25.07 - no default gateway being set if default route is set to a gateway group and the Tier 1 member interface is down
-
@luckman212 said in 25.07 RC - no default gateway being set if default route is set to a gateway group and the Tier 1 member interface is down:
/usr/local/bin/dpinger -S -r 0 -i WAN2_RUT -B 192.168.191.2 -p /var/run/dpinger_WAN2_RUT~192.168.191.2~8.8.8.8.pid -u /var/run/dpinger_WAN2_RUT~192.168.191.2~8.8.8.8.sock -C /etc/rc.gateway_alarm -d 1 -s 5000 -l 2000 -t 120000 -A 10000 -D 500 -L 75 8.8.8.8So, this attracts my attention... Why is this bind in private address space? Is this an ISP private shared space?
-
@luckman212 said in 25.07 RC - no default gateway being set if default route is set to a gateway group and the Tier 1 member interface is down:
dpinger -r 1000 -f -i WAN2_test -B 192.168.191.2 -s 1000 -d 1 -D 500 -L 75 1.0.0.1I don't understand why you would expect this to work. The source address for the ICMP packets will be 192.168.191.2. This is private address space, so Cloudflare, who are very security conscious, should simply drop the inbound packet if they received it from an exterior network. No possibility of a response.
When WAN2 is up, the only way I can think of ICMP to Cloudflare working is if the 192.168.191.0/24 (or some other masking) is a shared private space with the ISP or modem, and some entity (presumably the ISP) is performing NAT on the outbound packets.
FWIW, my WAN2 cellular connection operates in exactly this way, except it is in the 100.64.0.0/10 space. The carrier does the NATing in my case. And coincidentally, I also use 1.0.0.1 as my monitor address for that connection...
-
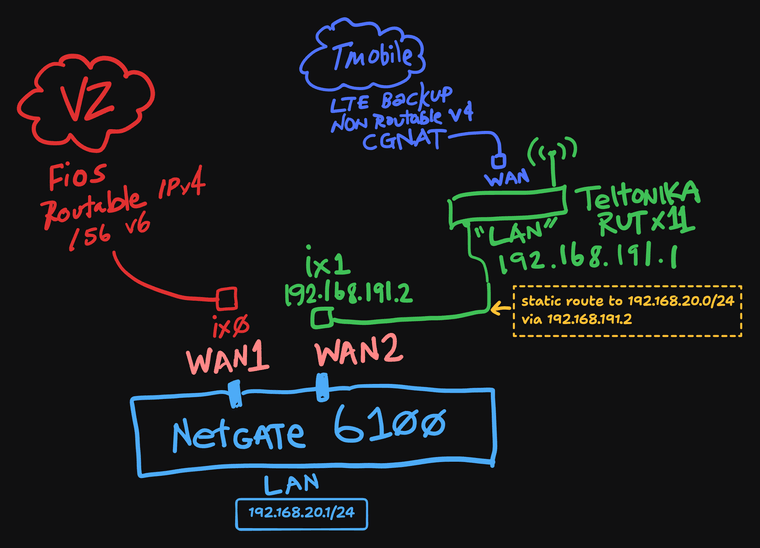
@dennypage I should have provided a diagram. This is not related to Cloudflare. I am using 192.168.191.0/24 as a transit network to connect to an LTE router that receives a CGNAT v4 from T-mobile.
-
@luckman212 said in 25.07 RC - no default gateway being set if default route is set to a gateway group and the Tier 1 member interface is down:
I should have provided a diagram. This is not related to Cloudflare. I am using 192.168.191.0/24 as a transit network to connect to an LTE router that receives a CGNAT v4 from T-mobile.
Yes, it's related to Cloudflare. That's who 1.0.0.1 is.

So yes, you are dependent upon NAT from T-Mobile to make 192.168.191.0/24 work. There is no way to use the 192.168.191.2 source address on the Verizon network. And vice versa. Unless of course you have BGP (which would not work with CGNAT anyway).
With multiple WAN connections, you need the static routes assigned to ensure everything goes out the correct interface.
