Playing with fq_codel in 2.4
-
@xciter327 yea, that's miserable. You lost all the udp packets under load, too. But is it the floating rule or something else? What speed hardware? Whose 1G link? What's the next device in the chain up? Can you temporarily drop carp out of the equation?
I would just like to depressedly note that these sort of problems are seemingly universal across home and business links today - not just the bufferbloat - it's amazing the internet works at all, sometimes.
-
@dtaht said in Playing with fq_codel in 2.4:
@xciter327 yea, that's miserable. You lost all the udp packets under load, too. But is it the floating rule or something else? What speed hardware? Whose 1G link? What's the next device in the chain up? Can you temporarily drop carp out of the equation?
I would just like to depressedly note that these sort of problems are seemingly universal across home and business links today - not just the bufferbloat - it's amazing the internet works at all, sometimes.
I deeply share You sentiment about the Internet working at all. To answer some questions:
- I don't know if it's the floating rule or not, that's why I am testing :)
- Hardware is Atom C2758 with Intel NICs with all the offloading capabilities disabled.
- My 1Gbps link. I work for an ISP. Can control pretty much anything in the chain.
- I can rule out CARP as a culprit. Will test this in a closed environment.
P.S. - for some reason I keep getting an error messages when I try to add a screenshot to a post.
-
@gsakes love the before/after. I like these 35ms cake RTT tests because they more clearly show the sawtooth in tcp. On your download you can see the BE, cs5 and ef flows duking it out, when one drops, the other gets a bit of bandwidth, trading sides (so the average is flat) and because it's on inbound (less control) you only get a little boost to the other marked flows. On outbound (tons more control) you get 6.5% for background, 25% for the BS5 and EF flows combined, and the rest for BE.
You can get more resolution on the reflected sawtooths with -s .02. You can actually capture the tcp sawtooths, rtt, and cwnd on a tcp_nup test with
-s .02 --te=upload_streams=4 --socket-stats tcp_nup
You'll see additional options for various new tcp related plots on files with that additional data in the gui.
Also socket-stats EATS memory especially with .02. I need 6GB of ram and minutes of post-processing to process a 5 minute test with this much data, so... don't run for 5 minutes.
All praise to toke for the flent tool. He so totally deserves his PHD and tons of beer. I really have no idea how he manages all he does (he is a devout user of emacs's org-mode, among other things) but this is the story of flent:
https://blog.tohojo.dk/2017/04/the-story-of-flent-the-flexible-network-tester.html
A ton of folk worked on cake. after 5 years of development and a great deal of "second system syndrome", I am ambivalent about many features of cake, but things like this, per host fq, and someone actually using it do cheer me up. thx.
Are the ack-filter or nat options on in this test? :P It's really amazing how much ack traffic can be safely dropped.
-
@gsakes I'm also loving that people here are posting their flent.gz files. Can you add those to your recent post? I like producing comparison graphs when I can. I am also really fond of the CDF plots in general. I find those the most useful after we determine sanity. Then their's the "winstein" plots taken from the remy paper: http://web.mit.edu/remy/
Through all these processes we'd hoped to find plots that "spoke" to people according to how they think... and how things actually worked. Single number summaries don't work.
And to raise the quality of public conversation: Instead of the stupid fixed number of the stupid fixed cyclic public discussion: "that's my bandwidth. My (speedtest) ping at idle is nothing. My internet sucks." ""You just need more bandwidth and that will make everything better". "It doesn't." "You're doing something wrong.".
"NO. IT's THIS! (bufferbloat, badmodems, floating limiters, broken stacks, firewall stupidity, busted ideas as to prioritzation, ipv6 vs ipv4)"
and not hearing crickets... "Here's a f-ing rrul test showing how your network's f-cked up." "What's a rrul test?"... "aahhhh, glad you asked. Let me explain.... first, apt-get install flent, then...." To quote alice's restaurant, "if all we could do is get 50 people a day to walk into your network, 50 people a day, to run the rrul test, post the results publicly . and walk out... why, we'd have ourselves a movement!
And we're getting there. 2b routers to fix, though. Need all the help we can get - and tests like these have got to start getting into isp's evaluation labs, and chipset makers and vendors, so they find these problems before shipping. (that's also why flent is designed like it is - two simple DUT test servers (irtt and netperf) - and a tool for driving, plotting and scripting the tests that can run on anything. You don't need any of it on the public internet.
We just got word that irtt is now available on some versions of android.
-
@dtaht Preparing an answer - yep, spent 7 years as an OPS Engineer with the second largest CDN on the planet - so yes, I know all about bufferbloat; it's a huge issue with streaming video, maybe the biggest last mile problem, and as a CDN we can't do anything about it, very frustrating.
I will run the sawtooth graphs and provide the flent files in a few minutes.
