CPU Usage when network used
-
@qwaven said in CPU Usage when network used:
So now the question is how can I use PFSense (PF) without causing it to throttle my connections?
Best solution with the most performance, use a Layer 3 capable switch for internal routing and pfSense only for internet access. Or look at TNSR instead of pfSense.
Also read here: https://forum.netgate.com/topic/136352/performance-tuning-for-10gb-connection/9
-
Mmm, might not be much we can do there.
You have 8 queues for each ix NIC. I wonder if some core affinity tweak might help. It could be using the same 8 cores for both NICs in that test for example.
Though I suspect the pf process itself is not loading the cores even close to evenly. You have cpu 8 at 2.6% idle and cpu 9 is not even on the list so 0%. All the others are at least 50% idle.
Steve
-
My switch is technically able to do routing and I suppose I could try this route if it comes to it.
I did read a few tuning things and tried some settings but nothing as of yet has really changed anything performance wise. I'm not seeing any indication that buffers are full...etc.
What I am mostly puzzled with is "limitation with PF" vs the performance of my hardware. When I see that most of my cores...etc are barley working when transferring data it would appear that my PFSense is not working as hard as it theoretically could be.
So if its possible to ensure PF balances more evenly across all 16 cores or something I'm open to exploring this. I tried setting the nic queues from 8 to 16 to see if that would do anything but I did not improve anything. Not really sure what is meant by 'core affinity tweak'.
Cheers!
-
I know this thread has mostly been resolved, but I thought I would add a few thoughts:
I have also used Chelsio T520-SO-CR card with pfSense (and more recently its bigger brother, the T540-SO-CR), and the cards have always worked out great. However, I would recommend tuning them slightly -- i.e. increasing the TX/RX descriptors (the defaults are pretty low) and turning off flow control / pause settings (unless you need that enabled on your network).
Regarding the performance you are seeing: The test you did that was through pfSense (i.e. the post with the screenshots above), was that running iperf3 with multiple streams, or just one? To provide some comparison, my pfSense box is driven by a Xeon D-1518 CPU (2.2GHz, quad core). When running a iperf3 test through pfSense between two (bare metal) Linux hosts on different subnets, I can average between 3.75 - 4.0 Gbit/s with a single stream (and that's with Snort enabled on both subnets as well). If I keep increasing the number of parallel streams, I'll eventually be able to saturate the the connection just north of 9.4 Gbits/s.
However, ultimately what matters performance wise is not so much bandwidth, but the number of packets that pfSense can process per second. Here is some more information on that, including some extensive testing I did last year:
https://forum.netgate.com/topic/132394/10gbit-performance-testing/
Hope this helps.
-
Mmm, definitely worth trying that.
-
Hi all,
Thanks for the info.
So I've tried running more streams at once both with -P option as well as like this page suggests.
https://fasterdata.es.net/performance-testing/network-troubleshooting-tools/iperf/multi-stream-iperf3/
Transfers appear to average out between the 3 connections to be about 3G.