-
Denny thank you for your help, I think somehow we are now talking about multiple different things.
I have "normal" outbound NAT rules on both WAN1 + WAN2. So by the time a packet has arrived on Verizon's or T-mobile's network, its source address has already been rewritten to the public WAN side of either router in the diagram, right? So Verizon, T-mobile, Cloudflare etc don't know about or care about 192.168.191.0/24. It's up to the router(s): my 6100 as well as the Teltonika RUTX11 (which also does its own NAT of course), to keep track of the states (I'm sure I don't need to tell you any of this).
Yes, in my diagram, I am aware that I am "double-natting" on the WAN2 side. I know the limitations of that, but prefer it to trying to use IPPT (pass thru) mode—which is not stable in my testing as T-mobile rotates IPs very frequently on their LTE network and when pfSense runs it's various
rc.newwanip*scripts it can be mildly disruptive.All that being said, I again want to point out that all of this routing/NATting was and is working fine, as long as I don't unplug my WAN1 cable. That's the strange part, and the new behavior which wasn't happening before I installed 25.07.
Side note: I find Cloudflare anycast DNS IPs (1.1.1.1, 1.0.0.1) to be highly unreliable for ICMP, they frequently drop packets and experience wide latency fluctuations. I don't recommend them as dpinger monitor IPs. YMMV.
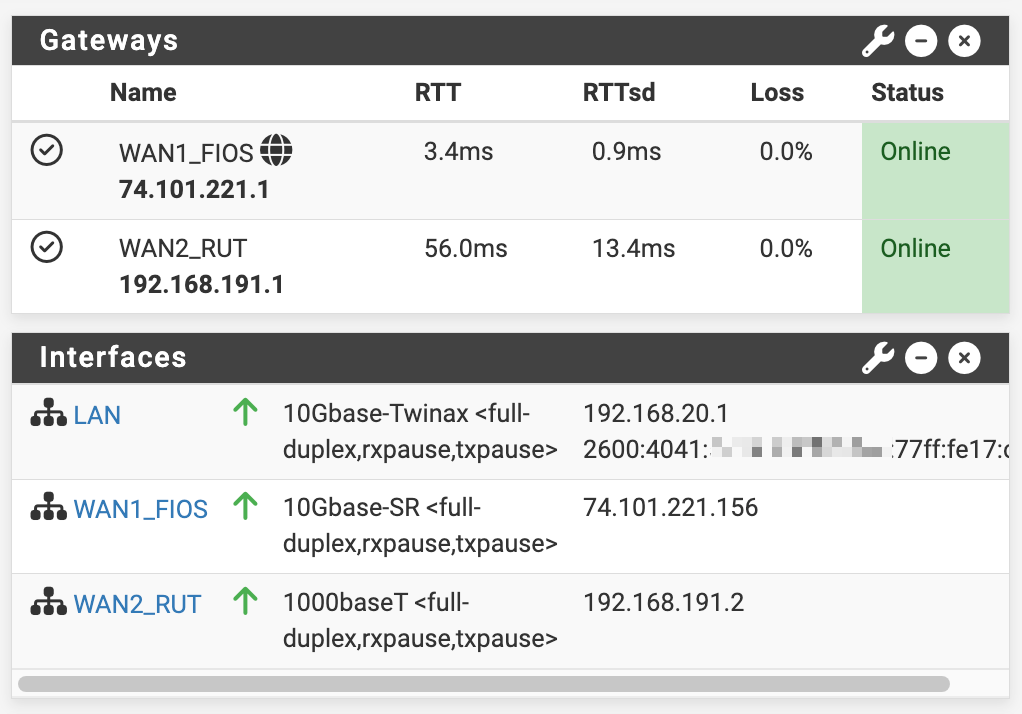
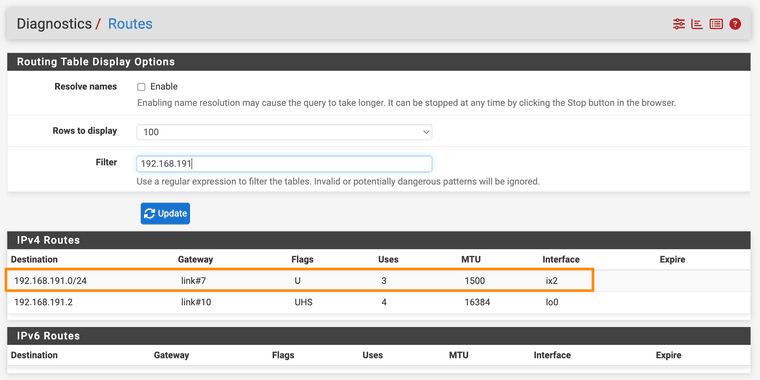
Here are a few more screenshots:
Some pings (with source address binding) and routes
note the hugely different latency, clearly the packets are traversing the LTE network and later the FIOS.
