25.07 unbound - pfblocker - python - syslog
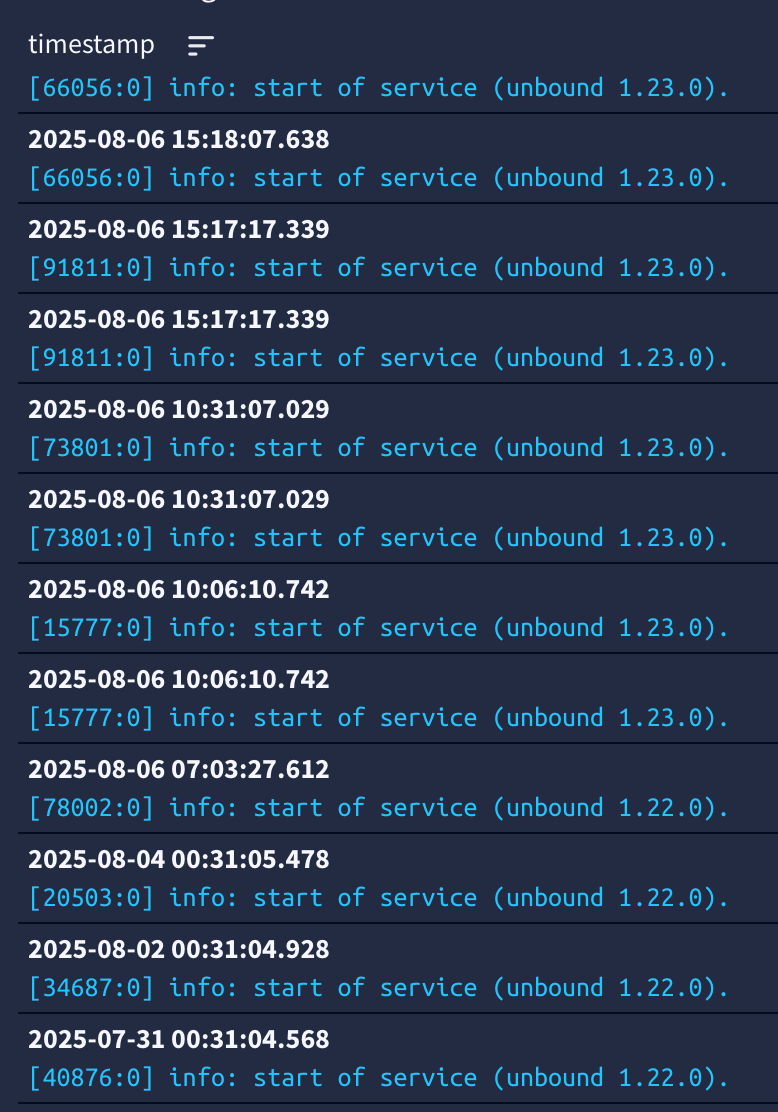
-
Yup that's what I see with a target that doesn't respond to arp. I'd guess it gets into a loop logging the host is down and then trying to send that to the syslog server. Repeat!
I was only able to replicate the service failing when using a target that actually responds to the traffic with refused.
