CPU Usage when network used
-
Interesting. The opposite if what I have previously seen. Hmm.
Disappointing it did help. Might have reach the end of the road. At least for low hanging fruit type tweaks.
Steve
-
Yeah appreciate all the help from everyone. Learned a thing or two anyhow. :)
I'll likely blow this install out when I have a bit more time and virtualize it with some other stuff. Go the L3 switch route which seems like that should work.Cheers!
-
@qwaven were those latest tests you made with MTU 1500 or MTU 9000? Perhaps try again with MTU9000 set on all parts of that network segment? The results strike me some similarity as:
https://calomel.org/network_performance.html
As for other optimizations: you could check the loader.conf and sysctl.conf values setup on
https://calomel.org/freebsd_network_tuning.html
and adjust yours carefully in that direction. -
Thanks for the info. I have applied some of this "freebsd network tuning" and I seem to have managed to make it slower. :P
May play around with it a little more, will let you know if it amounts to anything.
Cheers!
-
Something here still seems off to me that you're hitting this 3Gbit/s limit and can't get further. I know the Atom CPU you're using is slower than the Xeon D I have my box, but I don't expect it to be that much slower.
A couple more questions that come to mind right now:
- Have you tried different set of SFP+ modules and/or fiber cables? If using a direct attached copper connection instead, have you tried a different cable?
- Try this for me: Open two SSH sessions to your pfSense box. On one session launch the iperf3 server, i.e. "iperf3 -s". On the other session run an iperf3 test to localhost, i.e. "iperf3 -c localhost". What do the results look like? Hopefully they're nice and high.
- Have you looked in the system's BIOS to make sure everything is configured properly? For instance, do you have any power saving setting enabled? Might want to disable them for testing (i.e. go max performance).
Hope this helps.
-
@tman222 said in CPU Usage when network used:
Something here still seems off to me that you're hitting this 3Gbit/s limit and can't get further. I know the Atom CPU you're using is slower than the Xeon D I have my box, but I don't expect it to be that much slower.
That's where I'm still confused. I have 16x2Ghz core's. Most of them are not used when I do anything which means to me that the system is not working very hard unless there is some bottleneck elsewhere I have not seen.
I'm using DAC cables. I have tried replacing them from from used ones to brand new ones. I did not see anything change in doing so. :P
Won't be able to do the test until later but I'll try and let you know.
Re bios I did check things out but I did not see anything obvious to change. I'll check again anyway.
Cheers!
-
@qwaven said in CPU Usage when network used:
That's where I'm still confused. I have 16x2Ghz core's. Most of them are not used when I do anything which means to me that the system is not working very hard unless there is some bottleneck elsewhere I have not seen.
You should really read the contents of the sites you are pointed at, from https://calomel.org/network_performance.html
No matter what operating system you choose, the machine you run on will determine the theoretical speed limit you can expect to achieve. When people talk about how fast a system is they always mention CPU clock speed. We would expect an AMD64 2.4GHz to run faster than a Pentium3 1.0 GHz, but CPU speed is not the key, motherboard bus speed is.
I/O operations don't count as CPU usage, but these are the main limiting factor in packet based operations like networking and especially when it comes to routing.
-
Thanks! For reference I have read all these pages and is why I changed to using this board from my original PFSense board which has a fairly weak PCIe bus. :)
The page talks mostly about bus speed. So to break it down to what I know...
My system has PCI Express 3.0 interface (20 lanes) according the the cpu info. I can't really find any specific reference on the manufactures page. However I would also assume the 20 lanes are actually HSIO lanes.
http://www.cpu-world.com/CPUs/Atom/Intel-Atom%20C3958.htmlThe closest reference on the network performance page is 3.0 x16.
PCIe v3 x16 = 15.7 GB/s (128 GT/s) Fine for 100 Gbit firewall
However according to Intel it probably means my PCIE bus is 8x.
PCIe v3 x8 = 7.8 GB/s ( 64 GT/s) Fine for 40 Gbit FirewallThe PCIe slot (not used) which is clearly stated from the manufacture, from the chart:
PCIe v3 x4 = 3.9 GB/s ( 32 GT/s) Fine for 10 Gbit firewallI do not see anything specifically mentioning what speed the built-in network ports are connected to the bus at. I can only assume Supermicro would at least give them enough to achieve their rated speed.
I talk about CPU cores because I would think that data would be translated across all 16 of them instead of 2 or 3 when the desired throughput has not yet been met. IE if PF is "processing" the packets, I am assuming my CPU is involved? Or what is the purpose of putting a nic queue per core if not to load balance across all the cores?