-
@gsakes -s .02 --te=upload_streams=4 --socket-stats tcp_nup
my bad. Also this EATS memory especially with .02
-
@dtaht i am running tests in vmware player in bridged mode.
here is rrul_be:
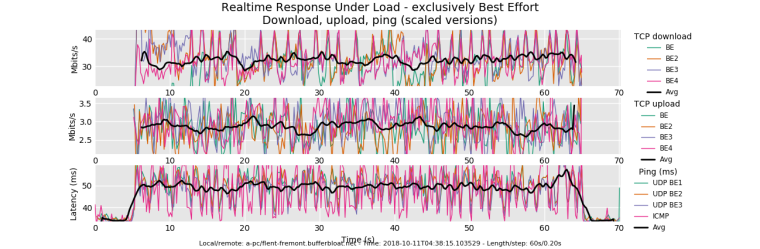
Not so bad considering what I am working with. But my download/upload speed should be higher
I made more changed to my settings
ipfw sched show 00001: 181.000 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 1 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 8ms interval 72ms quantum 1518 limit 10240 flows 1024 NoECN Children flowsets: 1 BKT Prot ___Source IP/port____ ____Dest. IP/port____ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0.0.0.0/0 0.0.0.0/0 19 24320 0 0 0 00002: 16.000 Mbit/s 0 ms burst 0 q65538 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail sched 2 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 8ms interval 72ms quantum 300 limit 1000 flows 1024 NoECN Children flowsets: 2 0 ip 0.0.0.0/0 0.0.0.0/0 15 1080 0 0 0 -
@dtaht said in Playing with fq_codel in 2.4:
--te=upload_streams=4 --socket-stats tcp_nup
I'm getting timeouts on the nup test, here's my command line:
flent -s .02 -x -H flent-fremont.bufferbloat.net -H flent-newark.bufferbloat.net -H flent-fremont.bufferbloat.net -H flent-fremont.bufferbloat.net --te=upload_streams=4 --socket-stats tcp_nup root@bitmatrix:~# tc -s qdisc show dev enp1s0 qdisc cake 8005: root refcnt 2 bandwidth 21Mbit diffserv4 dual-srchost nat nowash no-ack-filter split-gso rtt 100.0ms raw overhead 0 Sent 1112850004 bytes 2160750 pkt (dropped 3282, overlimits 5795627 requeues 2) backlog 0b 0p requeues 2 memory used: 93612b of 4Mb capacity estimate: 21Mbit min/max network layer size: 42 / 1514 min/max overhead-adjusted size: 42 / 1514 average network hdr offset: 14 Bulk Best Effort Video Voice thresh 1312Kbit 21Mbit 10500Kbit 5250Kbit target 13.8ms 5.0ms 5.0ms 5.0ms interval 108.8ms 100.0ms 100.0ms 100.0ms pk_delay 15.7ms 182us 7us 1.5ms av_delay 13.4ms 13us 0us 434us sp_delay 3us 4us 0us 4us backlog 0b 0b 0b 0b pkts 252299 1050251 4 861478 bytes 42532854 912242440 360 163019006 way_inds 0 18976 0 0 way_miss 13 11904 4 131 way_cols 0 0 0 0 drops 722 1030 0 1530 marks 0 0 0 0 ack_drop 0 0 0 0 sp_flows 1 2 1 1 bk_flows 0 1 0 0 un_flows 0 0 0 0 max_len 3028 12112 90 3028 quantum 300 640 320 300 qdisc ingress ffff: parent ffff:fff1 ---------------- Sent 4163690073 bytes 3328344 pkt (dropped 0, overlimits 0 requeues 0) backlog 0b 0p requeues 0 root@bitmatrix:~# tc -s qdisc show dev ifb4enp1s0 qdisc cake 8006: root refcnt 2 bandwidth 144Mbit diffserv4 dual-dsthost nat wash no-ack-filter split-gso rtt 100.0ms raw overhead 0 Sent 4302999869 bytes 3330326 pkt (dropped 160, overlimits 4589923 requeues 0) backlog 0b 0p requeues 0 memory used: 447108b of 7200000b capacity estimate: 144Mbit min/max network layer size: 60 / 1514 min/max overhead-adjusted size: 60 / 1514 average network hdr offset: 14 Bulk Best Effort Video Voice thresh 9Mbit 144Mbit 72Mbit 36Mbit target 5.0ms 5.0ms 5.0ms 5.0ms interval 100.0ms 100.0ms 100.0ms 100.0ms pk_delay 0us 80us 0us 10us av_delay 0us 21us 0us 7us sp_delay 0us 5us 0us 2us backlog 0b 0b 0b 0b pkts 0 3288436 0 42050 bytes 0 4300691985 0 2550124 way_inds 0 5366 0 0 way_miss 0 12349 0 9 way_cols 0 0 0 0 drops 0 160 0 0 marks 0 0 0 0 ack_drop 0 0 0 0 sp_flows 0 1 0 1 bk_flows 0 0 0 0 un_flows 0 0 0 0 max_len 0 43906 0 188 quantum 300 1514 1514 1098 -
@dtaht the first plot must have had some kind of issue because now my new plot looks like this:
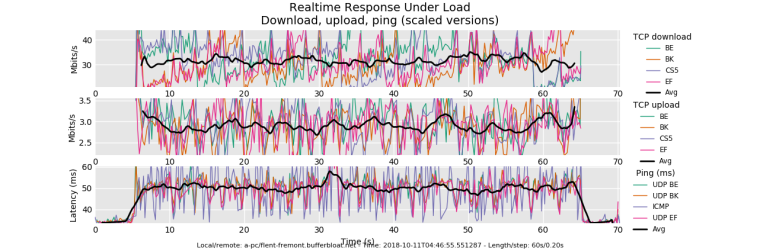
-
all vm's have additional latency for networking. Try pinging the local gw in another window, while testing, and I'll bet a beer that's at around 5ms under this load.
