Playing with fq_codel in 2.4
-
Hey all,
here are some measurements
Setup:
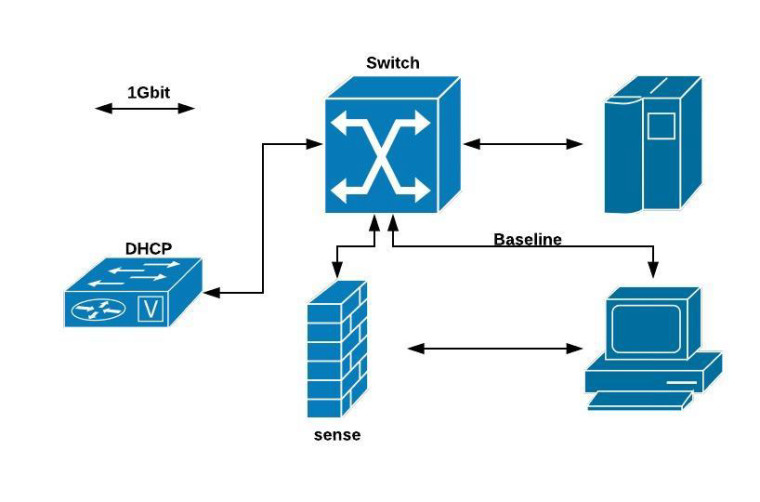
Baseline measurement: Pc1 - Pc2 just via switch no sense involved:
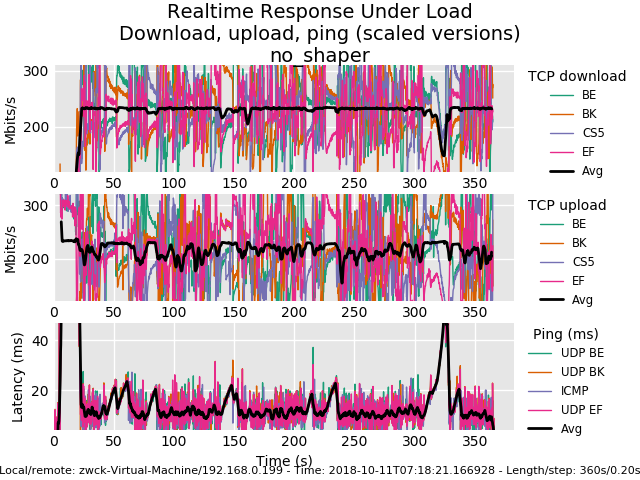
0_1539274374287_rrul-2018-10-11T071821.166928.no_shaper_vm_to_vm.flent.gz
Measurement with sense without shaper:
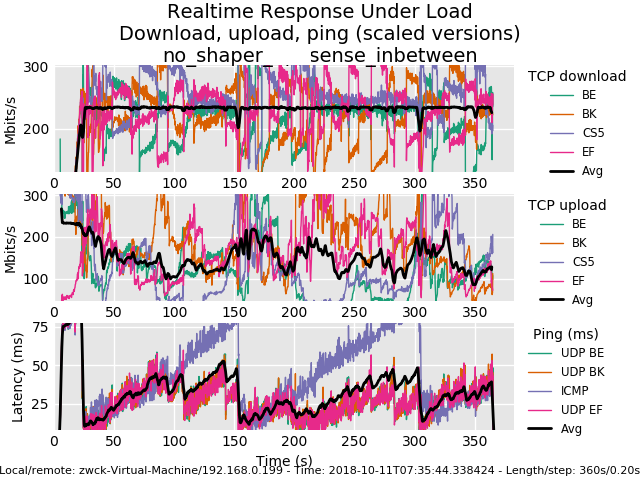
0_1539274525822_rrul-2018-10-11T073544.338424.no_shaper_sense_inbetween.flent.gz
Then I started shaping/playing around(no methodology involved) to 100/100Mbit and played with tuneables.
For me the only tuneables that were usefull were:machdep.hyperthreading_allowed="0" hw.igb.rx_process_limit="-1"For the setup i found out that i only adjusted quantum and turned off ecn.