[25.07-RC][root@r1.lan]/root: ping -S 192.168.191.2 8.8.4.4 PING 8.8.4.4 (8.8.4.4) from 192.168.191.2: 56 data bytes 64 bytes from 8.8.4.4: icmp_seq=0 ttl=112 time=58.607 ms 64 bytes from 8.8.4.4: icmp_seq=1 ttl=112 time=57.743 ms 64 bytes from 8.8.4.4: icmp_seq=2 ttl=112 time=61.948 ms 64 bytes from 8.8.4.4: icmp_seq=3 ttl=112 time=57.283 ms ^C --- 8.8.4.4 ping statistics --- 4 packets transmitted, 4 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 57.283/58.895/61.948/1.825 ms [25.07-RC][root@r1.lan]/root: ping -S 192.168.20.1 8.8.4.4 PING 8.8.4.4 (8.8.4.4) from 192.168.20.1: 56 data bytes 64 bytes from 8.8.4.4: icmp_seq=0 ttl=120 time=3.940 ms 64 bytes from 8.8.4.4: icmp_seq=1 ttl=120 time=3.257 ms 64 bytes from 8.8.4.4: icmp_seq=2 ttl=120 time=3.770 ms 64 bytes from 8.8.4.4: icmp_seq=3 ttl=120 time=3.185 ms ^C --- 8.8.4.4 ping statistics --- 4 packets transmitted, 4 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 3.185/3.538/3.940/0.324 ms [25.07-RC][root@r1.lan]/root: ping -S 74.101.221.156 8.8.4.4 PING 8.8.4.4 (8.8.4.4) from 74.101.221.156: 56 data bytes 64 bytes from 8.8.4.4: icmp_seq=0 ttl=120 time=3.074 ms 64 bytes from 8.8.4.4: icmp_seq=1 ttl=120 time=2.985 ms 64 bytes from 8.8.4.4: icmp_seq=2 ttl=120 time=2.823 ms 64 bytes from 8.8.4.4: icmp_seq=3 ttl=120 time=3.022 ms ^C --- 8.8.4.4 ping statistics --- 4 packets transmitted, 4 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 2.823/2.976/3.074/0.094 ms [25.07-RC][root@r1.lan]/root: route -n get 192.168.191.1 route to: 192.168.191.1 destination: 192.168.191.0 mask: 255.255.255.0 fib: 0 interface: ix2 flags: <UP,DONE,PINNED> recvpipe sendpipe ssthresh rtt,msec mtu weight expire 0 0 0 0 1500 1 0 [25.07-RC][root@r1.lan]/root: route -n get 8.8.4.4 route to: 8.8.4.4 destination: 0.0.0.0 mask: 0.0.0.0 gateway: 74.101.221.1 fib: 0 interface: ix0 flags: <UP,GATEWAY,DONE,STATIC> recvpipe sendpipe ssthresh rtt,msec mtu weight expire 0 0 0 0 1500 1 0Gateways + Interfaces