your vm could switch to fq_codel on it's virtual network qdisc, if it isn't already, but it won't help much, and might hurt.
-
@gsakes I goofed when I wrote that, I meant to specifiy flent-newark twice.
as for timeouts? well, --socket-stats eats cpu... or we have a bug. Or flent-newark is acting up... or... (post a bug to the flent github tracker)
-
@dtaht all my debian or arch machines run visualized, is there a way to run flent in windows?
-
@strangegopher you are getting about 120 down. rrul does not count the overhead of the ack flows, but it isn't a difference of 30mbit. I think I saw in the limiter doc you can increase the burst size? Can you run top on the gw and watch your interrupts and cpu usage (if you have 4 cores, and 25% of cpu used...) Please note that this thread is so intense that I've lost track of what hardware people are using, it's 5am here, and I'm out of coffeeeeee....
-
@dtaht pfsense runs basremetal on A1SRi-2758F, it can easily handle my speed I think lol.
edit: i downloaded ubuntu from windows store, ill report back to see if anything improves -
@dtaht yeah so that didn't work...
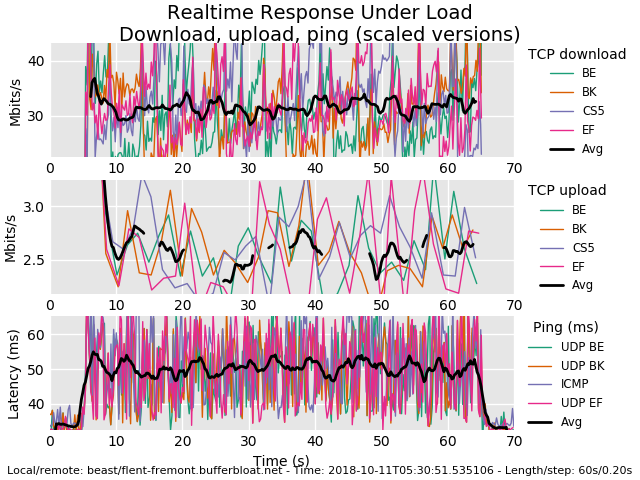
-
@gsakes try the ack-filter option on your outbound cake instance. try turning on ecn on your src and destination tcp stacks. While I'd doing flent featureitus, you can also capture cake and fq_codel stats from the gw.
if you set up ssh authorized_keys to let you get there without a login. Some things (sigh) require root, so you setup your .ssh/config as I do with:
Host gw*
User rootHost apu*
User root--te=qdisc_interfaces=enp1s0 --te=qdisc_stats_hosts=hosta
it would be good to one day be able to poll a pfsense ipfw instance this way also.
You can monitor/plot ongoing cpu_stats on the gw with
--te=cpu_stats_hosts=hostA,hostB,hostC # and if you allow ssh to localhost monitor
local stuff too.While I'm at it you can also change congestion control algorithms with --te=CC=reno # for example. I don't have bbr universally or publically deployed, linode doesn't build it in. Note, we have no way of verifying except by eyeball if we actually switched CC algos. I can certainly see (after being trained by flent) what reno, cubic, cdg, and bbr "look like"). Perhaps we need to turn an AI on these graphs! :)
I just mentioned that vm's network can get overburdened. so there's a
--te=ping_hosts=hosta,hostb,hostcinstead of just watching ping in another window. That's lowcost.