10000: 800.000 Mbit/s 0 ms burst 0 q75536 50 sl. 0 flows (1 buckets) sched 10000 weight 0 lmax 0 pri 0 droptail sched 10000 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 100ms quantum 1518 limit 10240 flows 1024 NoECN Children flowsets: 10000 10001: 800.000 Mbit/s 0 ms burst 0 q75537 50 sl. 0 flows (1 buckets) sched 10001 weight 0 lmax 0 pri 0 droptail sched 10001 type FQ_CODEL flags 0x0 1024 buckets 0 active FQ_CODEL target 5ms interval 100ms quantum 1518 limit 10240 flows 1024 NoECN Children flowsets: 10001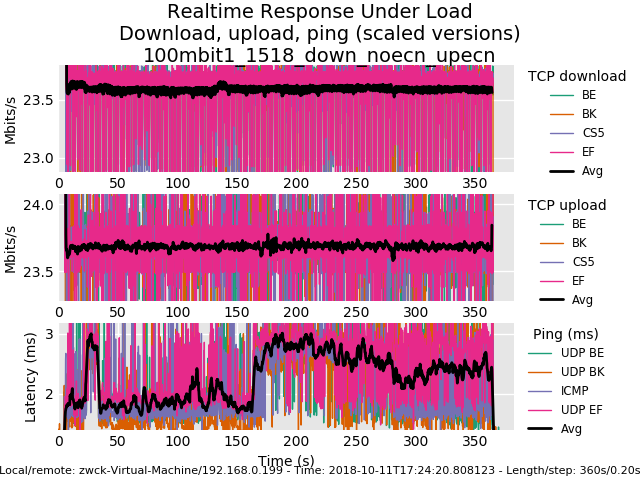
0_1539274939477_rrul-2018-10-11T172420.808123.100mbit1_1518_down_noecn_upecn.flent.gz
Finally i went up to 800Mbit
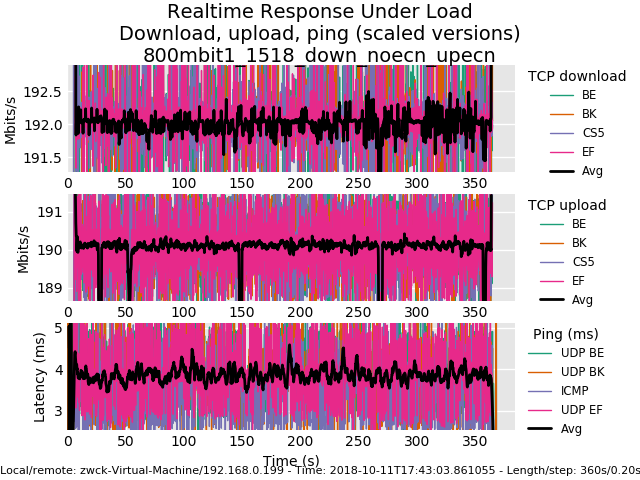
0_1539274972854_rrul-2018-10-11T174303.861055.800mbit1_1518_down_noecn_upecn.flent.gz
maybe its interesting :D
-
@gsakes heh. You were living this whole time at the command line? flent-gui *.flent.gz hit view->everything, select two or more files from the open files, select a different plot type like cdf, switch files around in the tabs.
I run this thing sometimes against 30+ test runs - it uses up every core you have to predict that next plot - it's just amazing tool... it's why we succeeded where others in the field are still painfully looking at tcptrace'd packet captures....
I would knight toke if I could.
anyway, good, thx for the data! cake with ack filtering is actually slightly higher latency than without (it gets rid of more little packets so more big ones fit in), you got .35mbits extra out of your 5mbit uplink, and something in the noise hit you...
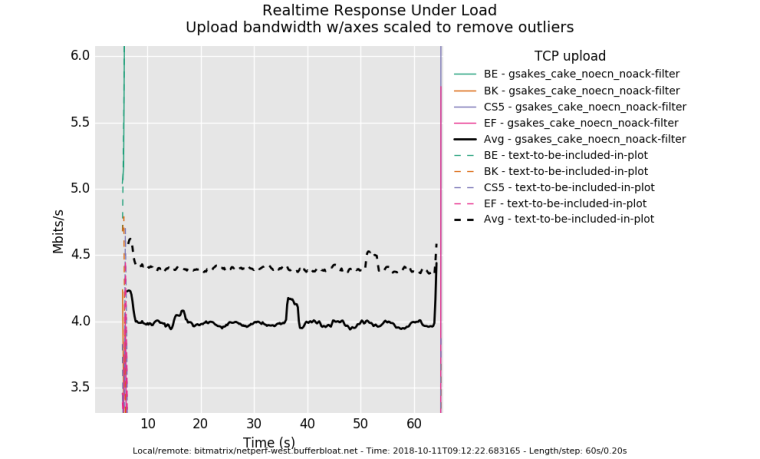
And this shows how tcp occilate less (for the same throughput) by using ecn rather than drop for congestion control.