System > Routing
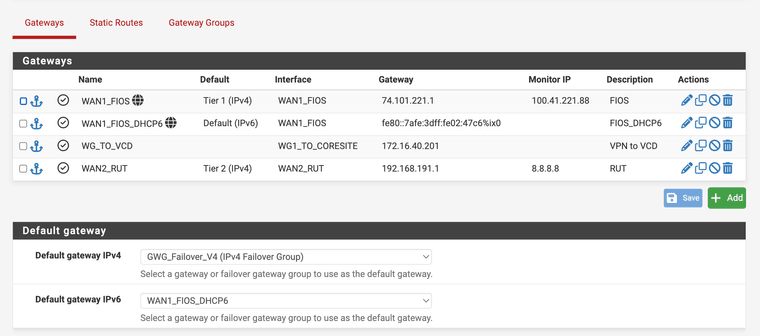
Routing > Gateway Groups

Diags > Routes showing route to 192.168.191.0/24 via ix2
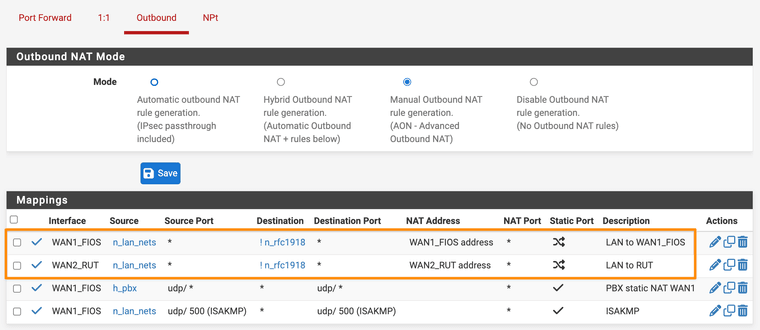
Outbound NAT rules showing 1 for each WAN if ! → rfc1918 dest
My "rfc1918" alias definition
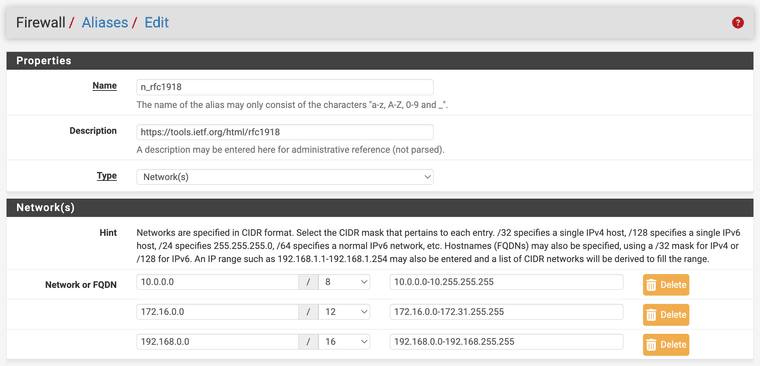
(yes I know 25.07 now has its own native
_private4_for the same...) -
To be clear, does it work as expected if you allow it to create the static route?
Sorry @stephenw10 I missed this question before, yes I just tested it—removed the
dpinger_dont_add_static_routeoption from WAN2, and failover works normally again.There should not need to be a static route to 8.8.8.8 bound to WAN2, and in fact requiring such a thing would be very problematic (all DNS queries would be routed over my slow LTE connection...). Also, to say again, this used to work, so feels like a regression. What I wrote above about having a system with literally no default route makes no "sense".
-
@luckman212 said in 25.07 RC - no default gateway being set if default route is set to a gateway group and the Tier 1 member interface is down:
Sorry @stephenw10 I missed this question before, yes I just tested it—removed the dpinger_dont_add_static_route option from WAN2, and failover works normally again.
This is as expected. I don't see Multi-WAN monitoring working correctly without having static routes for the monitor addresses. Btw, make sure you enable static routes for both gateways.
I cannot explain why it appeared to work previously. Perhaps some interaction with Floating States? @stephenw10 might have thoughts on this.