A full list of the admittedly underdocumented and sometimes buggy additional test data collection mixins is in the flent/tests/*.inc. I do note that by default we try to make flent not heisenbug the tests by hitting a cpu burden or bandwidth limit elsewhere. For example, remotely polling for cake stats is very intensive at -s .02 and does seriously impact the performance of a low end openwrt router, so I wrote a tool in c that does it way faster - (but it broke on a recent release of iproute) - and it is still intensive so beware.
pull requests for better documentation, blog posts about the joy of flenting your network, gladly accepted. :)
I do tend to script this stuff with a huge variable of all the extra tests I run, toke uses the "batch" facility also built into flent. If you like [ini] file formats, go for "batch".
There's also tcpdump, tcptrace -G, and xplot.org. I DO - when I spot a weirdness - fire off a tcpdump while flenting and look at the real capture with wireshark or xplot.org. There's a good java version of xplot, also. Doing that tcpdump/xplot.org plot of your before/after test is quite informative, you can see all the carnage going on in a tcp flow even more directly (and we used tcpdump a lot to verify that flent's sampling and stats were indeed correct - but tcpdump (even with using -s 128) is very cpu intensive and often you want to be dumping at the server side of the thing...)
-
@strangegopher "didn't work". This is the -s .02 test? If so, it's pretty normal to show that your upload throughput is very spotty over 20ms interval at this low bandwidth. The default sampling rate of -s .2 "hides" that. see nyquist theorem. This is another one of my rants - humans thing of bandwidth as data/interval, and set the interval to seconds. Where, here, we just set it to data/20ms and the results got "interesting" - you got a lot more detail on the download sawtooth.
For the upload... (nyquist bit us again)...
Arguably the plot idea itself is wrong here. We should show dots or crosses rather than connect the dots with lines when the data rate is this low, or rework how the average is smoothed.
( I really am trying to encourage folk to post their .flent.gz data so I can verify you did it right).
-
@gsakes try that --socket-stats test without -s .02
-
@strangegopher having a fat cpu may or may not help on inbound shaping. you are bound by the context switch latency which is 1000s of clocks on "modern" intel hardware. The (paper) Mill computer cpu can do it in 5. If we could do it in offloaded hardware, cool.
You are also bound by clock resolution, interrupt coalescing, and numerous other potential difficulties.
I regard the biggest remaining technical problem in the whole bufferbloat effort is doing inbound shaping cheaply enough at high rates, to eliminate the "badwidth" folk are providing at these speeds (a recent test of 5G showed 2 seconds of buffering).
I'd have preferred the core algos just roll out to more vendor hardware, and pursued political solutions.
I'd hoped that outbound shaping would get more fixed by (one example) having a programmable completion interrupt in the ethernet/gpon/cable chip - which essentially makes it "free" for bql derived systems (I still haven't found the intel chipsets that do it), or that ISPs would get clue and demand a better shaper + fq_codel from their CMTS/BRAS/ENODE-B/GPON vendors on their side so we wouldn't have to inbound shape at all. It's just a programmable interrupt per subscriber to do it right in hardware on outbound in their case. Totally doable. And profitable for whatever chipmaker/vendor gets there first. http://jvimal.github.io/senic/
'cause fixing the internet on my dime and time costs. (but do you say "no" when vint cerf, jim gettys, esr, paul vixie and dave reed tell you you're the only guy that can make even a proof of concept work? (cerowrt). I couldn't... and I was thoroughly POed about it in the first place, as while I was (retired) in nicaragua, my wifi "upgrade" from g to n one summer for my 14km long link to the internet failed completely during the (2 month long) rainy season - when there was nothing to do but surf the internet. So great. it's 8 years later and I can finally get a decent wifi link to the boonies down there, and I keep thinking about retiring again.... sailing down there... never logging in again... reading books... writing one... surfing a lot...)
As it happens, I have what I think is a better algorithm for inbound policing (It's called "bobbie"), but I abandoned the work when early versions of cake were 40% faster than fq_codel was (cake is now twice as slow as htb + fq_codel due to featureitus), and decided to focus on fixing wifi as the most bang for what little bucks I had left, and as something I knew would work. Even with grant money for it, proving if bobbie could work was going to take a long time. I published (could have patented) the idea behind that in the hope that someone else would take up the work - as (for example) the fq_codel work for bsd was taken up by a team in australia, and other volunteers keep pushing more, good stuff out, fixing bugs, and figuring out how to deploy things.
you can also look at some of the work in the conex working group of the ietf.
Anyway, I don't know why you are only getting 120mbit down on 150mbit config on a beefy box running an OS I don't know a lot about. Tuning the limiter is the last idea I have... trying to up the target and interval in codel perhaps...
-
there has been a windows version of flent at various points in its existence. getting all the dependencies right has been hard, so it's mostly used on linux and osx. yes, having a windows version packaged up would be good. There was also an effort to make it work over the web at one point (flent's output is json, and with a good json library for plotting the prototype looked good. We needed a backend database and some other stuff)
def goin to bed