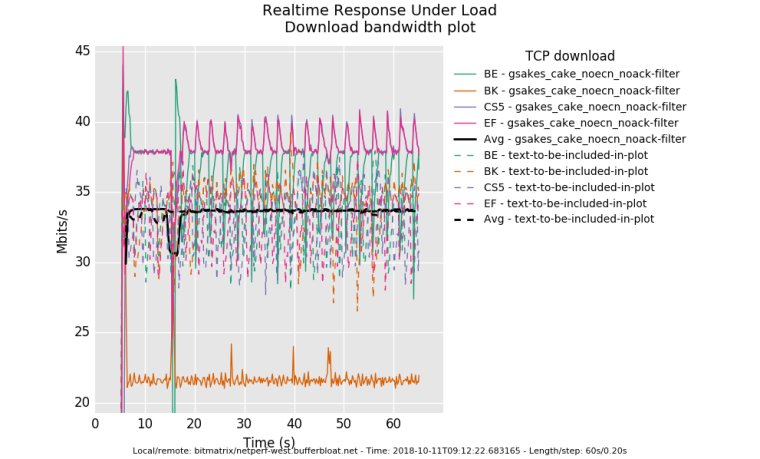
It's subtle, at this rtt, but you can see how data is bursty ? that's head of line blocking for a 35ms rtt against the 20ms sample rate.
a tcpdump is good for observing this.
I've noted earlier that I'm not all that huge on ecn. I can totally live with tcp blocking for 35ms (compared to hundreds of the pre-fq_codel-era) and with drop as the sole indicator of congestion. At rtts of greater than 100ms for human interactive traffic, well, ok, ecn might be good... but for that I stopped using ssh and switched to mosh.
wide deployment of ecn worries me. But it's happening anyway and why not get more folk playing with it while being aware we might break the internet with it...
there's other benefits in cake like per host fq... kind of hard to test with using this. One example of seeing per host fq work better is to load up a web page benchmark of some (sane) kind on a different box while rruning things like the rrul. We used to use chrome web page benchmarker, but that broke... even then fq_codel still does really well on web traffic...
... those extra .35 mbits from the ack-filter came hard. 6 months worth of work by 5 people.... over 9 months total... 12 if you include the initial research into the rfcs.
-
@dtaht heh, that'll teach me to start using new tools at 03:30am in the morning - yeah totally tunneled on flent, didn't even bother looking at the GUI:)
Yep, I get slightly better results turning off ecn, but leaving ack filter on - less latency, very slightly less throughput. What you and the bufferteam did was well worth it; I'm going to call this 'QOS 2.0' even though the term might already exist:)

-
All this flent testing was a bit inspiring. So I just setup a new server in linode's cloud, in singapore.taht.net . Turns out their current default distro enables fq_codel by default and also bbr. flent and irtt were part of their ubuntu 18.04 LTS package set, so a few minutes later I had a server running. I left the default to cubic. Three things to note:
A) At such a long rtt, there is no tcp that will work particularly well. Built into BBR is a RTT check which I think defaults to 200ms, and singapore is 190ms from california. BBR's primary use case is from a datacenter usually located MUCH closer to you.
If you are located on, like, the island of mauritus (as one of our more devout testers is), his typical rtt was 320ms and he found it necessary to up target and interval to 30 and 300 respectively.
B) fq_codel has two tunables that normally you shouldn't touch. target is the target local delay, and should be 5%-10% of the interval except when that 5% is greater than the MTU and I fudge factor that even more at lower bandwidths. 5ms is a good default above 4Mbit. The interval should be your normal (say 90%) maximum rtt for the flows you have in your locality. So if you are in england, you can fiddle with lower RTTs - like 30!, on the continent, I've seen people using 60 - and in most cases, 100 is just fine.
on wifi we found it helpful to up the target to 20ms during our early tests, in my deployment on real networks, I'm finding 5% to be "just fine", but 20 is the kernel default. I would like to make that tunable.