Also recall I can reach 10G speeds just fine w/o PF enabled. This would suggest that my bus is not the problem.
Cheers!
-
ok to update some more. I ran the localhost tests without even removing the loader.conf.local settings I previously put in that made my transfers even slower. :p
Results are still pretty good.
With PF Enabled and without.
[2.4.4-RELEASE][admin@pfsense]/root: iperf3 -c localhost
Connecting to host localhost, port 5201
[ 5] local 127.0.0.1 port 26268 connected to 127.0.0.1 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 1.07 GBytes 9.22 Gbits/sec 0 1.99 MBytes
[ 5] 1.00-2.00 sec 946 MBytes 7.94 Gbits/sec 0 1.99 MBytes
[ 5] 2.00-3.00 sec 808 MBytes 6.78 Gbits/sec 0 1.99 MBytes
[ 5] 3.00-4.00 sec 780 MBytes 6.54 Gbits/sec 0 1.99 MBytes
[ 5] 4.00-5.00 sec 787 MBytes 6.60 Gbits/sec 0 1.99 MBytes
[ 5] 5.00-6.00 sec 830 MBytes 6.96 Gbits/sec 0 2.01 MBytes
[ 5] 6.00-7.00 sec 775 MBytes 6.50 Gbits/sec 0 2.01 MBytes
[ 5] 7.00-8.00 sec 859 MBytes 7.20 Gbits/sec 0 2.01 MBytes
[ 5] 8.00-9.00 sec 790 MBytes 6.63 Gbits/sec 0 2.01 MBytes
[ 5] 9.00-10.00 sec 810 MBytes 6.79 Gbits/sec 0 2.01 MBytes
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 8.28 GBytes 7.12 Gbits/sec 0 sender
[ 5] 0.00-10.02 sec 8.28 GBytes 7.10 Gbits/sec receiveriperf Done.
[2.4.4-RELEASE][admin@pfsense]/root: pfctl -d
pf disabled
[2.4.4-RELEASE][admin@pfsense]/root: iperf3 -c localhost
Connecting to host localhost, port 5201
[ 5] local 127.0.0.1 port 49345 connected to 127.0.0.1 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 1.95 GBytes 16.7 Gbits/sec 0 558 KBytes
[ 5] 1.00-2.00 sec 1.97 GBytes 16.9 Gbits/sec 0 558 KBytes
[ 5] 2.00-3.00 sec 1.96 GBytes 16.8 Gbits/sec 0 558 KBytes
[ 5] 3.00-4.00 sec 1.98 GBytes 17.0 Gbits/sec 0 558 KBytes
[ 5] 4.00-5.00 sec 1.96 GBytes 16.8 Gbits/sec 0 558 KBytes
[ 5] 5.00-6.00 sec 1.96 GBytes 16.8 Gbits/sec 0 558 KBytes
[ 5] 6.00-7.00 sec 1.95 GBytes 16.8 Gbits/sec 0 558 KBytes
[ 5] 7.00-8.00 sec 1.96 GBytes 16.8 Gbits/sec 0 558 KBytes
[ 5] 8.00-9.00 sec 1.95 GBytes 16.8 Gbits/sec 0 558 KBytes
[ 5] 9.00-10.00 sec 1.94 GBytes 16.7 Gbits/sec 0 558 KBytes
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 19.6 GBytes 16.8 Gbits/sec 0 sender
[ 5] 0.00-10.01 sec 19.6 GBytes 16.8 Gbits/sec receiveriperf Done.
Cheers!
-
Hi @qwaven - after thinking about this some more, I wanted to retrace a couple steps / clarify some information:
-
How do you currently have your pfSense box configured (i.e. with the C3958 based board)? What I mean by that is, what network interfaces are you currently using / not using, and do you have any expansion cards (e.g. Chelsio) plugged in? What do you use for storage (SATA or NVME)?
-
Can you describe to me how you are performing the three-way test (i.e. how things are connected physically), and what the specs are of each of the hosts on either end?
Thanks in advance.
-
-
@tman222 said in CPU Usage when network used:
Hi @qwaven - after thinking about this some more, I wanted to retrace a couple steps / clarify some information:
Hi @tman222 will try and answer this.
How do you currently have your pfSense box configured (i.e. with the C3958 based board)? What I mean by that is, what network interfaces are you currently using / not using, and do you have any expansion cards (e.g. Chelsio) plugged in? What do you use for storage (SATA or NVME)?
