Playing with fq_codel in 2.4
-
This config work perfect! for 1 wan
I have 2 adsl, with balance group (tier 1 both wans).
But dont know how to config the floating rules to use this balance group.
The wans have different speeds.Thanks!
-
I do not speak English, but google speaks for me KKK, create 2 floating rules one for each gateway this way :
-
@ricardox Thanks, I'm going to try it
This is what I have
WAN1 and WAN2Create 8 floating rules (following the example of @uptownVagrant )
but I think that is not the correct way to achieve the desired goal1.)
Action: Pass
Quick: Tick Apply the action immediately on match.
Interface: WAN1
Direction: out
Address Family: IPv4
Protocol: ICMP
ICMP subtypes: Traceroute
Source: any
Destination: anyAction: Pass
Quick: Tick Apply the action immediately on match.
Interface: WAN2
Direction: out
Address Family: IPv4
Protocol: ICMP
ICMP subtypes: Traceroute
Source: any
Destination: any3.)
Action: Pass
Quick: Tick Apply the action immediately on match.
Interface: WAN1
Direction: any
Address Family: IPv4
Protocol: ICMP
ICMP subtypes: Echo reply, Echo Request
Source: any
Destination: any
Description: limiter drop echo-reply under load workaround4.)
Action: Pass
Quick: Tick Apply the action immediately on match.
Interface: WAN2
Direction: any
Address Family: IPv4
Protocol: ICMP
ICMP subtypes: Echo reply, Echo Request
Source: any
Destination: any
Description: limiter drop echo-reply under load workaround5.)
Action: Match
Interface: WAN1
Direction: in
Address Family: IPv4
Protocol: Any
Source: any
Destination: any
Gateway: WAN1
In / Out pipe: fq_codel_WAN1_in_q / fq_codel_WAN1_out_q6.)
Action: Match
Interface: WAN2
Direction: in
Address Family: IPv4
Protocol: Any
Source: any
Destination: any
Gateway: WAN2
In / Out pipe: fq_codel_WAN2_in_q / fq_codel_WAN2_out_q7.)
Action: Match
Interface: WAN1
Direction: out
Address Family: IPv4
Protocol: Any
Source: any
Destination: any
Gateway: WAN1
In / Out pipe: fq_codel_WAN1_out_q / fq_codel_WAN1_in_q8.)
Action: Match
Interface: WAN2
Direction: out
Address Family: IPv4
Protocol: Any
Source: any
Destination: any
Gateway: WAN2
In / Out pipe: fq_codel_WAN2_out_q / fq_codel_WAN2_in_q -
@mr-cairo
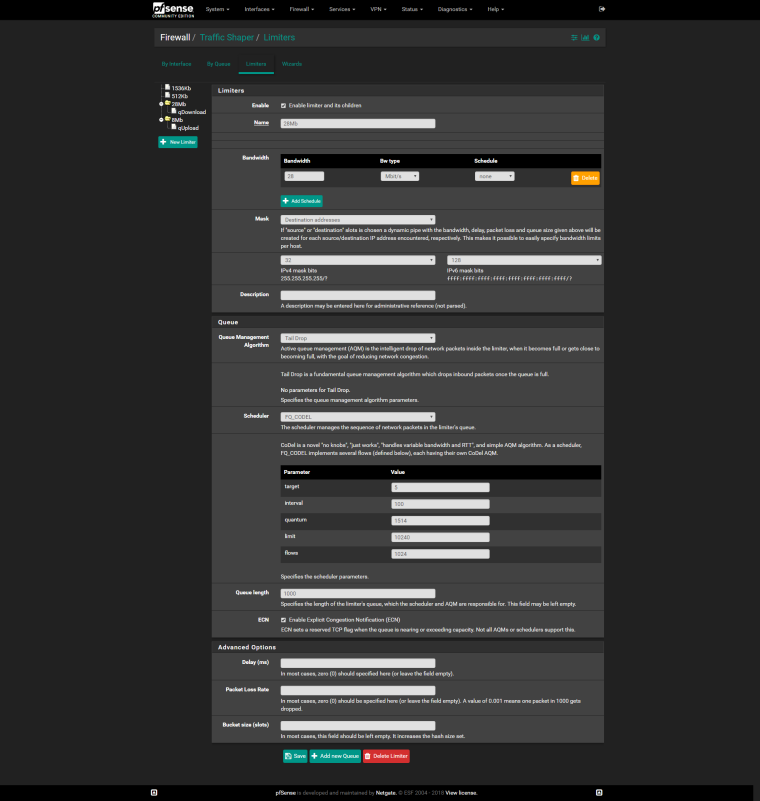
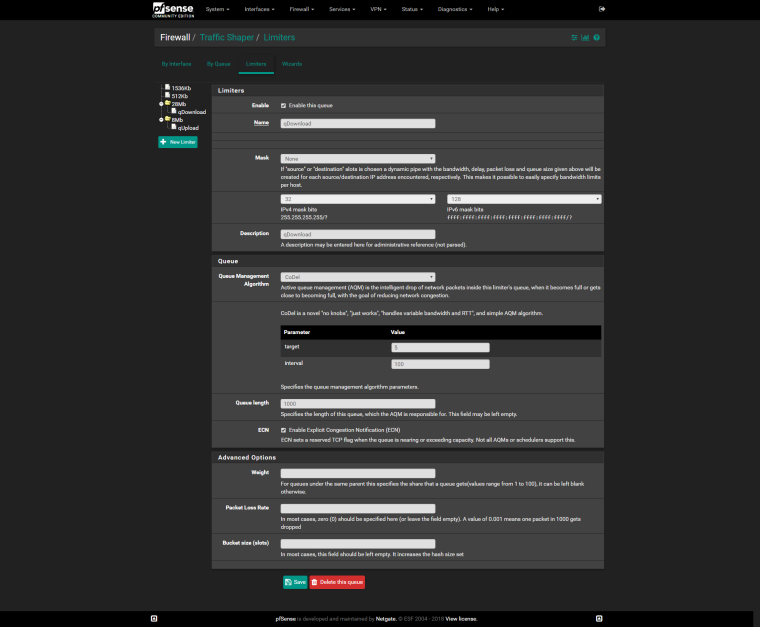
Do the same for Upload
-
So an update from myself.