-
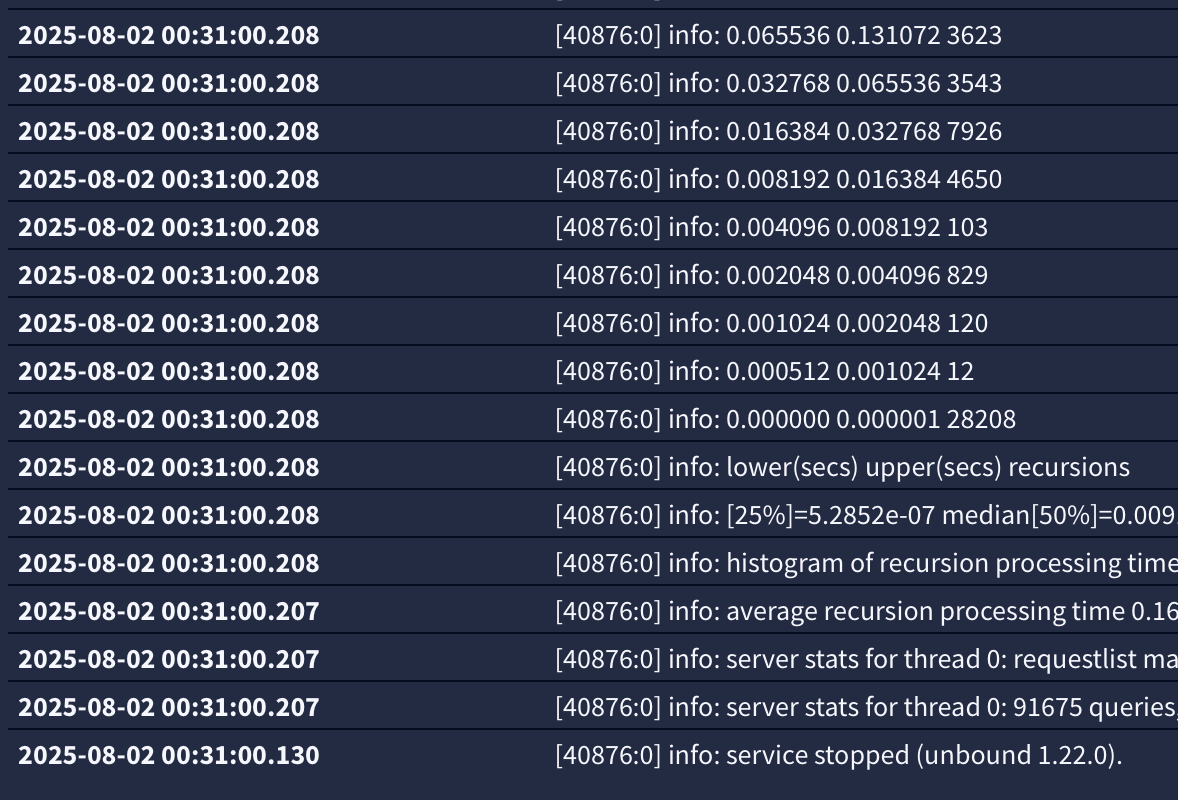
There you go, order matters (but also n both cases there is no indication of a Host is Down or connection refused.
bottom up in the log changed to add a working server in the second spot
(.35) (.2) .35 is offline
switch them
(.2) (.35) . 35 is offlinenotice nginx logged it but syslog itself says nothing in either case ...
That explains why I don't see host down or connection refused in production. it is being masked by having two servers, (in both cases)
I'm going to flip the order in production to see if it changes the overall "it resumes logging" when it goes off line and comes back up.
-
so flipping the order on production (.2) (.35). taking .35 offline and back. did not resume the logging to that IP - I still had to kick it. (.2) as before got everything in both cases
Syslog itself still didn't log (down or refused) but at least I have another reference, the nginx message now shows,
same as on the test box. which is at least better then nothing.back to using my auto kick start script for now.
Carry on.
Thanks -
@jrey @stephenw10 - I'm adding to this thread; I hope that's acceptable...
I have a somewhat different and perhaps more simple environment with a Netgate 4200 now updated to 25.07.1 .
My issue is (also) syslogd dying. In my case, I run most infrastructure services elsewhere on my network, so I'm not running e.g. unbound (nor wireguard or dhcpd).
I have syslogd on the 4200 set to send logs to a server running a containerized Logstash. That's a non-HA setup.
I can also add that it appears that pfSense syslogd doesn't die at the time the target service goes down - it dies when the service is transitioning to being up.
I'm curious as to whether anyone has come up with any workarounds to this - other than writing some sort of script to run on the 4200 - such as configuration that might not be accessible via the UI?
Happy to help if there's any debugging in my environment that could clarify things.
Thanks!