The PFSense box has 16G DDR4 memory, uses M2 SATA for storage, and does not have any addon cards...etc installed. All interfaces are built into the board. 3/4 are used.
Originally had 2 in use (1 for pppoe/out and other had all vlans on it)
Now I have 1 for pppoe, 1 for the NAS vlan, and 1 for the rest.Can you describe to me how you are performing the three-way test (i.e. how things are connected physically), and what the specs are of each of the hosts on either end?
Loading up iperf3 on the test box (linux booted) and connecting to the NAS. Various tests as outlined in a previous post. Either single connection, or running multiple streams at once.
Test box is a Z800 http://www.hp.com/canada/products/landing/workstations/files/13278_na.pdf
I can't recall exactly which cpu is in it but there are 2 qc, and lots of memory. There is an intel based dual 10G addon card to support the 10G tests. (one port used)
The NAS has 8G of memory, I'm not sure on the exact hardware inside it and has an addon card from the manufacture also dual 10G SFP+ (one port used) I believe this is Intel based chipset.
Keep in mind:
- If PF is disabled on PFsense 10G throughput is possible
- IPerf3 by default uses only memory not disk/drives...etc so I don't believe disk performance should matter. Unless I'm incorrect here...
It appears to me that there is some sort of constraint with how PF firewall passes traffic. As I am not an export on this I am not sure why 9.xGb throughput drops down to about 3G with PF enabled. Does it reserve throughput for other networks by default? IE the other vlans attached but not used during my tests? I get large rulebases can effect performance but I do not have much more than a few pass rules.
I've also made a very quick but accurate enough diagram.
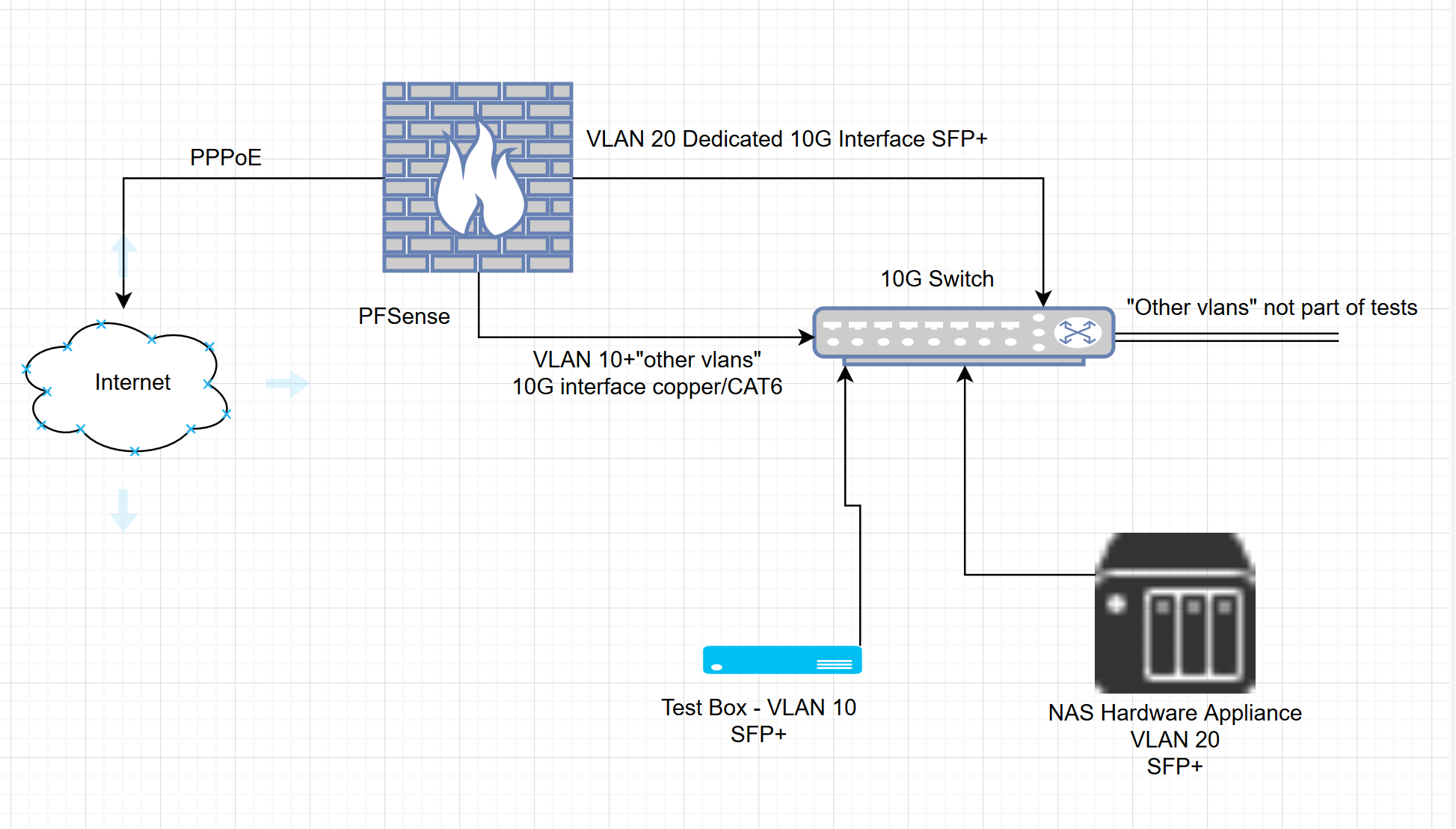
Cheers!