Still trying to perfect the interactive packets been dropped issue, I noticed pie is now implemented on the AQM.
So what I have done for now to test on my own network is changed droptail to pie for the pipe and queue, scheduler is still using fq_codel.
Also in regards to the dynamic flow sets, it seems something isnt quite right, as the OP pointed out, there is just one single flow created and always shows src and target ip as 0.0.0.0 so regardless of what mask is configured there will always only be one flow and I suspect if multiple flows can be made to work results will be better. The reason been if you have say two flows, one is a full speed saturated download over fast ftp and the other is from an interactive ssh session, the latter will never fill its flow queue and wont drop packets, while the first would fill and drop packets, as it is now both tcp streams share the same flow, so how does the shaper know which packets to drop? the only help on that seems to come from the quantum value which prevents smaller packets from been put at the end of the queue.
--update--
Ok I have managed to get the multiple flows working. Was a lot of experimentation but I got there after finally understanding what the man page for ipfw/dummynet is explaining. If you get it wrong dummynet stops passing traffic ;) but I am only testing on my home network so is fine.
--update2--
I chose to have a flow per internet ip rather than per lan device. Also this is only for ipv4 right now, I think if you configure it so it overloads the flow limit then it breaks, and obviously the ipv6 address space is way bigger.
root@PFSENSE home # ipfw sched show 00001: 69.246 Mbit/s 0 ms burst 0 q00001 500 sl. 0 flows (256 buckets) sched 1 weight 0 lmax 0 pri 0 droptail mask: 0x00 0x000000ff/0x0000 -> 0x00000000/0x0000 sched 1 type FQ_CODEL flags 0x1 256 buckets 4 active FQ_CODEL target 5ms interval 30ms quantum 300 limit 1000 flows 1024 ECN mask: 0x00 0xffffff00/0x0000 -> 0x00000000/0x0000 Children flowsets: 1 BKT ___Prot___ _flow-id_ ______________Source IPv6/port_______________ _______________Dest. IPv6/port_______________ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0 ::/0 ::/0 6 288 0 0 0 17 ip 46.17.x.x/0 0.0.0.0/0 4 176 0 0 0 123 ip 208.123.x.x/0 0.0.0.0/0 5 698 0 0 0 249 ip 80.249.x.x/0 0.0.0.0/0 6 168 0 0 0 00002: 18.779 Mbit/s 0 ms burst 0 q00002 500 sl. 0 flows (256 buckets) sched 2 weight 0 lmax 0 pri 0 droptail mask: 0x00 0xffffffff/0x0000 -> 0x00000000/0x0000 sched 2 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 300ms quantum 300 limit 800 flows 1024 NoECN Children flowsets: 2--update 3--
Initial tests this is working sweet, on the below paste you can clearly see the bulk download flow and notice it only drops packets from that flow. I also tested on steam and zero dropped packets now on flows outside of steam, wow.
BKT ___Prot___ _flow-id_ ______________Source IPv6/port_______________ _______________Dest. IPv6/port_______________ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0 ::/0 ::/0 7 348 0 0 0 17 ip 46.17.x.x/0 0.0.0.0/0 3 132 0 0 0 58 ip 216.58.x.x/0 0.0.0.0/0 1 52 0 0 0 123 ip 208.123.x.x/0 0.0.0.0/0 5 698 0 0 0 135 ip 5.135.x.x/0 0.0.0.0/0 11919 17878500 3 4500 2 249 ip 80.249.x.x/0 0.0.0.0/0 6 168 0 0 0 254 ip 162.254.x.x/0 0.0.0.0/0 1 40 0 0 0 -
@chrcoluk said in Playing with fq_codel in 2.4:
So an update from myself.