The only other possibility that occurs to me is that there might have been a configuration interaction if you were using the same destination as a DNS server with a gateway set in DNS Server Settings--see the doc on DNS Resolver and Multi-WAN. I can't speak directly to this because I've never used that style of configuration for DNS. Probably just a red herring, but worth a check.
The issue with routing all DNS queries via the wrong WAN interface can easily be addressed by not using the same address for DNS that you use for monitoring. Instead of Google or Cloudflare for DNS, I recommend using DNS over TLS with quad9. Better security, and you don't expose your queries to your ISPs.
Regardless, I'm glad you have it working.
-
I wouldn't consider this current state "working" - I really want to know why things break so badly when I don't have a static route to both monitor IPs. As I proved in my screenshots and command output above, the routing works as expected without the routes.
The bug / problem is because, when WAN1 loses its gateway, the gateway code for some reason ends up removing BOTH gateways and leaving the firewall without any default route AND apparently no route to the next hop on WAN2 either, which to me seems like a regression and not something I would consider ready for wide release.
I'd like to help debug this by whatever means necessary. I mentioned in the top post that I will share my configs. or invite Netgate to take a direct look via remote access, etc.
-
@luckman212 I consider the static routes to be required for correct Multi-WAN monitoring. Unless there is something doesn't work correctly with the static routes in place, I don't see an issue worth pursuing.
However, I don't speak for Netgate -- perhaps they have a different opinion and will be willing to explore it further.
-
@luckman212 said in 25.07 RC - no default gateway being set if default route is set to a gateway group and the Tier 1 member interface is down:
the gateway code for some reason ends up removing BOTH gateways
Maybe it thinks, it has no working gateways anymore because PING failed for all at the same time because everything got routed through the now down gateway. It looks like it is working like expected at this point. Maybe that checkbox should be removed.

-
@Bob.Dig I don't think that's what's happening. If you scroll up a few posts to where I have a section called "Some pings (with source address binding) and routes" you can see that the pings are traversing each separate gateway (you can tell from the vastly different latencies).
I just ran a few tcpdumps to confirm as well, the packets are definitely egressing out the separate correct gateways without the static routes:
[25.07-RC][root@r1.lan]/root: tcpdump -ni ix0 dst host 8.8.8.8 tcpdump: verbose output suppressed, use -v[v]... for full protocol decode listening on ix0, link-type EN10MB (Ethernet), snapshot length 262144 bytes ^C 0 packets captured <<–– ✅ no packets to the monitor IP seen on the WAN1 interface 857 packets received by filter 0 packets dropped by kernel [25.07-RC][root@r1.lan]/root: tcpdump -ni ix2 dst host 8.8.8.8 tcpdump: verbose output suppressed, use -v[v]... for full protocol decode listening on ix2, link-type EN10MB (Ethernet), snapshot length 262144 bytes 06:22:32.463054 IP 192.168.191.2 > 8.8.8.8: ICMP echo request, id 22849, seq 36, length 9 06:22:37.497085 IP 192.168.191.2 > 8.8.8.8: ICMP echo request, id 22849, seq 37, length 9 06:22:42.500047 IP 192.168.191.2 > 8.8.8.8: ICMP echo request, id 22849, seq 38, length 9 ^C 3 packets captured <<–– ✅ packets are being sent via WAN2 166 packets received by filter 0 packets dropped by kernel -
@stephenw10 @marcosm Since you guys seem to be unable to replicate this (?) would you be able to send me the
25.07-RELEASEimage to test with? I see on redmine (e.g. here, here, and here) that there's a build you guys are testing on tagged-RELEASE(built on 2025-07-22). Maybe there are some small differences in that build that are affecting my results? I've lost a good portion of my weekend on this and growing more desperate. -
I am able to reproduce the issue by checking the option to not add the automatic route and failing over to a DHCP WAN from a static WAN. Arguably this is not a valid setup when you want to monitor multiple WANs hence the issue of it not working is not in itself necessarily a bug. Note that even if the service is bound to an address or interface, as mentioned, the OS still decides where that traffic will be routed. That's why you see the state with origif for ix0 - pf overrides the OS and sends it over ix2.