C) BBR does not pay much attention to the codel part of fq_codel.
since y'all are having such fun with flent, care to try irtt? :)
As for singapore, well, I thnk y'all are getting better at pattern recognition, but you'll see not much of a good one running as far as to singapore, and perhaps that's good input for a fuzzy recognition algorithm...
-
When I got home, I ran the dslreports test, with codel+fq_codel at 290/19, from my laptop on wifi. The results were very good, especially considering i was concurrently watching hulu.

netperfrunner.sh v6:
2018-10-11 16:19:53 Testing netperf-west.bufferbloat.net (ipv6) with 4 streams down and up while pinging gstatic.com. Takes about 60 seconds. Download: 242.21 Mbps Upload: 7.98 Mbps Latency: (in msec, 61 pings, 0.00% packet loss) Min: 35.790 10pct: 38.426 Median: 44.195 Avg: 45.566 90pct: 52.161 Max: 65.077netperfrunner.sh v4:
2018-10-11 16:21:14 Testing netperf-west.bufferbloat.net (ipv4) with 4 streams down and up while pinging gstatic.com. Takes about 60 seconds. Download: 229.08 Mbps Upload: 12.07 Mbps Latency: (in msec, 30 pings, 50.82% packet loss) Min: 61.389 10pct: 62.261 Median: 67.240 Avg: 67.030 90pct: 70.341 Max: 77.469 codeflent rrul46:

0_1539293261991_rrul46-2018-10-11T161530.029411.290mb_19mb.flent.gz ]
I need to move some stuff around in an attempt to free up a switch port in the basement to test from this machine while wired. Either that, or i'll disconnect lan one day. holy packet loss over v4.
-
Three more tests; all were run with the same up/down b/w parameters, within a few minutes of each other.
1) PFSense - no shaping, baseline:

2) PFSense - codel + fq_codel:

3) Linux - sch_cake, noecn + ack-filter:

-
Well, after watching the pfSense video on fq_codel again, it was mentioned that the sub (child) queues under the limiters are required:
https://www.youtube.com/watch?v=o8nL81DzTlU