Still trying to perfect the interactive packets been dropped issue, I noticed pie is now implemented on the AQM.
What interactive packets being dropped issue? Can you be specific? How are you measuring drops?
So what I have done for now to test on my own network is changed droptail to pie for the pipe and queue, scheduler is still using fq_codel.
When FQ-CoDel is used as the scheduler, the AQM you choose is not utilized. (fq_codel has separate enqueue/dequeue functions - AQM is ignored) https://forum.netgate.com/post/804118
Also in regards to the dynamic flow sets, it seems something isnt quite right, as the OP pointed out, there is just one single flow created and always shows src and target ip as 0.0.0.0 so regardless of what mask is configured there will always only be one flow and I suspect if multiple flows can be made to work results will be better. The reason been if you have say two flows, one is a full speed saturated download over fast ftp and the other is from an interactive ssh session, the latter will never fill its flow queue and wont drop packets, while the first would fill and drop packets, as it is now both tcp streams share the same flow, so how does the shaper know which packets to drop? the only help on that seems to come from the quantum value which prevents smaller packets from been put at the end of the queue.
What you are seeing using 'ipfw sched show' is not exposing the dynamic internal flows and sub-queues that FQ-CoDel is managing. It seems you are trying to create a visual representation, via 'ipfw sched show', of the mechanism that is already in place and operating within FQ-CoDel. See this post https://forum.netgate.com/post/803139
-
I am not convinced there is anything more than 1 flow on the existing configuration, especially after reading this and taking it all in, be warned its a big lot of text.
https://www.freebsd.org/cgi/man.cgi?query=ipfw&sektion=8&apropos=0&manpath=FreeBSD+11.2-RELEASE+and+Ports
But you can skip to the dummynet section.
I am measuring drops in two ways.
By looking at the output from the command I pasted on here, (I assumed that was obvious), and also holding a key down in a ssh terminal session whilst downloading bulk data to see if there is visible packet loss. Packet loss is very visible in a ssh terminal session as the cursor will stick and jump.
With a single flow fq_codel is fine at reducing jitter and latency, and that is all 95% seems to care about on here, just to get their dslreports grade scores up. However I did observe it was not able to differentiate between different tcp streams and as such not intelligently drop packets, the droptail AQM e.g. just blocks new packets entering the queue when its full, regardless of what those packets are.
Note that for flow separation the dummynet configuration states a mask needs to be set in the queue as well as the scheduler.
When running ipfw sched show, there is 2 indications of flows.
One is the number of buckets which stays as 1 on the older configuration, the other is on ipfw queue show and and the number of flows on that which stays at 0.
I managed to figure out the syntax for ipv6 flow separation as well based on how its configured for ipv4.
Now I am not saying you are wrong in that there is invisible flows not presented by the status commands, I am just saying I am seeing no evidence of that, based on performance metrics and the tools provided that show the active status of dummynet.
If you want to see the changes I made they are as following, these commands will generate a flow for each remote ipv4 address on downloads.
ipfw sched 1 config pipe 1 queue 500 mask src-ip 0xffffff00 type fq_codel ecn target 5 interval 30 quantum 300 limit 1000
ipfw queue 1 config sched 1 queue 500 mask src-ip 0x000000ffYou dont have to do this and it is more complex, if all you care about is bufferbloat then the existing single flow configuration is fine. As that's what it does it reduces bufferbloat. But if you want flow seperation, then the dummynet man page seems to clearly state that masks have to be set in scheduler and queue.
It is important to understand the role of the SCHED_MASK and FLOW_MASK, which are configured through the commands ipfw sched N config mask SCHED_MASK ... and ipfw queue X config mask FLOW_MASK .... The SCHED_MASK is used to assign flows to one or more scheduler instances, one for each value of the packet's 5-tuple after applying SCHED_MASK. As an example, using ``src-ip 0xffffff00'' creates one instance for each /24 destination subnet. The FLOW_MASK, together with the SCHED_MASK, is used to split packets into flows. As an example, using ``src-ip 0x000000ff'' together with the previous SCHED_MASK makes a flow for each individual source address. In turn, flows for each /24 subnet will be sent to the same scheduler instance.Sorry about the colour changes the source text isnt like that. There is mention of schedule instances which may be what you are reffering to, but these dont seem to provide intelligent dropping of packets whilst flow separation does.
-
Thanks for the info regarding AQM.
I did more testing, and I also get good results by just setting a mask on the queue only, leaving sched as default so just the single flow but reversing the mask.
So basically previously the original config was mask set so dst-ip on ingress and src-ip on egress, meaning the flows are per device on the LAN. I never wanted this, but I suppose good if you run an isp.
