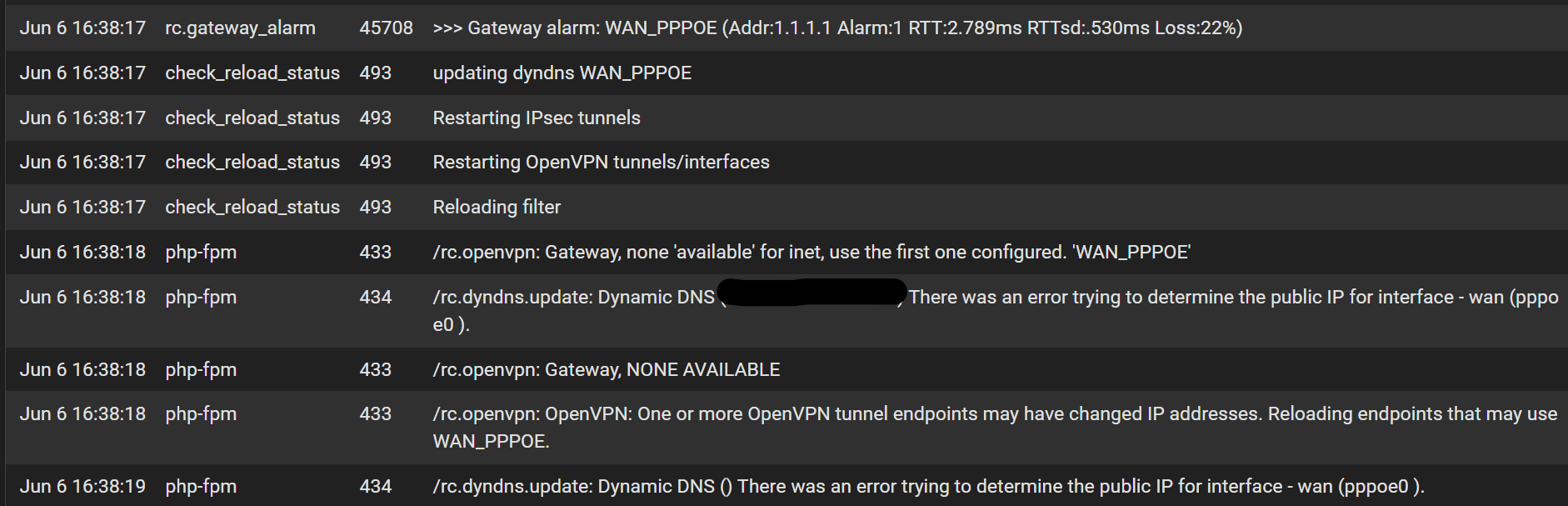
periodic packet loss with new if_pppoe backend + high interrupts (post CE 2.8.0 upgrade)
-
Mmm, it is. And I hate coincidences.
How many DHCP leases do you have? What lease time?
To hit that issue it has to see a renewal rate that eventually exceeds the reload rate that Unbound can manage. Which seems unlikely on that hardware.
-
@stephenw10 I just checked. 11 leases, default lease time of 7200 seconds. I haven't changed my network topology or devices since the upgrade so I don't think I'm getting anywhere near the reload rate limit.
-
Mmm, yeah that's nothing on that hardware.
Does Unbound log a bunch of restarts in the DNS log when it happens?
-
@stephenw10 nothing at all in the logs. I've now tried all permutations of KEA/ISC, if_pppoe and original and I'm running into the same issue so this is a mystery that no longer aligns with the title of this post. Moving off if_pppoe only seems to prolong the time before the crash. I tried a fresh install last night and restore of the config - saw the same system lockup within 10 hours. The symptoms are now very consistent and I can catch the system in this locked state. Unbound first consumes a core and all devices lose internet access. Then the large traffic flow appears from WAN according to the monitoring graphs.
-
Hmm. So how do you have Unbound configured? There's got to be something it's doing that most people don't hit.
You could try turning up the logging in Unbound.
Is it accidentally listening on WAN? Are you being used as part of a DNS amplification attack maybe?
-
@stephenw10 I'll try increasing the log verbosity - I've actually never touched the unbound settings so they should be default.
I surely hope it's not some sort of attack - these problems coincide to within a few hours of upgrading from 2.7.2 -> 2.8.0 and also occur on a fresh install using the installer.
Is there anything you suggest I do while the system is locked up in this state to get some more information? I'm returning home to the system in this state right now and I can occasionally reach the gui.
-
Check the Unbound Status page (Status > DNS Resolver). Compare those values when this is happening and normal running.
But if you turn up the logging you would see some huge flood of requests if that's what's happening.