-
@kmp said in 25.07 unbound - pfblocker - python - syslog:
I can also add that it appears that pfSense syslogd doesn't die at the time the target service goes down - it dies when the service is transitioning to being up.
the behaviour seems to be slightly different depending on having 1 or 2 receiving systems setup - specifically as to if it syslog continues, dies outright and/or actually logs anything about the trouble it has encountered. clearly however if one remote dies, one continues, so the syslogd doesn't really die. @stephenw10 never really mentioned if it was going down or trying to recover, but in that redmine, there is a brief comment about "it takes about 10 minutes".
I think we are just in a hold and see what happens upstream as the root cause is clearly in syslogd - the redmine created the redmine (link above in thread) but unless they work some release magic, it will likely be a while. I had actually thought of using the Boot environment and just rolling back to 24.11 where it worked fine but then the little script I wrote is working fine on recovering from the issue, so here we are..
thanks for the offer though.
-
It seemed to be around 10mins at the time but having tried to replicate it with debugging it's not that simple. I failed to do so in the time available. I'll be re-testing that next week.
-
I noticed that 2.8.1 RC released with a note about syslogd so I went to track down what actually changed from the redmine numbers final looked here to see "this change and description last week"
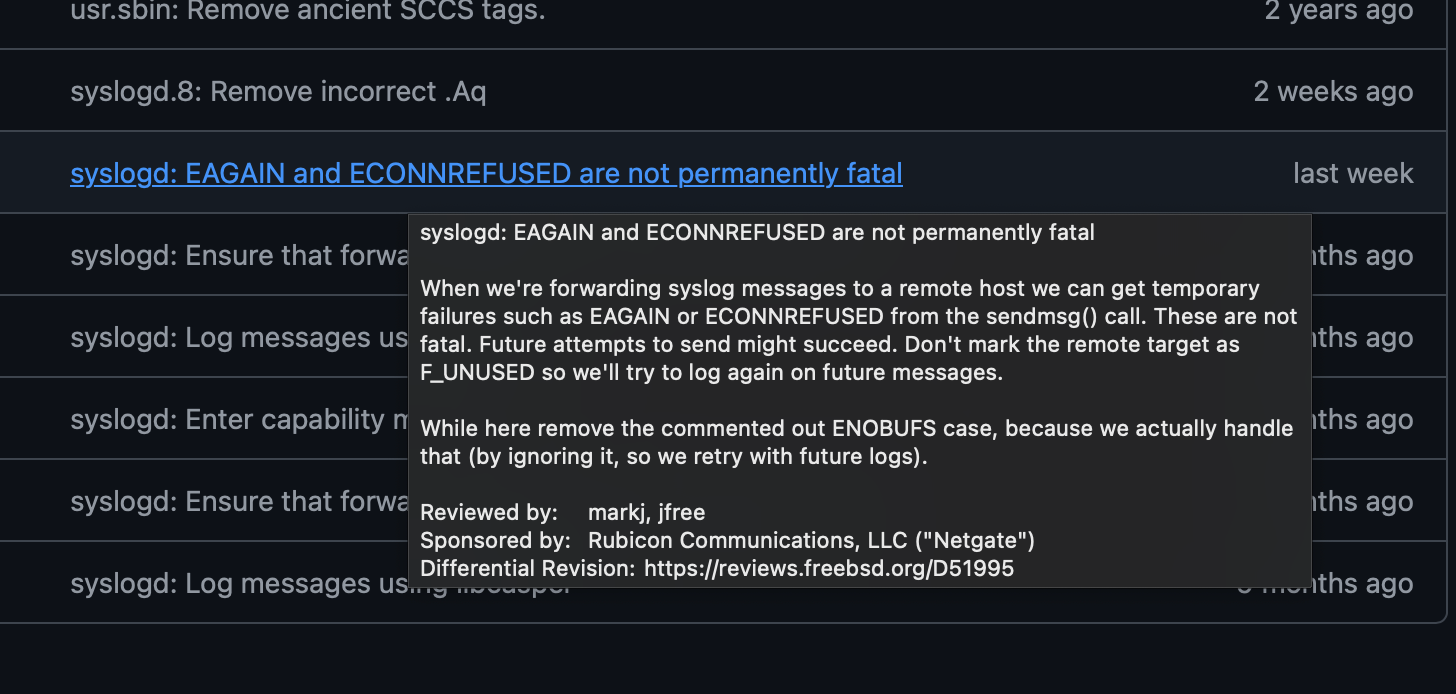
did this make the 2.8.1 RC release ? wasn't clear from the timing and notes. I had previously upgraded / tested 2.8 as part of this issue and confirmed the failure there --
the diff associated specifically with 2.8.1 RC doesn't list this so I'm guess it is not there.? (but sometimes stuff gets built and not include in the notes)
if this noted change made the cut I'll jump through the hoops on 2.8.1 RC and test it, but if it for sure missed the cut not in this RC, I'll wait..