I then created this new config which creates seperate flows on the scheduler which is visible on the diagnostics, but forgot I also reversed the masking, this fixed my packet loss.
I then went back to the queue only mask, but also with the reversed mask so src-ip instead of dst-ip for ingress, and this was good as well.I wont bother testing alternative AQM's it was only briefly tried, and all thee testing with separate flows was done back on droptail, I will just accept what both of you say on that. So for me it simply seems all I had to do was reverse the masking so I have dynamic queues per remote host instead of per local host.
pfSense CE 2.8.1
-
@chrcoluk Thank you for posting all of the details of your test method and config - much appreciated.
I'm on the US west coast so I'll dig into this later today, just after 0100 currently, to see if I can recreate your findings. That being said, I'm pinging @Rasool on this as my understanding is that your configuration should not be needed for flow separation as RFC 8290 states that FQ-CoDel is doing its own 5-tuple to identify flows.
-
@chrcoluk I am not able to recreate your findings based on the information you gave.
I tested using two Flent clients running overlapping RRUL tests while I used a separate client to initiate an SSH session to a separate destination and held down a key and watched for any sticking or jumping of the cursor. I did not experience any sticking or jumping. The RRUL tests ran for 130 seconds each, overlapping, and easily saturated the limiters during the test. I set the limiters to more closely match what you had set for bandwidth.
A couple of things i noticed about your config.
- You are using intervals, quantums, and limits that are not the default. If you set these to the defaults for each pipe does that change the behavior of SSH session while the limiters are under load?
- If you half your IN and OUT limiter bandwidth values, while using the default FQ-CoDel scheduler values, does this change the behavior of the SSH session while the limiters are under load?
Here is what my pipes, schedulers, and queues look like. I'm using the configuration I posted here https://forum.netgate.com/post/807490:
Limiters: 00001: 18.000 Mbit/s 0 ms burst 0 q131073 50 sl. 0 flows (1 buckets) sched 65537 weight 0 lmax 0 pri 0 droptail sched 65537 type FIFO flags 0x0 0 buckets 0 active 00002: 69.000 Mbit/s 0 ms burst 0 q131074 50 sl. 0 flows (1 buckets) sched 65538 weight 0 lmax 0 pri 0 droptail sched 65538 type FIFO flags 0x0 0 buckets 0 active Schedulers: 00001: 18.000 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 1 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 NoECN Children flowsets: 1 00002: 69.000 Mbit/s 0 ms burst 0 q65538 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail sched 2 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 100ms quantum 1514 limit 10240 flows 1024 NoECN Children flowsets: 2 Queues: q00001 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail q00002 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail -
@uptownvagrant said in Playing with fq_codel in 2.4:
That being said, I'm pinging @Rasool on this as my understanding is that your configuration should not be needed for flow separation as RFC 8290 states that FQ-CoDel is doing its own 5-tuple to identify flows.
You are right. FQ-CoDel internally identifies flows and hashes them to internal sub-queues. External flow separation and hashing are not required in simple configurations.
-
If I reduce my download pipe e.g. to say half yes there is no packet loss regardless as the line has way more unused buffer then. Well actually sorry there was still packetloss, but on the half speed they tended to be early on only in the test.
The commands I posted are not what I am actually using, I am a bit looser to default than what was posted, but quantum 300 is used as is recommended to improve performance of smaller packets and it does indeed help my ssh packets (worse on default), I am now back on the default 50 pipe depth.
Interval was manually tuned by me to suit my network conditions. Although I feel that one to have no measurable affect either good or bad.
I have no experience of RRUL so I dont know if that would have affected me, its not just any download that would cause dropped packets, usually just things like steam which absolutely flood the ingress pipe with tons of packets.
But it doesnt matter for me now as by making the dynamic queues one per remote ip, it seems to be pretty much all resolved for me now. It wasnt a major issue I had already had it working pretty well, but this change has perfected it.
But before you ask I have obviously used all default values, I would have done the very first time I used fq_codel and dummynet, I always start of by keeping things as simple as possible, and only stray from that if I feel a need to.
Bear in mind the vast majority of my home lan is just my desktop pc, all other network devices are almost always idle aside from my STB,and if I am watching streams on the STB then I am not on my PC and interactivity doesnt matter on my PC then, so really the masks that I was using before that separated per lan device was pointless for me, but the other way round its really useful.