I'm not sure if they are required to make sure that the shaping works properly when using floating rules on the WAN interface, or just in general. From my personal experience, applying just the limiter on the LAN side (no child queues) work as well. So I'm still on the quest to find a better explanation as to why child queues need to be created.
-
Any chance You can share if You are configuring the bufferbloat testing servers in a special way(sysctl tweaks or something else). The only thing I do over vanilla ubuntu is to set-up iptables and set fq_codel as default qdisc.
I've also sorted my weird results. Turns out there was a bottleneck between me and my netperf server.
-
tail-drop + fq_codel
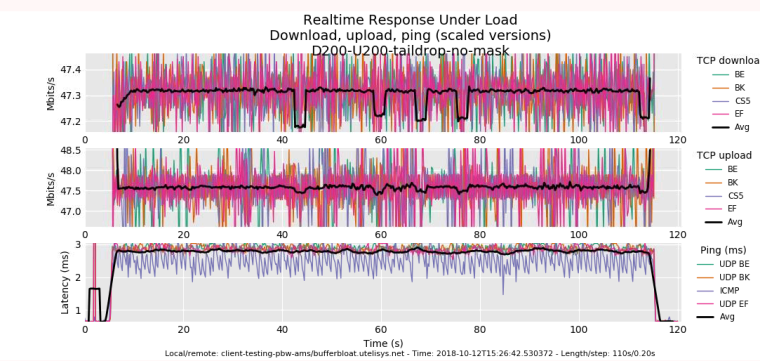
-
pie + fq_pie
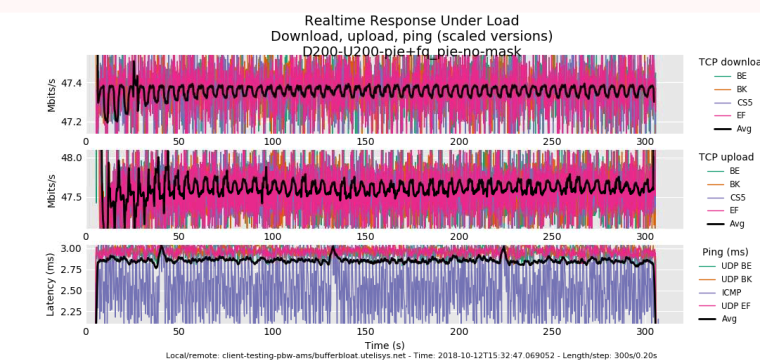
-
-
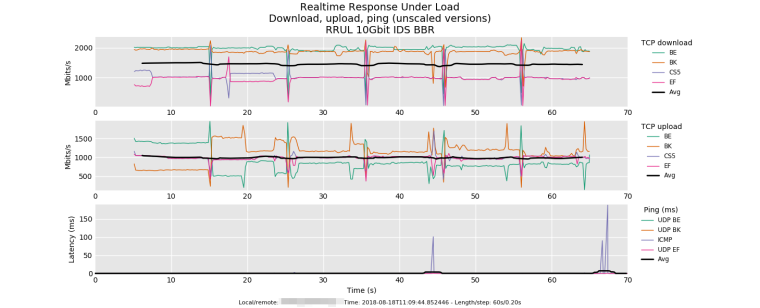
Since people have started sharing flent test results, I figured I'd share a couple interesting one as well from some 10Gbit testing that I have done.
Test 1: RRUL test between two 10Gbit Linux hosts (Debian 9) across the firewall (i.e. two different subnets) with IDS (Snort) enabled. Both hosts have the TCP BBR algorithm enabled. A couple spikes in the ping - at this speed with IDS enabled the firewall's CPU cores are essentially pegged.
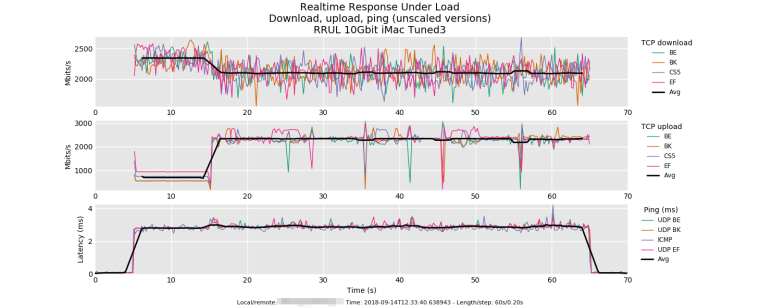
Test 2: RRUL test between a 10Gbit Linux host (Debian 9) and an iMac with 10Gbit Thunderbolt 3 to ethernet adapter. Both on same subnet. Linux host has BBR enabled. Not sure why there is such slow ramp on the iMac side when it is receiving traffic from the Linux host. Unfortunately I have not found a way to fix. Also note how much for stable the upload is on the Linux host with BBR enabled.
Test 3: RRUL test between two 10Gbit Linux hosts (Debian 9) on the same subnet. Both hosts have the TCP BBR algorithm enabled. In my opinion this test is as essentially perfect. Around 19 Gbit/s of traffic and an average latency of less than 1ms . Plus very stable transfer with BBR.
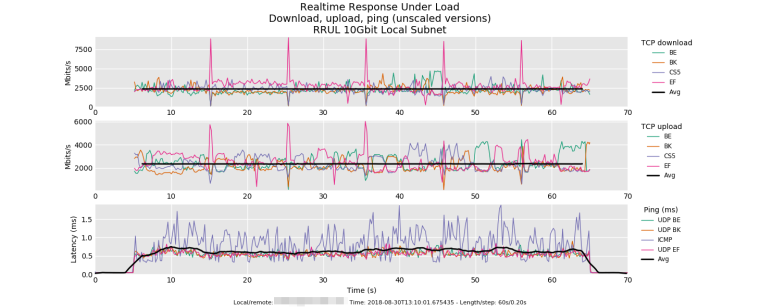
@dtaht - any thoughts?
-
@tman222 I've tested similarly, albeit lower configured pipes, and I actually find that using queues lowers latency.