Thanks
-
I'm away at the moment and can't check directly. However I don't believe it includes that. 2.8.1 is intended to be as close to 25.07.1 as possible so that testing/bugs apply similarly to both. It looks like it was the source address binding that was fixed there.
I'll be back on this next week. -
J jrey referenced this topic on
-
Im having the same issue.
Im sending to elastic angent and each time I kill the elastic angent and it stops listening on port 9001 the syslog stops sending.

I do see a weird destination unreachable ICMP before that on my log collector host.
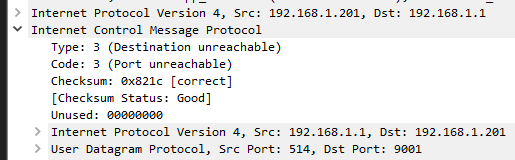
-
It would be the recovery from that -- look at the code referenced - syslogd and the changes are specifically related to EGAIN and ECONNREFUSED messages (they were not being handled) -
not having them processed causes all kinds of interesting artifacts -and different when sending to a single server vs multiple servers (I have 2, and the order they are listed also changes the behaviour that is if one goes down and the other does not, which is my case)
Because in my environment I know exactly when the issue is going to occur because of a fixed schedule maintenance window on one of the syslog servers) I have a script that monitors that receiving device and restarts syslog accordingly after it detect the system/port are back and available)
Other than that "tiny little issue" as far as I can tell it is rock solid in processing messages.

The only option for us currently is to wait for the new build of syslogd - so that it just recovers like it did before, back in the 24.11 days.
-
I'm running into a similar issue after upgrading to 25.07.1.
I see this in my logs:
2025-09-02 10:51:05.870660-07:00 syslogd - kernel boot file is /boot/kernel/kernel 2025-08-30 04:48:40.984805-07:00 syslogd - sendto: Connection refused 2025-08-29 02:28:48.148564-07:00 syslogd - kernel boot file is /boot/kernel/kernel 2025-08-23 04:47:30.000287-07:00 syslogd - sendto: Connection refused 2025-08-19 11:35:12.527643-07:00 syslogd - kernel boot file is /boot/kernel/kernel 2025-08-19 11:30:45.904435-07:00 syslogd - exiting on signal 15 2025-08-18 18:21:26.032560-07:00 syslogd - kernel boot file is /boot/kernel/kernel 2025-08-16 04:47:40.955468-07:00 syslogd - sendto: Connection refusedI get
sendto: Connection refusedin my logs, and that's when syslogd dies.You can see this almost always happens for me around the same time at 4:48AM. It's also every 7 days.
I run Graylog via docker on my server. Every Saturday morning I backup all of my docker containers starting at 4 AM, and this means stopping each container while it's being backed up.
I tested this today by stopping my Graylog container, and in less than 2 hours syslogd had stopped running on pfSense.
-
Yup, I'm back on this now. Trying to replicate with debugging....
-
@stephenw10 I tried testing this a few times today. Twice it took about 2 hours before it stopped, and a third time it took maybe 4 hours before it stopped.
