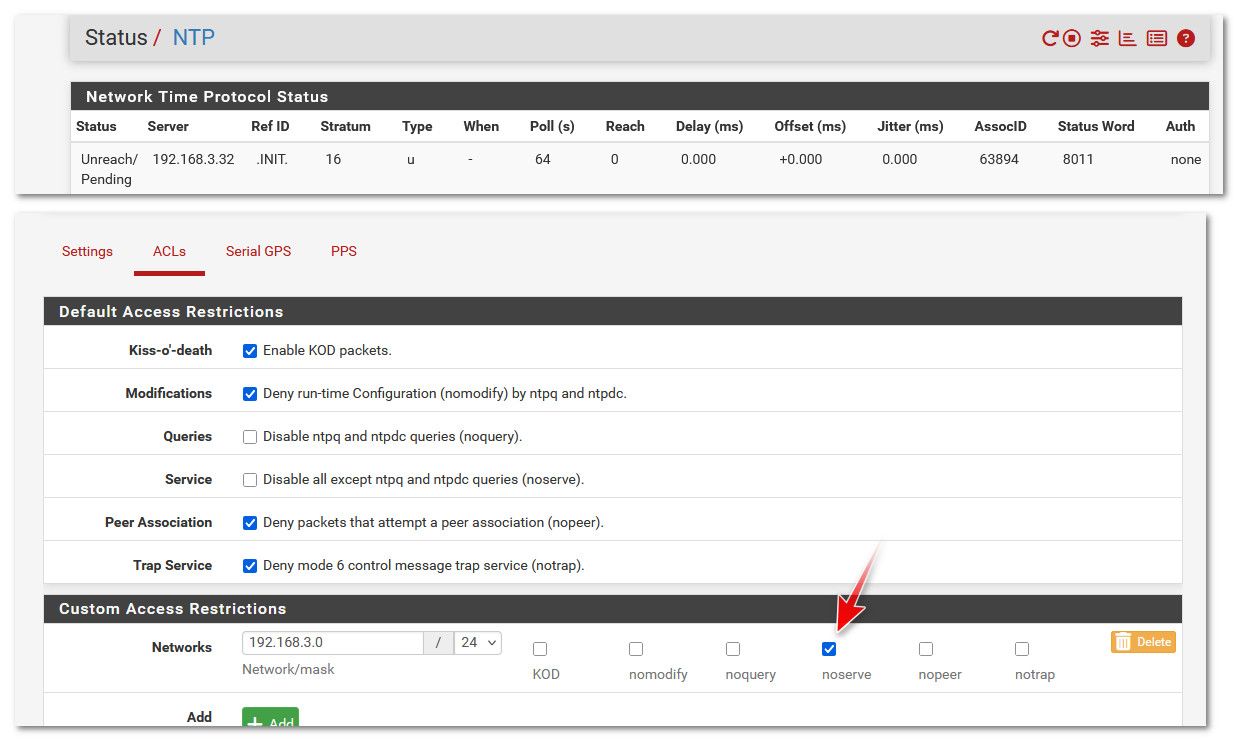
-
@johnpoz
Well, it's not unique to mine if at least five other people had the same thing happen when they updated to 2.7.Ordinarily, I wouldn't have the NTP server multi homed.
That particular server has two ports. One for admin and NTP and the other for only responding to NTP requests. That's the side that I'd have available to the internet if I wasn't on asynchronous It occurred to me that I could simulate another network for faultfinding with that port, so I configured it to have it's own A class network. It works perfectly for everything plugged into it, except the firewall.On the weekend, I'm going to configure the SG-1100 and see what it does when it's plugged into that port.
It is just incredibly annoying that my original NTP test lab setup had up to six stratum one NTP servers of various types and everything talked to them. I've designed and installed industry best practice NTP systems for federal government departments and absolutely everything in them never had an issue once it was correctly configured. I'd never seen literally thousands of machines all within sub millisecond sync before.
And then I got my pfsense box and had it graphing with good numbers and then excellent numbers with a local NTP server, so was starting to increase the count when 2.7 turned up.... and then that was the end of things.I was hoping that 2.8 would mysteriously fix it, particularly when people were talking about patches. I have one resource who is a FreeBSD god and I'm at the point of inviting him over, but I'll never hear the end of not keeping my FreeBSD server running...
-
but I'll never hear the end of not keeping my FreeBSD server running...
Ha! Sometimes it's a price you have to pay.