Here codel+fq_codel is used on pfSense 2.4.4 limiters and flent/netserver hosts are cubic, kernel 4.4.0-137. (q denotes that one up and one down queue was used)
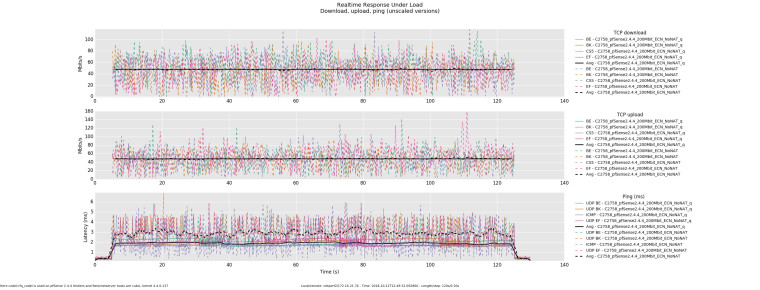
-
Here codel+fq_codel is used on pfSense 2.4.4 limiters and flent/netserver hosts are fq+bbr, kernel 4.15.0-36. (q denotes that one up and one down queue was used)
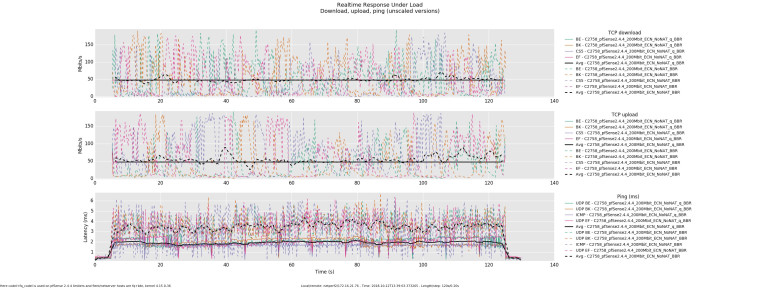
-
And then the opposite occurs as throughput increases, latency becomes higher when utilizing queues.
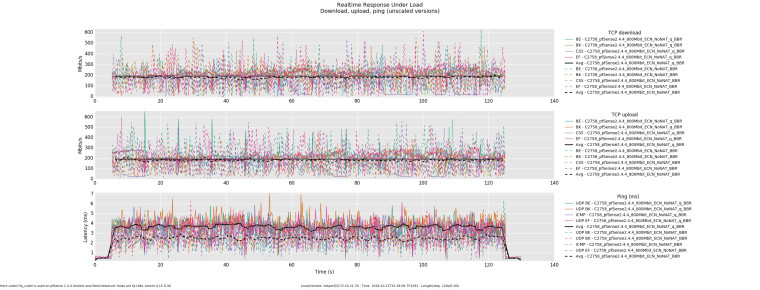
@dtaht any thoughts on what might we be running into here?
-
My first thought, this morning, when asked about my thoughts, was to get some food, a sixpack of beer, and go sailing. :)
Loving seeing y'all doing the comparison plot thing now. you needn't post your *.flent.gz files here if yu don't want to (my browser plugin dumps them into flent automaticall), but feel free to tarball 'em and email dave dot taht at gmail.com.
I don't get what you mean by codel + fq_codel. did you post a setup somewhere?
bb tomorrow. PDT.
-
@tman222 said in Playing with fq_codel in 2.4:
Since people have started sharing flent test results, I figured I'd share a couple interesting one as well from some 10Gbit testing that I have done.
these results were so lovely that I figured the internet didn't need me today.
Test 3) BQL, TSQ, and BBR are amazing. One of my favorite little tweaks is that in aiming for 98.x of the rate it just omits the ip headers from its cost estimate. As for "perfect", one thing you might find ironic, is that the interpacket latency you are getting for this load, is about what you'd get at a physical rate of 100mbits with cubic cake + a 3k bql. Or sch_fq bbr (possibly cubic also) with 3k bql. Thats basically an emulation of the original decchip tulip ethernet card from the good ole days. Loved that card ( https://web.archive.org/web/20000831052812/http://www.rage.net:80/wireless/wireless-howto.html )
If cpu context switch time had improved over the years, well, ~5usec would be "perfect" at 10gige. So, while things are about, oh, 50-100x better than they were 6 years back, it really woud be nice to have cpus that could context switch in 5 clocks.