I'll try testing some more, but it's not consistent.
pfSense will immediately post that
sendto: Connection refusedlog event once I shut down Graylog. But then 1 to maybe 4 hours later, thesyslogdservice stops. -
the "if it stops" is based entirely on number of messages (memory available / used) and several other factors, like sending the results to more than one server.
on the other hand, the bottom line is the current version of syslogd is not currently handling the EAGAIN and ECONNREFUSED conditions. Looking at the code repository these were only added back to the code a couple of weeks ago and after the last release. These are not, as noted in the screen capture of the "change" (see above) not permanently fatal (from a messages point of view) and therefore needed to be in list of events "that could happen" but that would then eventually just retry when the remote comes back on line.
-
@stephenw10 said in 25.07 unbound - pfblocker - python - syslog:
Trying to replicate with debugging....
for clarity, you mean in the code with the fix right ?


-
Not yet unfortunately. Just trying to make it fail with debugging enabled. Seems to really want to not fail!
-
@stephenw10 said in 25.07 unbound - pfblocker - python - syslog:
Yeah it look like this only happens when the remote host actually responds with 'refused'
Exactly -
take the remote offline
wait around 10 minutes (the service window in my case is actually 13-15 minutes) (not sure you have to, there just needs to be be a consistent flow of messages from the same sender "channel")
bring the remote back (it will respond to ARP as soon as the IP is on) but the logging port is not open yet (takes a bit for (say Graylog services to start, but it doesn't have to be Graylog, I can do it with the other receiving server as well) - the system responds with ECONNREFUSED in that window (and you have the scenario described in the code change)typically there is a delay between the IP being up and the port being open, messages in this timeframe will cause syslogd to do silly things. Crash outright, keep going if multiple remotes are involved, spew messages to the bitbucket (the memory swap observation) etc
timing is everything. there is little one can do with the gap between IP available and port available. (the timeframe during which the connection is refused)
Case 2 (I think but not verified) take the remote server with a working receiver, and bring the IP back without the logging server. (I think that describes the same case as one of the other posters talked about, where it just hangs (and dies) if the server goes away and/or comes back without sys logging server) at pfsense boot. effectively the same thing when pfsense boots it comes back ARP is alive but there is no logging port open, so you get ECONNREFUSED
-- The "how long it takes" to fail outright (if at all) varies, likely depending on all the other system factors, memory usage (available), number of syslog messages being sent and likely number of servers it sends to. none of which seem relevant. the connection is not coming back once it is refused and it will eventually just crash, almost immediately or hours later.
anyway hope you can recreate it again.
-
@jrey @stephenw10 So, in my case (just ran a test, but this seems somewhat consistent), syslogd dies within 1-3 minutes of the sink going down ("SENDTO: connection refused") though I can't tell exactly... because it doesn't log a message when it dies.
Here's another question, however: I had been thinking of writing a script to automatically restart syslogd - but something strange happens if I issue
sudo service syslogd restart: log messages are formatted differently.Before (restart with
servicecommand):<134>1 2025-09-03T16:24:08.900145-04:00 router0.kmpeterson.net filterlog 65829 - - 4,,,1000000103,igc3,match,block,in,4,0x0,,126,30636,0,none,6,tcp,52,131.100.72.48,73.142.180.157,80,59580,0,S,7528752,,8192,,mss;nop;wscale;nop;nop;sackOKAfter (restart with
servicecommand):<46>Sep 3 16:33:50 syslogd: restartRestarting using the pfSense UI (Status
 ︎Services︎syslogd) reverts (?) back to what I expect (to parse - it breaks my monitoring given the VERSION field and time of day formatting). The logs UI shows the formatting as different as well.
︎Services︎syslogd) reverts (?) back to what I expect (to parse - it breaks my monitoring given the VERSION field and time of day formatting). The logs UI shows the formatting as different as well.So, as usual, I'm wondering if I'm missing something... also I see log entries every 3 or 4 or 5 minutes implying that syslogd has restarted, along with a cron job every minute running
/usr/sbin/newsyslog- any idea what is happening with these entries? (Happy to get a reference to look up - FreeBSD isn't my primary distro).Thanks again!
-
You can add syslogd in the Service Watchdog package to restart it automatically if needed.
-
@stephenw10 I did not know about that. Thanks - implemented and it's working!
-
J jrey referenced this topic on