The fact that the system is left without a default gateway does warrant further digging. From looking at the code I see that it's left without a default gateway because at that moment both gateways have been marked as down. I will need to dig further to understand why it's marked as down and if that's an accurate status at that point.
-
@marcosm Thanks very much for looking. I would't really mind leaving the static route, IF there were any pingable hosts along the nearby path that I seem to be able to derive from traceroute on that WAN2 (Tmobile 4G) connection. I don't want to use 8.8.8.8, 8.8.4.4, 1.1.1.1, 9.9.9.9 etc because then ALL traffic to that host will flow over the backup (slow, expensive) connection.
I enabled the hidden
system/route-debugoption, and am still trying to track down the chain of events that leads pfSense to marking WAN2 down and removing the default route. But any help would be most appreciated and let me know if I can provide anything more. -
@luckman212 said in 25.07 RC - no default gateway being set if default route is set to a gateway group and the Tier 1 member interface is down:
I don't want to use 8.8.8.8, 8.8.4.4, 1.1.1.1, 9.9.9.9 etc because then ALL traffic to that host will flow over the backup (slow, expensive) connection.
Is that really the case?
Surely both the main and backup internet connection can reach all internet sites but the route taken by each packet does not just depend on which route has reached that site in the past. -
@luckman212 said in 25.07 RC - no default gateway being set if default route is set to a gateway group and the Tier 1 member interface is down:
I don't want to use 8.8.8.8, 8.8.4.4, 1.1.1.1, 9.9.9.9 etc because then ALL traffic to that host will flow over the backup (slow, expensive) connection.
If you want to monitor the backup connection, something has to flow over that connection. No way around that. If you need a public DNS server as a target, just pick an address that you are not using as an active DNS server. There are lots to choose from, even from the common DNS hosts (8.8.8.8, 8.8.4.4, 1.1.1.1, 1.0.0.1, and your ISP's DNS servers). You don't need all of them as DNS servers.
However, if you absolutely don't want anything going over the backup connection, another option would be to just disable gateway monitoring on the backup connection altogether. Given your setup, I expect that you have disabled the gateway monitoring action on the backup connection, so the monitoring of the backup connection is really only for human consumption.
-
@Patch said
Is that really the case?
Surely both the main and backup internet connection can reach all internet sites but the route taken by each packet does not just depend on which route has reached that site in the past.Yes, it is really the case - if you set a monitor IP to e.g. 8.8.8.8, a static route gets created which forces all traffic over that gateway. Even if it's not your active/primary gateway.
-
@luckman212 what a weird way of coding the monitoring.
I had assumed if monitoring was specified for a particular gateway then the monitoring packets would be sent over the monitored interface without implying any other changes to the routing policy.
Similar to when pinging from an interface doesn't imply all routing to that server suddenly also must go through that interface.
-
@Patch said in 25.07 RC - no default gateway being set if default route is set to a gateway group and the Tier 1 member interface is down:
I had assumed if monitoring was specified for a particular gateway then the monitoring packets would be sent over the monitored interface without implying any other changes to the routing policy.
Similar to when pinging from an interface doesn't imply all routing to that server suddenly also must go through that interface.
Routing in Unix is IP destination based rather than source based. The way monitor packets are forced out an interface is with a static routing rule that says "If you are sending a packet to this IP address, the packet must be sent out this interface." This means that all packets destined for that IP address will out the interface specified.
-
I saw 25.07 release was published. So I guess this is a moot point for now, as the next major release won't be before 25.11 at the earliest. I will keep monkeying around I guess.
@dennypage if what you wrote is true, then how can you explain the tcpdumps above, when both WAN1 and WAN2 are "up", and I have the "don't create static routes for monitor IPs" option enabled on WAN2, and I see no packets to 8.8.8.8 leaving ix0—they are 100% going out on ix2, confirmed with tcpdump and the 50+ms latency indicative of the 4G connection, and at the same time my default route being via the WAN1/FIOS... ?