Still: ship it! we won the internets.
could you rerun this test with cubic instead? (--te=CC=cubic)
sch_fq instead of fq_codel on the client/server? (or fq_codel if you are already using fq)
Test 2) OSX uses reno, with a low IW, and I doubt they've (post your netstat -I thatdevice -qq ?) fq'd that driver.
So (probly?) their transmit queue has filled with acks and there's not a lot of space to fit full size tcp packets. Apple's "innovation" in their stack is stretch acks, so after a while they send less acks per transfer. I think this is tunable on/off but they don't call the option stretch ack. (it may be the delack option you'll find via googling) You can clearly see it kick in with tcptrace though on the relevant xplot.org tsg plot. But 10 sec? wierd. bbr has a 10 sec probe phase... hmmm....Everybody here uses tcptrace -G + xplot.org daily on their packet caps yes?
Test 1) you are pegging it with tcpdump? there's faster alternatives out there. Does the ids need more that 128 bytes?
-
@xciter327 said in Playing with fq_codel in 2.4:
Any chance You can share if You are configuring the bufferbloat testing servers in a special way(sysctl tweaks or something else). The only thing I do over vanilla ubuntu is to set-up iptables and set fq_codel as default qdisc.
I've also sorted my weird results. Turns out there was a bottleneck between me and my netperf server.
-
tail-drop + fq_codel
-
pie + fq_pie
I will share my bufferbloat.net configuration if you gimme these fq_pie vs fq_codel flent files!!! fq_pie shares the same fq algo as fq_codel, but the aqm is different, swiping the rate estimator from codel while retaining a random drop probability like RED. (or pie). So the "wobblyness" of the fq_pie U/D graphs is possibly due to the target 20ms and longer tcp rtt in pie or some other part of the algo... but unless (when posting these) you lock them to the exact same scale (yep, theres a flent option for this) that's hard by eyeball here without locking the graphs. Bandwidth compare via bar chart. Even then, the tcp_nup --socket-stats option (we really need to add that to rrul) makes it easier to look harder at the latency being experienced by tcp.
ecn on on the hosts? ecn on pie is very different.
Pure pie result?

PS
I don't get what anyone means when they say pie + fq_pie or codel + fq_codel. I really don't. I was thinking you were basically doing the FAIRQ -> lots of codel or pie queues method?
-
-
@gsakes said in Playing with fq_codel in 2.4:
Three more tests; all were run with the same up/down b/w parameters, within a few minutes of each other.
1) PFSense - no shaping, baseline:
2) PFSense - codel + fq_codel:

3) Linux - sch_cake, noecn + ack-filter:
your second plot means one of three things:
A) you uploaded the wrong plot
B) you didn't actually manage to reset the config between test runs
C) you did try to reset the config and the reset didn't workI've been kind of hoping for C on several tests here, notably @strangegopher 's last result.
I cannot even begin to describe how many zillion times I've screwed up per B and C. B: I sometimes go weeks without noticing I left an inbound or outbound shaper on or off. In fact, I just did that yesterday - while testing the singapore box and scratching my head. My desktop had a 40mbit inbound shaper on for, I dunno, at least a month. C: even after years of trying it get it right, sqm-scripts does not always succeed in flushing the rules. pfsense?
so, like, trust, but verify! with the ipfw(?) utility.
(flent captures this on linux (see the metadata browser in the gui) , but I didn't even know the command existed on bsd). flent -x captures way more data.
added a feature request to: https://github.com/tohojo/flent/issues/151
-
@dtaht said in Playing with fq_codel in 2.4:
@tman222 said in Playing with fq_codel in 2.4:
Since people have started sharing flent test results, I figured I'd share a couple interesting one as well from some 10Gbit testing that I have done.
these results were so lovely that I figured the internet didn't need me today.
Test 3) BQL, TSQ, and BBR are amazing. One of my favorite little tweaks is that in aiming for 98.x of the rate it just omits the ip headers from its cost estimate. As for "perfect", one thing you might find ironic, is that the interpacket latency you are getting for this load, is about what you'd get at a physical rate of 100mbits with cubic cake + a 3k bql. Or sch_fq bbr (possibly cubic also) with 3k bql. Thats basically an emulation of the original decchip tulip ethernet card from the good ole days. Loved that card ( https://web.archive.org/web/20000831052812/http://www.rage.net:80/wireless/wireless-howto.html )
If cpu context switch time had improved over the years, well, ~5usec would be "perfect" at 10gige. So, while things are about, oh, 50-100x better than they were 6 years back, it really woud be nice to have cpus that could context switch in 5 clocks.