Top looks like this which I believe is about the same also.last pid: 31030; load averages: 1.32, 0.40, 0.17 up 0+23:57:53 21:15:20
370 processes: 18 running, 244 sleeping, 108 waiting
CPU: 0.0% user, 0.0% nice, 0.8% system, 13.2% interrupt, 86.0% idle
Mem: 28M Active, 254M Inact, 450M Wired, 41M Buf, 15G Free
Swap: 3979M Total, 3979M FreePID USERNAME PRI NICE SIZE RES STATE C TIME WCPU COMMAND
11 root 155 ki31 0K 256K CPU8 8 23.9H 99.79% [idle{idle: cp
11 root 155 ki31 0K 256K CPU1 1 23.9H 99.70% [idle{idle: cp
11 root 155 ki31 0K 256K CPU14 14 23.9H 97.54% [idle{idle: cp
11 root 155 ki31 0K 256K CPU9 9 23.9H 97.40% [idle{idle: cp
11 root 155 ki31 0K 256K CPU6 6 24.0H 96.44% [idle{idle: cp
11 root 155 ki31 0K 256K CPU2 2 24.0H 94.87% [idle{idle: cp
11 root 155 ki31 0K 256K CPU5 5 23.9H 93.80% [idle{idle: cp
11 root 155 ki31 0K 256K CPU15 15 23.9H 93.47% [idle{idle: cp
11 root 155 ki31 0K 256K CPU3 3 24.0H 90.80% [idle{idle: cp
11 root 155 ki31 0K 256K CPU11 11 23.9H 87.85% [idle{idle: cp
11 root 155 ki31 0K 256K RUN 7 23.9H 86.47% [idle{idle: cp
11 root 155 ki31 0K 256K CPU10 10 23.9H 85.51% [idle{idle: cp
11 root 155 ki31 0K 256K RUN 12 23.9H 78.32% [idle{idle: cp
12 root -72 - 0K 1744K WAIT 12 0:20 76.09% [intr{swi1: ne
11 root 155 ki31 0K 256K CPU4 4 23.9H 74.35% [idle{idle: cp
11 root 155 ki31 0K 256K CPU13 13 23.9H 67.51% [idle{idle: cp
11 root 155 ki31 0K 256K RUN 0 23.9H 63.12% [idle{idle: cp
12 root -72 - 0K 1744K WAIT 6 0:15 32.29% [intr{swi1: ne
12 root -92 - 0K 1744K WAIT 0 0:09 25.01% [intr{irq307:
12 root -92 - 0K 1744K WAIT 4 0:08 15.51% [intr{irq329:
0 root -92 - 0K 1552K - 14 0:03 14.85% [kernel{ix3:q0
12 root -92 - 0K 1744K WAIT 0 0:05 11.83% [intr{irq325:
12 root -72 - 0K 1744K WAIT 11 0:20 11.04% [intr{swi1: ne
12 root -92 - 0K 1744K CPU4 4 0:08 10.11% [intr{irq311:
12 root -72 - 0K 1744K WAIT 9 0:15 6.29% [intr{swi1: ne
12 root -92 - 0K 1744K WAIT 5 0:08 4.57% [intr{irq312:
12 root -92 - 0K 1744K WAIT 2 0:07 2.86% [intr{irq327:
12 root -92 - 0K 1744K WAIT 2 0:05 1.64% [intr{irq309:
12 root -92 - 0K 1744K WAIT 5 0:05 1.62% [intr{irq330:
0 root -92 - 0K 1552K - 10 0:00 0.86% [kernel{ix1:q0
0 root -92 - 0K 1552K - 3 0:00 0.76% [kernel{ix1:q4
0 root -92 - 0K 1552K - 8 0:03 0.37% [kernel{ix3:q5
32 root -16 - 0K 16K - 8 0:35 0.31% [rand_harvestq
99552 root 20 0 9860K 5824K CPU7 7 0:00 0.12% top -aSH
0 root -92 - 0K 1552K - 14 0:00 0.09% [kernel{ix1:q2
12 root -72 - 0K 1744K WAIT 9 1:23 0.08% [intr{swi1: ne
13846 unbound 20 0 213M 157M kqread 9 0:00 0.08% /usr/local/sbi
12 root -92 - 0K 1744K WAIT 1 1:09 0.06% [intr{irq308:
12 root -60 - 0K 1744K WAIT 11 0:43 0.04% [intr{swi4: cl
6575 root 20 0 50912K 33644K nanslp 3 0:25 0.03% /usr/local/binAlso to clarify I am not using the Chelsio card at all. I have been using the built in ports on the board since I switch to the 16 core system. I believe they are intel based.