But I'd be amased if the ntp client in pfSense is actually seeing the replies from the server. It's almost certainly being dropped somehow before it reaches it.The only other thing I can think of would be the client itself rejecting the replies but since you're not using any sort of ntp auth I have no idea why it would.
How are you checking this traffic? I would want to use pcaps on either end to be sure. Make sure the IPs and MACs all line up.
But also checking the outbound ntp state on the firewall. That must show two way traffic if replies are coming back and being passed.
Yes the interface bound states change would be my first suspect here except that it wasn't in 2.7.X.

-
@stephenw10 said in NTP Issue:
But also checking the outbound ntp state on the firewall. That must show two way traffic if replies are coming back and being passed.
Yup that is a very simple sanity check for sure.
-
@stephenw10
The thought occurred to me that the easiest way to ensure that the firewall can actually see the traffic is to let the NTPmonitor running on my workstation, query the second port of the NTP server via OPT2.There are no other paths to get to it, as it's one ethernet cable joining the firewall to the NTP server.
NTPmonitor found it instantly, and can poll it constantly, so that traffic is going back and forth through the port on the firewall, and is also being routed from the LAN port to the OPT2 port and back, by the firewall.
This tends to suggest to me that there are no firewall rules obstructing it and the traffic is just fine. -
@admacdo and what does your states show - there is a difference from sending a query from a different network. For when pfsense asks?
If you do not see return traffic via the state - then for some reason that traffic was not processed.. Even if there was something as you mention in the kernel - which is no way the issue.. The state would still be listed as traffic was returned.
While its clear there is something going on - nobody else that I am aware has been able to duplicate the problem.. pfsense talks to my ntp server just fine. Steve can not duplicate it either.
But if your state is not showing return traffic - then the ntp client which is farther up the stack, if the firewall isn't allowing it via completion of the state. The ntp client would never see it.
-
@johnpoz
Can we pretend (or not pretend)at this point that I'm an idiot and demo the commands I can put in a command line to show this information? -
Just go to Diag > States in the webgui and filter by
:123to see the ntp states.You should see a state on the interface connected to the ntp server with no corresponding state on another interface. That will be the state opened from the firewall itself.
It's usually pretty obvious but you likely have a bunch of ntp states so it might be more difficult to spot.
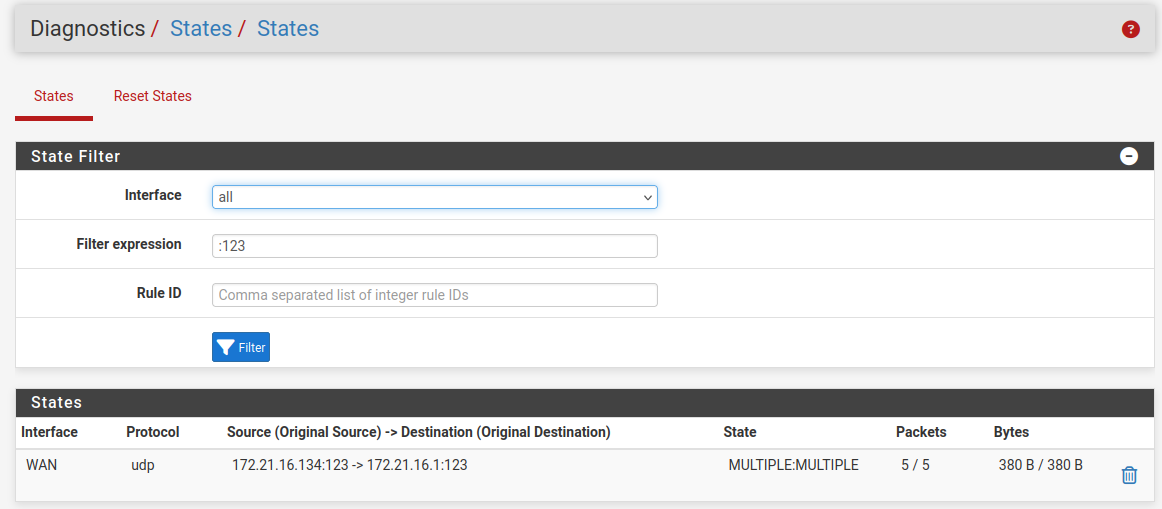
-
I note that the states can timeout so may not always be there. I restarted ntpd to force it to reach out to get that screenshot. But you could just wait. You can see two way traffic on that state though.