-
@qwaven - thanks for the additional information and clarification, I really appreciate it.
I had a couple follow up questions / suggestions:
- If you put the test box on its own dedicated interface / VLAN (i.e. no other VLAN's) -- do you see any difference in throughput?
- Also wanted to share this link with you: https://bsdrp.net/documentation/technical_docs/performance#where_is_the_bottleneck This gives gives some additional FreeBSD commands / tools for monitoring to figure out whether the bottleneck might be. If you run those while performing a test across the firewall, do you notice anything interesting?
- One thing I would recommend trying is lowering the MSS to the minimum allowed when running an iperf3 test and seeing where you are hitting a wall in terms of number of packets per second (pps) that can be transferred across the firewall (you'll see it when you keep increasing parallel streams but pps no longer increases) . I'd be curious to know where that number is with and without PF enabled on your system (the link in 2. will show how you can monitor pps with netstat).
I spent time thinking today whether this might have something with CPU PCIe lanes: The Xeon D 1518 I have in my box is only 200 MHz faster, but supports 32 PCIe lanes, while the Atom C3958 only supports 16. Although after doing some reading I'm not convinced that this is primary issue. It might come down to the difference in CPU architecture itself since 200 MHz is not a big difference in clock speed. Having said that, however, I still think I would like to see some pps numbers first before to be more certain on this.
In any case, I hope this helps and look forward to hearing what you find out.
-
You may be on to something with PCIe lanes, tman222. That's a 100% increase, which is considerable.
-
This has some great data: https://bsdrp.net/documentation/technical_docs/performance
This specifically is interesting: https://github.com/ocochard/netbenches/blob/master/Atom_C2558_4Cores-Intel_i350/forwarding-pf-ipfw/results/fbsd11-routing.r287531/README.md
Steve
-
@stephenw10 said in CPU Usage when network used:
This has some great data: https://bsdrp.net/documentation/technical_docs/performance
This specifically is interesting: https://github.com/ocochard/netbenches/blob/master/Atom_C2558_4Cores-Intel_i350/forwarding-pf-ipfw/results/fbsd11-routing.r287531/README.md
Steve
Great finds! Would be very interesting to see some packets per second (pps) numbers at this point to help reach a definitive conclusion on this.
-
Hey all sorry been a tad busy have not had time to do anything on the pfsense. Checked out the links and will check some more when able.
I do still have the same question. If I missed the answer sorry. There is talk about PCIe lanes...etc but how does this change when running PF vs not? As I've stated I get 10G w/o PF enabled.
Will post the results when I can.
Cheers!
-
The PCIe lanes would have no effect on pf performance as far as I know. I just posted that data to show that enabling pf has a huge impact on throughput, which is what you're seeing.
Steve
-
I agree with you guys. I initially asked what was installed and operating on the system to see if there might be the risk of running out of PCIe lanes. But with the setup as described that seems less likely now. More generally speaking, having enough PCIe lanes does matter though when it comes networking appliances. I think to get to the bottom of this particular case seeing some throughput numbers (e.g. packets per second) will prove to be very insightful. Hope this helps.
-
Hi all,
So hopefully I've done this correctly. :)
Did a few tests adjusting the mss with IPERF. With and without PF enabled. I also ran another perf tool to see the interface info. I've renamed the interfaces a little to better identify them here; not sure if it adds value or not.