00001: 69.246 Mbit/s 0 ms burst 0 q00001 50 sl. 0 flows (256 buckets) sched 1 weight 0 lmax 0 pri 0 droptail mask: 0x00 0xffffffff/0x0000 -> 0x00000000/0x0000 sched 1 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 30ms quantum 300 limit 1000 flows 1024 ECN Children flowsets: 1 BKT Prot ___Source IP/port____ ____Dest. IP/port____ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0.0.0.0/0 0.0.0.0/0 1 60 0 0 0 00002: 18.779 Mbit/s 0 ms burst 0 q00002 50 sl. 0 flows (256 buckets) sched 2 weight 0 lmax 0 pri 0 droptail mask: 0x00 0x00000000/0x0000 -> 0xffffffff/0x0000 sched 2 type FQ_CODEL flags 0x0 0 buckets 0 active FQ_CODEL target 5ms interval 300ms quantum 300 limit 800 flows 1024 NoECN Children flowsets: 2 q00001 50 sl. 0 flows (256 buckets) sched 1 weight 0 lmax 0 pri 0 droptail mask: 0x00 0xffffffff/0x0000 -> 0x00000000/0x0000 q00002 50 sl. 0 flows (256 buckets) sched 2 weight 0 lmax 0 pri 0 droptail mask: 0x00 0x00000000/0x0000 -> 0xffffffff/0x0000 00001: 69.246 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 65537 type FIFO flags 0x0 0 buckets 0 active 00002: 18.779 Mbit/s 0 ms burst 0 q131074 50 sl. 0 flows (1 buckets) sched 65538 weight 0 lmax 0 pri 0 droptail sched 65538 type FIFO flags 0x0 0 buckets 0 active -
@chrcoluk said in Playing with fq_codel in 2.4:
If I reduce my download pipe e.g. to say half yes there is no packet loss regardless as the line has way more unused buffer then. Well actually sorry there was still packetloss, but on the half speed they tended to be early on only in the test.
The idea behind this question was have you set your bandwidth too close to where your ISP is dropping packets? I was assuming, based on your bandwidth settings, that you were testing over the Internet and your ISP, as well as other outside factors, are in the mix. What does your bufferbloat look like when you half the bandwidth? There is going to be some packet loss, that's actually the point, but my experience so far is that FQ-CoDel is doing a pretty great job at prioritizing interactive flows and I haven't been able to recreate the poor handling of these flows that a couple folks have mentioned.
The commands I posted are not what I am actually using, I am a bit looser to default than what was posted, but quantum 300 is used as is recommended to improve performance of smaller packets and it does indeed help my ssh packets (worse on default), I am now back on the default 50 pipe depth.
Setting the pipe or queue 'queue length' is ignored when you are using FQ-CoDel. CoDel is handling the queue length dynamically.
Interval was manually tuned by me to suit my network conditions. Although I feel that one to have no measurable affect either good or bad.
I have no experience of RRUL so I dont know if that would have affected me, its not just any download that would cause dropped packets, usually just things like steam which absolutely flood the ingress pipe with tons of packets.
I don't personally use Steam but I have it on my network. I'm assuming you are referring to game downloads when you mention "absolutely flood the ingress pipe with tons of packets"?
But it doesnt matter for me now as by making the dynamic queues one per remote ip, it seems to be pretty much all resolved for me now. It wasnt a major issue I had already had it working pretty well, but this change has perfected it.
Glad it's working perfectly for you now, I was hoping that we could identify the root cause.
-
yes I mean steam downloads, typically there is at least 24 tcp streams opened but often over 30 if its a large game. If you have a local download server configured then thats 24+ tcp streams with low rtt flooding the network. Steam has no persistent way of reducing the number of connections, you can reduce it via a command in the console but it is not saved, so when you restart steam it goes back to default.
If you set a server on the other side of the world so rtt is way higher, it is another way to mitigate the problem as higher rtt makes the packets much more passive on the network. So e.g. if from asia to the uk I can still hit full speed downloads simply due to the really high number of threads, 32 threads is way overkill on a 10ms latency server.
What I am considering doing is changing the mask to a /24 instead of /32 for remote as often the steam ip's come from the same /24, which will make them fight with each other in one dynamic queue, but still separate them from other dynamic queue, that will be even more effective than what I have now.
Interesting that fq_codel also seems to make a lot of tunables useless, this really needs to be documented somewhere because its not documented on the dummynet or pfsense pages. But I did never notice a difference between 1000 slots and 50 slots anyway which is why it was reduced back to the default 50 slots, that explains why no difference was observed.
What I just want to say here is sometimes on the internet people dont like it when people go away from defaults, you 2 guys have been fine, as you have been very polite about it, but sometimes I have come across people who even get angry :), but there is a reason things can be tuned is that you cannot set something as a default that works in 100% of situations optimally. Its impossible. Even auto tuning algorithms can not be 100%.
But to me steam is the ultimate test, I have yet to come across any speedtester or other automated testing tool that abuses the network as much as steam, steam basically ddos's your network as far as I am concerned, its abusive to use so many threads. Because the only way I have found to stress a network harder is to ddos it.
I m happy to try and put your mind's at rest to test quantum 1514 whils tusing these masks, quantum 300 was suggested by someone earlier in this thread and is also suggested by a fq_codel expert somewhere on the net, it supposedly makes queues with packets smaller than the quantum size have higher priority than queues with packets larger than the quantum size so less likely to get packets dropped when the pipe is full.