-
@stephenw10
The top two are the local NTP servers.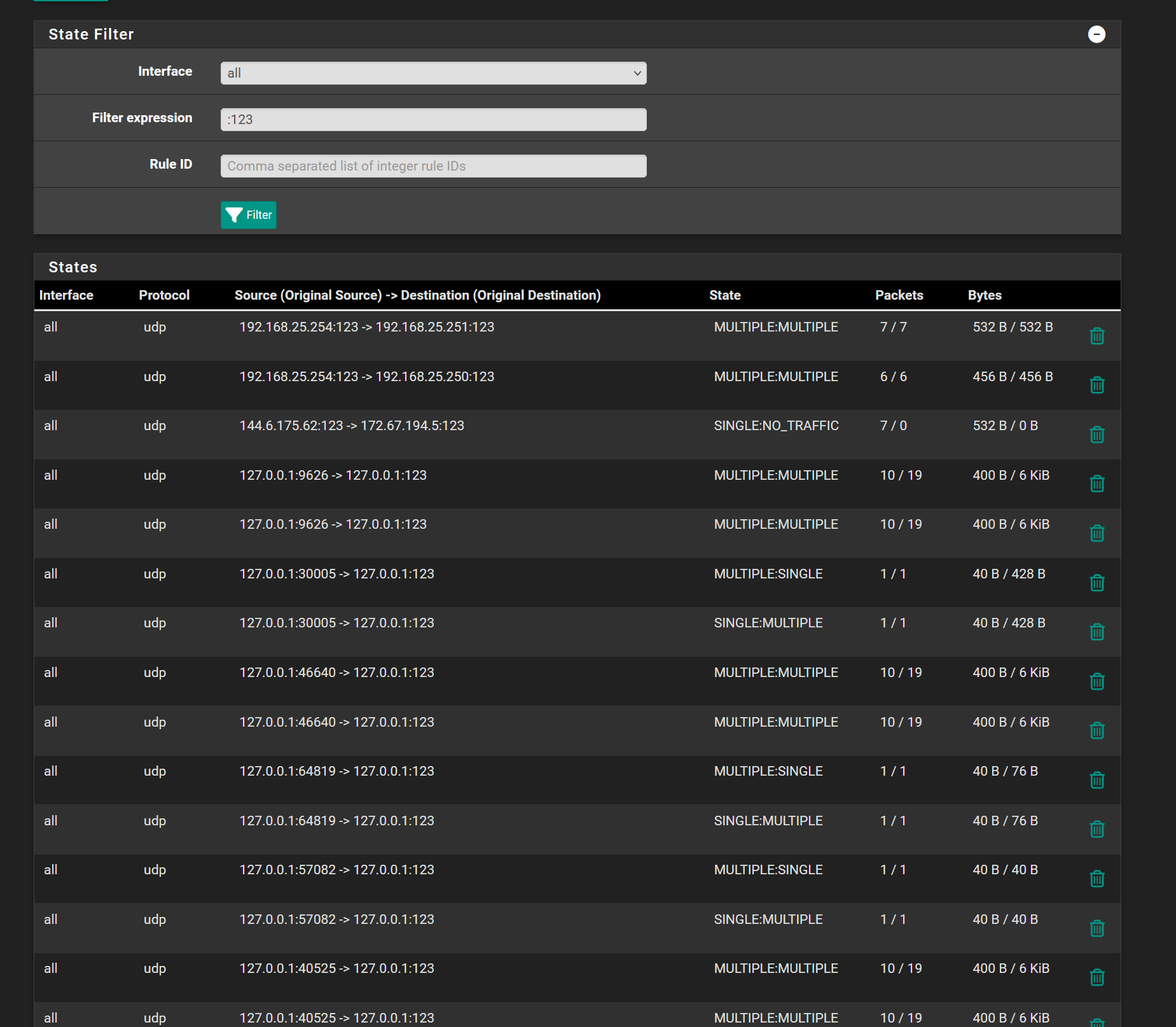
-
@stephenw10 said in NTP Issue:
Just go to Diag > States in the webgui and filter by
:123to see the ntp states.You should see a state on the interface connected to the ntp server with no corresponding state on another interface. That will be the state opened from the firewall itself.
It's usually pretty obvious but you likely have a bunch of ntp states so it might be more difficult to spot.
Thanks for that, by the way. I tend to only look and remember exactly what I'm looking for in a list. I had no idea this option was available.
-
That's in 2.7.2? I note the states are shown as on 'all' interfaces. Which should be fine but potentially could hide an asymmetric route. It wouldn't block ntp though.
So it looks like two traffic to both servers. I assume they are still reported as 'unreach'?
I would next run a pcap for that traffic and see what's actually being sent.
If you enable all the logging in ntpd do you see any additional errors?