I guess what I'm still having trouble understanding is why PF is not utilizing all the hardware? Ie all my cpu cores. I get it appears that PF is not very efficient at pushing higher volumes of data but surely it should at least give it its best effort by using the cores even if inefficiently. I don't think any of my cores reach 100% utilization and most don't even look operational.
Did try a few -M flags on iperf3 also but nothing seemed to show much difference except when using fairly high values.
Cheers!
-
So try changing:
hw.ix.rxd: 2048 hw.ix.txd: 2048 hw.ix.flow_control: 3You might need to set the individual flowcontrol values:
dev.ix.0.fc: 3I'd start out by doubling the descriptor values. Set the flowcontrol to 0 and check that in ifconfig.
Steve
-
Thanks for the update. Beyond what @stephenw10 already suggested, you might also consider changing (increasing) the processing limits on the ix interfaces using the following tunables:
dev.ix.Y.tx_processing_limit
dev.ix.Y.rx_processing_limitwhere Y = 0.....N and N is the number of ix interfaces in your system minus 1. Setting the rx and tx processing limit to -1 essentially removes the limit (i.e. makes it unlimited).
However, even with updated tunables, it appears challenging to make up almost 6.5 Gbit/s or throughput (though I could be wrong). I have a couple more questions:
-
What are specs of the machines on either side that you are using for testing? If you put them both on the same subnet, are they able to talk at 10 Gbit/s to each other?
-
Are you running any other add-on packages on pfSense currently or is this a barebones install?
Hope this helps.
-
-
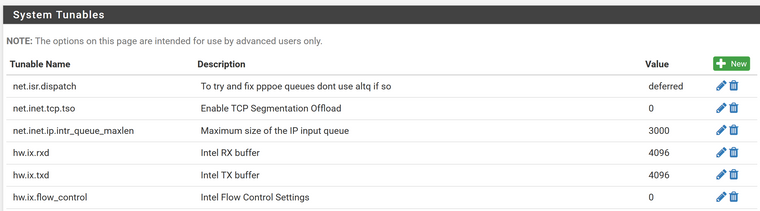
I've tried setting the hw.ix.rxd values as well as the flow control but I'm not seeing the values change even after a reboot. In PFSense I created the values and put 4096.
sysctl hw.ix.rxd
hw.ix.rxd: 2048Same with this, its set to 0.
sysctl hw.ix.flow_control
hw.ix.flow_control: 3Am I doing this wrong?
The last one appears to already be 0.
sysctl dev.ix.0.fc
dev.ix.0.fc: 0Where should these be set? Are these also via sysctl?
dev.ix.Y.tx_processing_limit
dev.ix.Y.rx_processing_limit- The destination is a NAS and the source is a linux distro on a Z800 workstation. Yes when I tried them on the same vlan they reached 10G instantly. They will also reach it network-to-network when PF is disabled.
- Not much running on PFSense right now. Barely any firewall rules, mostly only configured basic connectivity, dns, pppoe/nat, and 1 VPN, most of this is not used for the reaching each network (all internal)
Thanks all for the help.
Cheers!FYI:
-
Any thoughts on the above? Hoping to make sure I've at least done this correctly.
Cheers!
-
You probably need to add them as loader variables rather than system tunables as shown here:
https://docs.netgate.com/pfsense/en/latest/hardware/tuning-and-troubleshooting-network-cards.html#adding-to-loader-conf-localSteve
-
Thanks. I've put this. Does this look correct before I reboot?
#Improve Cache size
hw.ix.rxd: 4096
hw.ix.txd: 4096
#Change processing limit -1 is unlimited
dev.ix.-1.tx_processing_limit
dev.ix.-1.rx_processing_limitCheers!
-
@qwaven said in CPU Usage when network used:
Thanks. I've put this. Does this look correct before I reboot?
#Improve Cache size
hw.ix.rxd: 4096
hw.ix.txd: 4096Nope, read the syntax in the documentation again.