Still: ship it! we won the internets.
could you rerun this test with cubic instead? (--te=CC=cubic)
sch_fq instead of fq_codel on the client/server? (or fq_codel if you are already using fq)
this is one place where you would see a difference in fq with --te=upload_streams=200 on the 10gige test,
but, heh, ever wonder what happens when you hit hit a 5mbit link with more flows than it could rationally handle?What should happen?
What do you want to happen?
What actually happens?
It's a question of deep protocol design and value, with behaviors specified in various rfcs.
-
@dtaht ...uploaded the wrong plot:) thx for pointing it out, I posted the proper plot just now.
-
Hi @dtaht - a couple more fun Flent Charts to add to the mix:
These Flent tests were done through my WAN connection (1Gbit symmetric Fiber) to a Google Cloud VM. The tests were done from East Coast US --> East Coast US. Traffic shaping via fq_codel enabled on pfSense router using default algorithm parameters and 950Mbit up/down limiters.
Test 1: Local host runs Linux (Debian 9) with BBR and enabled and fq qdisc. Remote host also runs Linux (Debian 9), but no changes to default TCP congestion configuration:
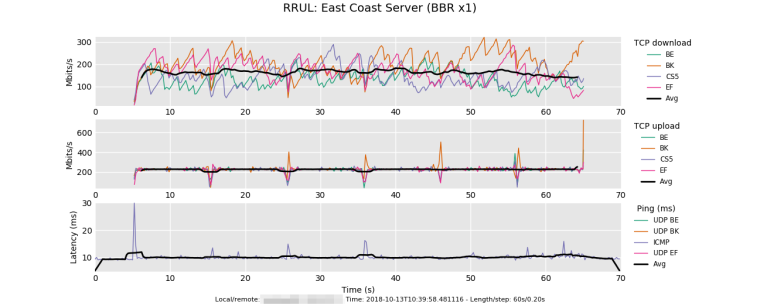
Test 2: Local host runs Linux (Debian 9) with BBR and enabled and fq qdisc. Remote host also runs Linux (Debian 9), and this time also has BBR and fq qdisc enabled just like the local host:
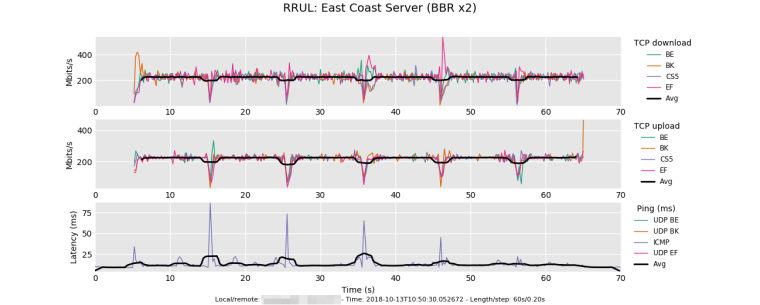
The differences here are substantial: An overall throughput increase (up and down combined) of almost 15% while download alone saw an increase of approximately 36%. BBR is quite impressive!
-
The every 10 sec unified drops in the last test are an artifact of BBR's RTT_PROBE operation, in the real world, people shouldn't be opening 4 connections at the exact same time to the exact same place. (rrul IS a stress test). the rtt_probe thing happens also during natural "pauses" in the conversation, so during crypto setup for https it can happen, as one example, doing dash-style video streaming is another.
The flent squarewave test showing bbr vs cubic behavior is revealing, however, with and without the shaper enabled. It's not all glorious....
tcp_4up_squarewave
To test a bbr download on that test type, use flent's --swap-up-down option (and note you did that in the title)
the 75ms (!!) induced latency spike is bothersome (the other side of the co-joined recovery phase), and it looks to my eye you dropped all the udp traffic on both tests for some reason. ?? Great tcp is one thing, not being able to get dns kind of problematic.
you can get more realistic real-world bbr behavior by switching to the rtt_fair tests and hitting 4 different servers at the same time.