I am lucky my isp has no visible congestion so I can hit my line rate 24/7/365. Which makes configuring a pipe size easier. I did take into account overheads for dsl etc. so the rate configured for the pipe is lower than actual achievable tcp speeds "after" overheads. The only thing I have to watch out for of course is if my dsl sync speed changes so it syncs lower, but thankfully this has been stable for a long time now.
-
@chrcoluk said in Playing with fq_codel in 2.4:
yes I mean steam downloads, typically there is at least 24 tcp streams opened but often over 30 if its a large game. If you have a local download server configured then thats 24+ tcp streams with low rtt flooding the network. Steam has no persistent way of reducing the number of connections, you can reduce it via a command in the console but it is not saved, so when you restart steam it goes back to default.
If you set a server on the other side of the world so rtt is way higher, it is another way to mitigate the problem as higher rtt makes the packets much more passive on the network. So e.g. if from asia to the uk I can still hit full speed downloads simply due to the really high number of threads, 32 threads is way overkill on a 10ms latency server.
Thanks for detailing what you're seeing with regard to Steam game downloads. I'll see if I can recreate your experience on one of my networks.
Interesting that fq_codel also seems to make a lot of tunables useless, this really needs to be documented somewhere because its not documented on the dummynet or pfsense pages. But I did never notice a difference between 1000 slots and 50 slots anyway which is why it was reduced back to the default 50 slots, that explains why no difference was observed.
This is why I brought it up because it's not well documented.
What I just want to say here is sometimes on the internet people dont like it when people go away from defaults, you 2 guys have been fine, as you have been very polite about it, but sometimes I have come across people who even get angry :), but there is a reason things can be tuned is that you cannot set something as a default that works in 100% of situations optimally. Its impossible. Even auto tuning algorithms can not be 100%.
But to me steam is the ultimate test, I have yet to come across any speedtester or other automated testing tool that abuses the network as much as steam, steam basically ddos's your network as far as I am concerned, its abusive to use so many threads. Because the only way I have found to stress a network harder is to ddos it.
I m happy to try and put your mind's at rest to test quantum 1514 whils tusing these masks, quantum 300 was suggested by someone earlier in this thread and is also suggested by a fq_codel expert somewhere on the net, it supposedly makes queues with packets smaller than the quantum size have higher priority than queues with packets larger than the quantum size so less likely to get packets dropped when the pipe is full.
A quantum of 300 seems perfectly sane for your use case and test scenario. If you look at the sqm-scripts for OpenWRT, which was provided by CeroWrt’s SQM with optional packages @bufferbloat.net, you will see a FQ-CoDel quantum of 300 and 1514 depending on if PRIO is being used on children - the simplest scripts are using the default quantum of 1514. My observation was that you were not using defaults and my experience has been that sometimes folks don't really understand all of the nerd knobs, I know I've been guilty of this, and they start making changes based on collecting out of context bits of information on the Internet. In short, we sometimes act against our own interest in the pursuit of "tuning" - not saying that you are, just wanted to see if defaults had any positive impact. For instance, setting "limit" to anything under the default only seems beneficial on systems severely memory constrained - the hard limit should be rarely, if ever, hit as drops are performed by CoDel long before "limit" would be hit. (RFC 8290, section 5.2.3) You run the risk of setting limit too low and experiencing drops, "fq_codel_enqueue over limit", before they should based on your target. A limit of 1001 should be OK but leaving it at the default 10240 on your system may drop less without any adverse effects seeing as your system has 4GB of RAM.
-
I want my ISP to replace my puma modem with broadcom modem but they refuse to replace it until I show them that my modem is bad. As you have seen my modem still has high latency in flent tests despite fq_codel. Is there anything more I can do to show the tech that the modem is cause if this issue?
-
@uptownvagrant The limit value has now also been reset to the default of 10240, the only tuned value in my rules now is basically quantum and the masks been reversed. Thanks for your help.
Also I do agree that tuning can most definitely make things worse, the enqueue stuff that appears in logs is caused by the limit value been set too low, which is probably why it has a high default. The bufferbloat website suggests reducing it when speed is below 100mbit, but I tested their recommendation and it generated lots of enqueue over limit warnings, which as muppet pointed if too many of them appear it can bring down the OS.
-
I was able to test Steam distributed downloads using your config minus the masks. I was not able to recreate your findings and I'm still wondering if the interactive flow drops, SSH session, were due to something upsteam from you or there was a very low probability hash collision. If it was consistent then a hash collision is highly improbable.
Notes:
- My testing with Flent and netperf actually pushes more pps and more flows then what I saw with Steam.
- The bandwidths configured to your values are a very small percentage of what my lab upstream up/down limits are so those were not a factor in my testing.