With PF enabled:
netstat -ihw1
iperf3 ... -M 90 -T60
207k 0 0 26M 170k 0 17M 0 327k 0 0 41M 262k 0 27M 0 336k 0 0 43M 270k 0 28M 0 340k 0 0 43M 274k 0 29M 0 328k 0 0 42M 264k 0 28M 0 331k 0 0 42M 267k 0 28M 0 324k 0 0 41M 259k 0 27M 0 339k 0 0 43M 273k 0 29M 0 341k 0 0 43M 275k 0 29M 0 329k 0 0 42M 265k 0 28M 0-P2 = 400k avg
-P3 = 350-370kWithout -M its actually slightly higher with -P2
411k 0 0 525M 276k 0 268M 0 418k 0 0 541M 280k 0 276M 0 454k 0 0 586M 315k 0 317M 0 461k 0 0 602M 301k 0 315M 0and about 530k with 1 stream
systat -ifstat
Interface Traffic Peak Total
pppoe0 in 0.095 KB/s 28.351 MB/s 23.278 GB
out 0.103 KB/s 98.508 KB/s 867.165 MBix1.na in 0.000 KB/s 0.017 KB/s 39.170 KB out 0.000 KB/s 2.116 KB/s 5.986 MB ix1.fs in 110.583 MB/s 366.930 MB/s 72.624 GB out 415.854 KB/s 28.619 MB/s 4.516 GB lo0 in 0.000 KB/s 0.000 KB/s 3.539 KB out 0.000 KB/s 0.000 KB/s 3.539 KB ix3 (test box) in 394.976 KB/s 1.631 MB/s 2.970 GB out 96.656 MB/s 368.782 MB/s 93.678 GB ix1 in 96.936 MB/s 369.768 MB/s 73.133 GB out 416.906 KB/s 37.982 MB/s 4.687 GB ix0 in 0.597 KB/s 38.081 MB/s 23.697 GB out 0.478 KB/s 181.235 KB/s 1.221 GBWith PF Disabled
iperf3 ... -M 90 -P1 -T60
1.4M 0 0 200M 785k 0 104M 0 1.4M 0 0 196M 768k 0 102M 0 1.5M 0 0 204M 802k 0 107M 0 1.5M 0 0 209M 822k 0 109M 0 1.4M 0 0 199M 790k 0 105M 0 1.4M 0 0 197M 775k 0 103M 0-P2 = 1.7M
-P3 = 1.7M1 stream is about 1.5M
systat -ifstat
Interface Traffic Peak Total pppoe0 in 5.459 KB/s 5.938 KB/s 23.280 GB out 1.890 KB/s 2.957 KB/s 867.481 MB ix1.na in 0.000 KB/s 0.017 KB/s 40.049 KB out 0.000 KB/s 2.116 KB/s 6.121 MB ix1.fs in 1015.734 MB/s 1.018 GB/s 112.744 GB out 632.733 KB/s 3.091 MB/s 4.669 GB lo0 in 0.000 KB/s 0.000 KB/s 3.539 KB out 0.000 KB/s 0.000 KB/s 3.539 KB ix3 (test box) in 661.888 KB/s 3.274 MB/s 3.131 GB out 950.307 MB/s 1.028 GB/s 133.273 GB ix1 in 953.310 MB/s 1.031 GB/s 112.940 GB out 700.685 KB/s 3.462 MB/s 4.858 GB ix0 in 6.222 KB/s 6.518 KB/s 23.698 GB out 2.733 KB/s 3.419 KB/s 1.222 GBCheers!
-
Hi @qwaven - those are interesting results and I'm a little surprised you are getting lower pps throughput with multiple iperf streams. A couple new ideas came to mind:
-
https://docs.netgate.com/pfsense/en/latest/hardware/tuning-and-troubleshooting-network-cards.html#intel-ix-4-cards -- if you adjust up the "hw.intr_storm_threshold" tunable do you see any difference when running tests?
-
If you temporarily disable and remove your pppoe connection along with the "net.isr.dispatch = deferred" tunable, do you see any difference when running the tests?
Some justification for asking you to try 1) and 2) above: After reading your results, I actually tried a similar test on my pfSense box using iperf3 across the firewall between two hosts: Running iperf3 .... -M 90 resulted in approximately 300K packets per second (similar to what you saw). However, increasing the number of parallel streams to 16 increased packets per second to approximately 1.3M and all of the firewall's CPU's cores were busy handling interrupts from the Chelsio NIC. Do you see similar behavior when you increase the number of parallel streams during an iperf test? Or does it appear like just 1 CPU core is trying to manage everything?
Hope this helps.
-