-
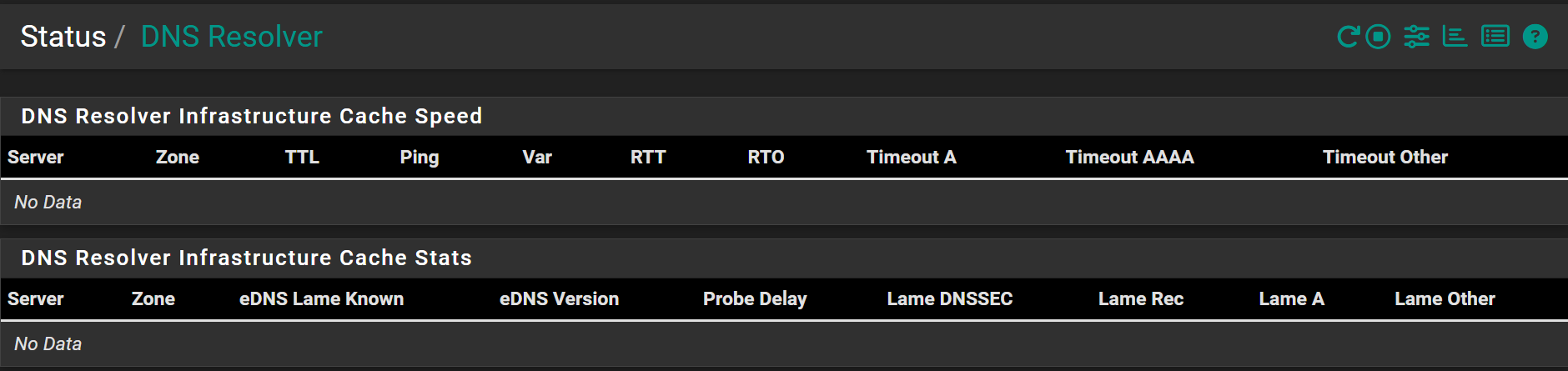
@stephenw10 Its currently stuck in this state, and this is all I see in DNS Resolver status (no data):
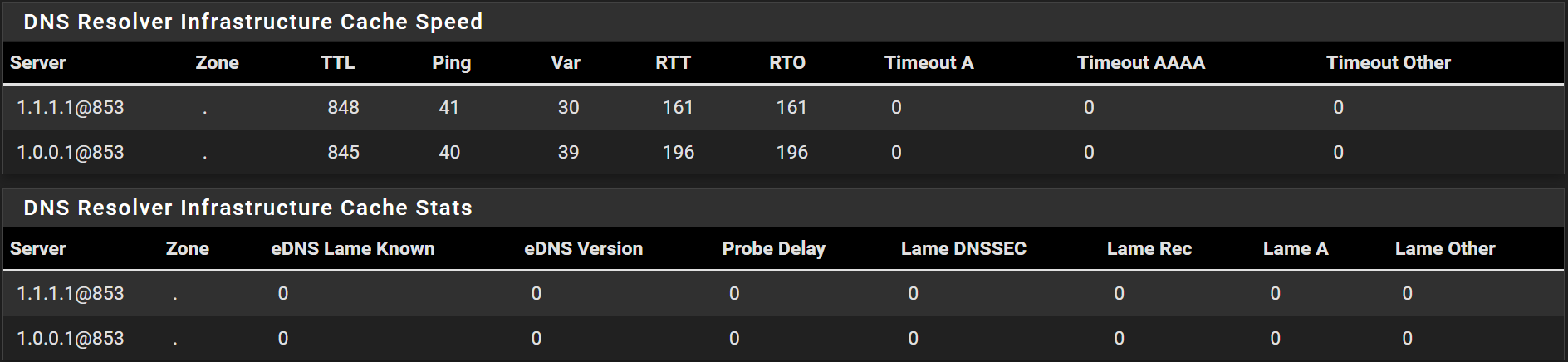
After a reboot I see this:
-
Hmm, so it can't pull stats data from Unbound at that time. It must be very highly loaded.
I would try turning up the logging. It will probably create a very large ammount of logs.
You could also check the states or run a packet capture to try and see what the traffic spike is.
Also check the number of states shown in the monitoring graphs. Does that also spike at the time?
-
Thanks stephenw10. I'm back after a few months of troubleshooting with no success, but some more questions if you could help guide me on this troubleshooting journey.
I purchased new hardware, now with a fresh install of CE 2.8.1 and am seeing the same issues. Disabling gateway actions has eliminated the periodic packet loss panic causinng the system lockup until a reboot, but I'm still seeing unbound suddenly consume a core and become unresponsive.
Curiously, I'm not seeing anything anomalous in unbound logs over multiple failures. However, one thing I'm curious about is if updating url ip aliases might be connected to this failure. Since pfsense 2.7.2 and prior I have had a cron job running
/usr/bin/nice -n20 /etc/rc.update_alias_url_dataevery 5 minutes. This never posed an issue before, but it is the only 'custom' action I have running on both pfsense boxes that have unbound failing after a few days of uptime.
Besides this, now that I have narrowed the issue down to unbound, is there anything else you would suggest I try? States do not noticeably increase during the failure from my monitoring.
-
Hmm, you added that cronjob yourself? Any particular reason?
Do you have an url aliases with a large number of entries?