- ICMP and HTTPS webUI traffic was not passing through the limiter. All other traffic was set to be placed in the limiter queues.
Limiters: 00001: 18.779 Mbit/s 0 ms burst 0 q131073 50 sl. 0 flows (1 buckets) sched 65537 weight 0 lmax 0 pri 0 droptail sched 65537 type FIFO flags 0x0 0 buckets 0 active 00002: 69.246 Mbit/s 0 ms burst 0 q131074 50 sl. 0 flows (1 buckets) sched 65538 weight 0 lmax 0 pri 0 droptail sched 65538 type FIFO flags 0x0 0 buckets 0 active Schedulers: 00001: 18.779 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 1 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 1 BKT Prot ___Source IP/port____ ____Dest. IP/port____ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0.0.0.0/0 0.0.0.0/0 193 9082 0 0 0 00002: 69.246 Mbit/s 0 ms burst 0 q65538 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail sched 2 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 300 limit 10240 flows 1024 NoECN Children flowsets: 2 0 ip 0.0.0.0/0 0.0.0.0/0 51106 76002641 29 43500 1209 Queues: q00001 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail q00002 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail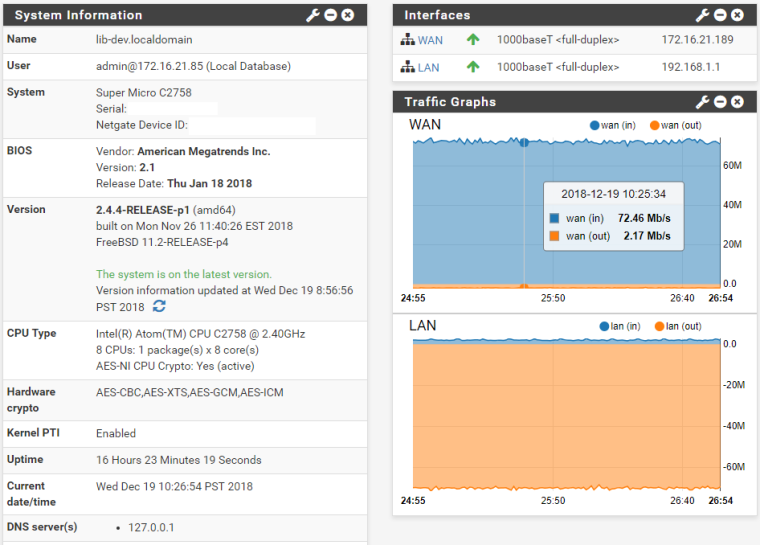
The RTT for almost all of these Steam servers was under 8 ms.
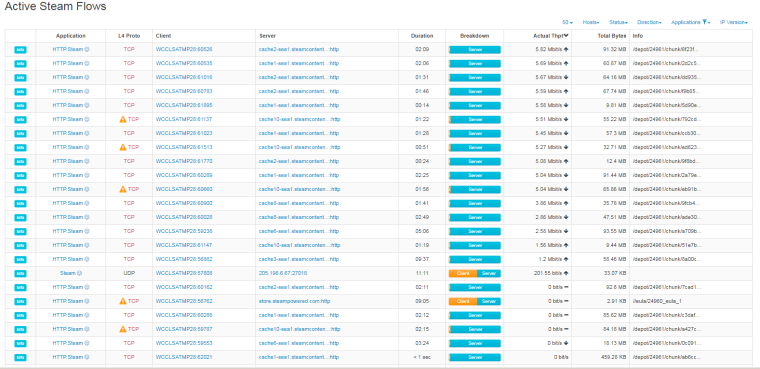
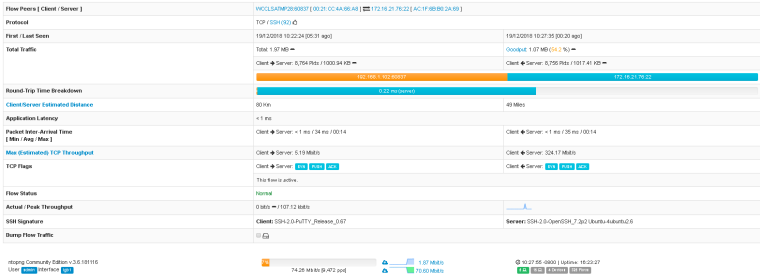
There were no drops associated with the SSH session I had from inside the LAN to outside the WAN.
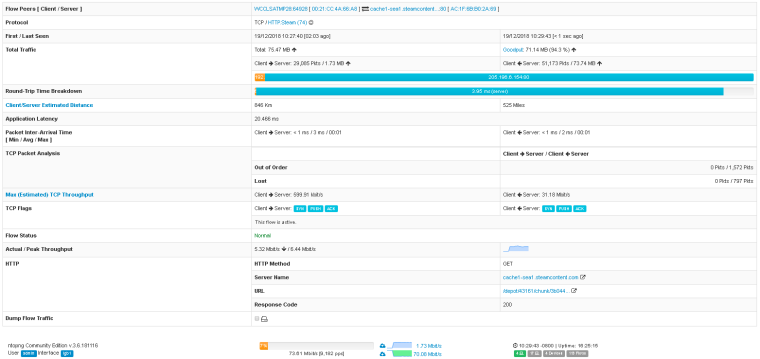
Here is a Steam download flow where you see many drops associated.