#Change processing limit -1 is unlimited
dev.ix.-1.tx_processing_limit
dev.ix.-1.rx_processing_limitAlso nope, read it again:
@tman222 said in CPU Usage when network used:dev.ix.Y.tx_processing_limit
dev.ix.Y.rx_processing_limitwhere Y = 0.....N and N is the number of ix interfaces in your system minus 1. Setting the rx and tx processing limit to -1 essentially removes the limit (i.e. makes it unlimited).
-
Thanks. Not sure I've seen documentation just going on what was posted earlier. However I've changed to this?
hw.ix.rxd="4096"
hw.ix.txd="4096"Also I found this, I am not clear what the difference between hw and dev is.
hw.ix.tx_process_limit="-1"
hw.ix.rx_process_limit="-1"Cheers!
-
@qwaven said in CPU Usage when network used:
Thanks. Not sure I've seen documentation just going on what was posted earlier. However I've changed to this?
hw.ix.rxd="4096"
hw.ix.txd="4096"Also I found this, I am not clear what the difference between hw and dev is.
hw.ix.tx_process_limit="-1"
hw.ix.rx_process_limit="-1"Cheers!
Looks better, hw. is global while dev. is per device.
-
Yeah looks good.
Not sure why but the flow control global setting doesn't seem to work for ixgbe. It needs to be set per dev using the dev.ix.X values. That may apply to the process limits, I've never tested it.Steve
-
So thanks all for your efforts. I'm pretty much thinking I'm sol here. :)
Rebooted with those settings, confirmed I can see them applied. Tried some tests with iperf3
single stream, -P10, and 3 separate streams on different ports. Nothing has changed, still about 3G speed.In regards to flow control it looked like it was already set to 0 before so I have not forced anything via loader...etc.
Cheers!
-
flowcontrol set to 0 in hw.ix or dev.ix.X?
If the link shows as
media: Ethernet autoselect (10Gbase-Twinax <full-duplex,rxpause,txpause>)it's still enabled.Steve
-
Interesting yes it appears to be.
ifconfig | grep media media: Ethernet autoselect (1000baseT <full-duplex>) media: Ethernet autoselect (10Gbase-T <full-duplex>) media: Ethernet autoselect media: Ethernet autoselect (10Gbase-Twinax <full-duplex,rxpause,txpause>) media: Ethernet autoselect (1000baseT <full-duplex>) media: Ethernet autoselect (1000baseT <full-duplex>) media: Ethernet autoselect (10Gbase-Twinax <full-duplex,rxpause,txpause>) media: Ethernet autoselect (10Gbase-T <full-duplex>) media: Ethernet autoselect (10Gbase-T <full-duplex>) media: Ethernet autoselect (10Gbase-T <full-duplex>)added this into the loader.conf.local but it appears to have had no effect.
dev.ix.0.fc=0 dev.ix.1.fc=0 dv.ix.2.fc=0 dev.ix.3.fc=0then tried
hw.ix.flow_control="0"which seems to have worked.
ifconfig | grep media media: Ethernet autoselect (1000baseT <full-duplex>) media: Ethernet autoselect (10Gbase-T <full-duplex>) media: Ethernet autoselect media: Ethernet autoselect (10Gbase-Twinax <full-duplex>) media: Ethernet autoselect (1000baseT <full-duplex>) media: Ethernet autoselect (1000baseT <full-duplex>) media: Ethernet autoselect (10Gbase-Twinax <full-duplex>) media: Ethernet autoselect (10Gbase-T <full-duplex>) media: Ethernet autoselect (10Gbase-T <full-duplex>) media: Ethernet autoselect (10Gbase-T <full-duplex>)however after running similar iperf3 tests as before the best I've seen is about this:
[ 5] 30.00-30.04 sec 15.6 MBytes 3.11 Gbits/secCheers!
-
Interesting. The opposite if what I have previously seen. Hmm.
Disappointing it did help. Might have reach the end of the road. At least for low hanging fruit type tweaks.
Steve