-
I wouldnt worry over it too much.
There is too many variables here, Operating System, Hardware used, RTT to download servers, capacity of connection, congestion provider used and so on.
I originally had really bad issues which I detailed earlier in the thread, when I changed the hardware in my pfsense unit it was improved, then it became minor issues only on a few scenarios with steam been one of them, changing the masks so steam downloads have their own dynamic queue made it perfect for me, but because you cannot get the same issue yourself it doesnt mean is a problem, its fine everyone is happy with what they have here. :)
I have also slightly decreased my pipe size a bit further so I can get perfect results on 32 threaded dslreports test as well. It seems it was slightly too high for that.
pfSense CE 2.8.1
-
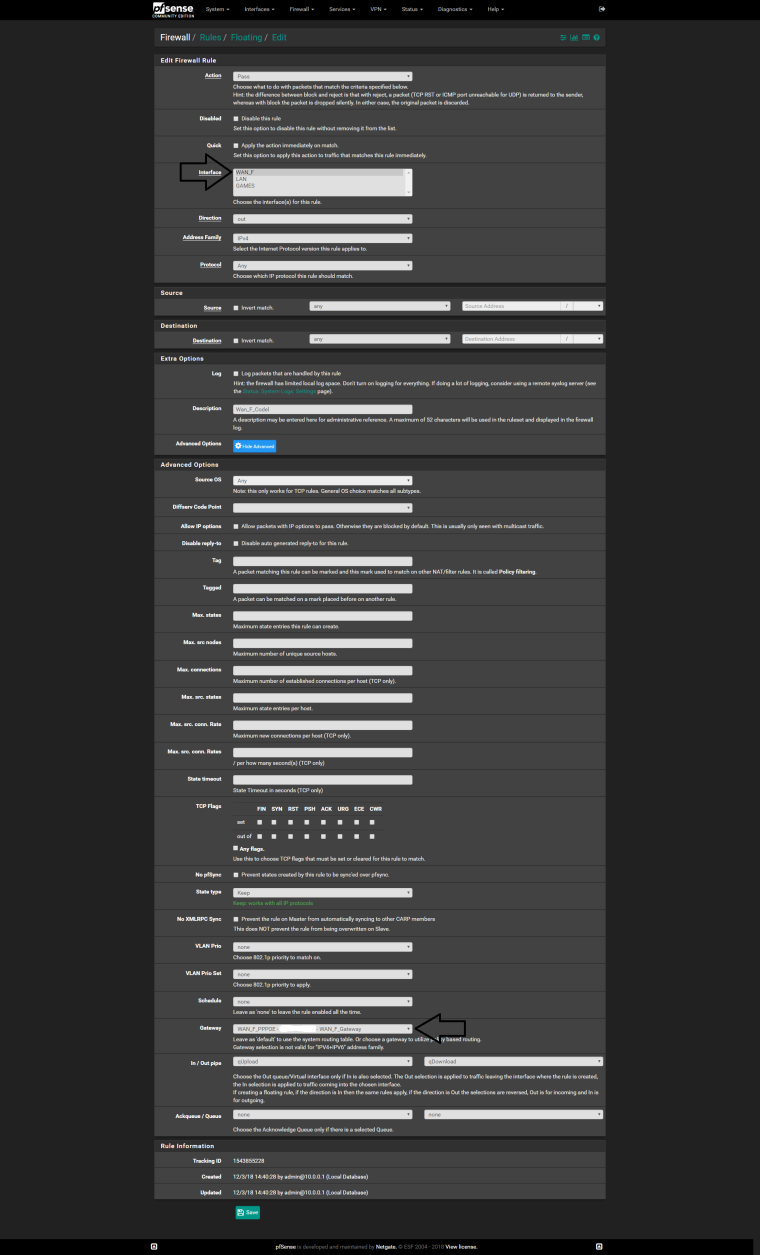
@uptownVagrant may I know what is this rule for? I tried to enable this rule only, but it only bypass the limiters. What's the difference between this rule #3 and rule #4
3.) Add a match rule for incoming state flows so that they're placed into the FQ-CoDel in/out queues
- Action: Match
- Interface: WAN
- Direction: in
- Address Family: IPv4
- Protocol: Any
- Source: any
- Destination: any
- Description: WAN-In FQ-CoDel queue
- Gateway: Default
- In / Out pipe: fq_codel_in_q / fq_codel_out_q
- Click Save