Playing with fq_codel in 2.4
-
@dtaht said in Playing with fq_codel in 2.4:
@tman222 said in Playing with fq_codel in 2.4:
Since people have started sharing flent test results, I figured I'd share a couple interesting one as well from some 10Gbit testing that I have done.
these results were so lovely that I figured the internet didn't need me today.
Test 3) BQL, TSQ, and BBR are amazing. One of my favorite little tweaks is that in aiming for 98.x of the rate it just omits the ip headers from its cost estimate. As for "perfect", one thing you might find ironic, is that the interpacket latency you are getting for this load, is about what you'd get at a physical rate of 100mbits with cubic cake + a 3k bql. Or sch_fq bbr (possibly cubic also) with 3k bql. Thats basically an emulation of the original decchip tulip ethernet card from the good ole days. Loved that card ( https://web.archive.org/web/20000831052812/http://www.rage.net:80/wireless/wireless-howto.html )
If cpu context switch time had improved over the years, well, ~5usec would be "perfect" at 10gige. So, while things are about, oh, 50-100x better than they were 6 years back, it really woud be nice to have cpus that could context switch in 5 clocks.
Still: ship it! we won the internets.
could you rerun this test with cubic instead? (--te=CC=cubic)
sch_fq instead of fq_codel on the client/server? (or fq_codel if you are already using fq)
this is one place where you would see a difference in fq with --te=upload_streams=200 on the 10gige test,
but, heh, ever wonder what happens when you hit hit a 5mbit link with more flows than it could rationally handle?What should happen?
What do you want to happen?
What actually happens?
It's a question of deep protocol design and value, with behaviors specified in various rfcs.
-
@dtaht ...uploaded the wrong plot:) thx for pointing it out, I posted the proper plot just now.
-
Hi @dtaht - a couple more fun Flent Charts to add to the mix:
These Flent tests were done through my WAN connection (1Gbit symmetric Fiber) to a Google Cloud VM. The tests were done from East Coast US --> East Coast US. Traffic shaping via fq_codel enabled on pfSense router using default algorithm parameters and 950Mbit up/down limiters.
Test 1: Local host runs Linux (Debian 9) with BBR and enabled and fq qdisc. Remote host also runs Linux (Debian 9), but no changes to default TCP congestion configuration:
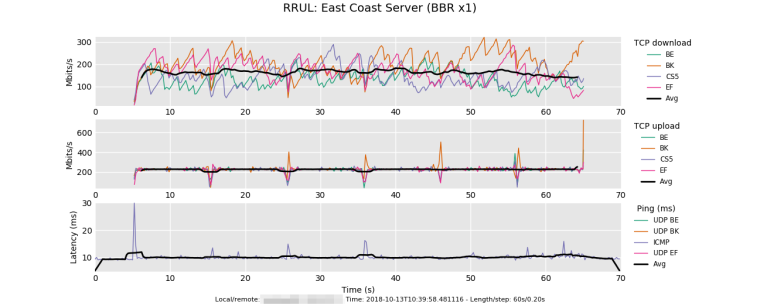
Test 2: Local host runs Linux (Debian 9) with BBR and enabled and fq qdisc. Remote host also runs Linux (Debian 9), and this time also has BBR and fq qdisc enabled just like the local host:
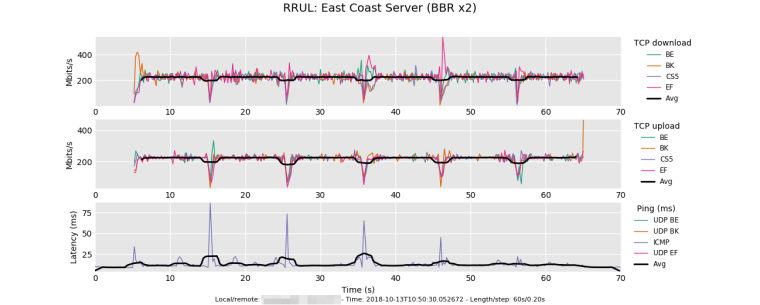
The differences here are substantial: An overall throughput increase (up and down combined) of almost 15% while download alone saw an increase of approximately 36%. BBR is quite impressive!
-
The every 10 sec unified drops in the last test are an artifact of BBR's RTT_PROBE operation, in the real world, people shouldn't be opening 4 connections at the exact same time to the exact same place. (rrul IS a stress test). the rtt_probe thing happens also during natural "pauses" in the conversation, so during crypto setup for https it can happen, as one example, doing dash-style video streaming is another.
The flent squarewave test showing bbr vs cubic behavior is revealing, however, with and without the shaper enabled. It's not all glorious....
tcp_4up_squarewave
To test a bbr download on that test type, use flent's --swap-up-down option (and note you did that in the title)
the 75ms (!!) induced latency spike is bothersome (the other side of the co-joined recovery phase), and it looks to my eye you dropped all the udp traffic on both tests for some reason. ?? Great tcp is one thing, not being able to get dns kind of problematic.
you can get more realistic real-world bbr behavior by switching to the rtt_fair tests and hitting 4 different servers at the same time.
-
@gsakes the download even-ness between flows on your last cake plot either shows diffserv priorities being stripped "out there" (common at the ISP and MPLS layer), or it shows cake "besteffort" being used on the ifb device.
tc -s qdisc show
Some ISPs re-mark all traffic they don't recognize the diffserv bits on to something else (comcast remarks to cs1). This is where you want to wash their bits out and re-mark them how you want.
If you have diffserv3 set on cake, your isp is stripping the bits. (complain), and you can save on cpu by switching inbound cake to "besteffort" mode.
To figure out if your isp isn't stripping those bits, you can switch the current cake instance over to diffserv via
tc qdisc cake change dev ifbwhichever root cake diffserv3 and re-run the test.
For those in the video distribution biz, diffserv4 gives much more bandwidth to flows with the right markings and nearly nothing to best effort.
to try and bring this back to pfsense, can it do stuff based on these bits? wash? classify? While I certainly think mostly all everyone needs is a single fq_aqm qdisc, others really want classification, port number, etc
http://snapon.lab.bufferbloat.net/~d/draft-taht-home-gateway-best-practices-00.html
-
On the BBR front, more progress.
https://lwn.net/ml/netdev/20180921155154.49489-1-edumazet@google.com/
-
@dtaht said in Playing with fq_codel in 2.4:
I don't get what you mean by codel + fq_codel. did you post a setup somewhere?
@dtaht said in Playing with fq_codel in 2.4:
I don't get what anyone means when they say pie + fq_pie or codel + fq_codel. I really don't. I was thinking you were basically doing the FAIRQ -> lots of codel or pie queues method?
Sorry, I'm trying to keep this straight as well. I'm finding little inconsistencies in the implementation/documentation that I, and others, may be perpetuating as "how it is". The screenshot below shows the limiter configuration screen where you can choose your AQM and scheduler in the pfSense WebUI. What I see now though is that even if I choose CoDel as the pipe AQM, and FQ_CODEL as the scheduler, it appears that ipfw is using droptail as the AQM. Anyone else seeing this? Another bug?
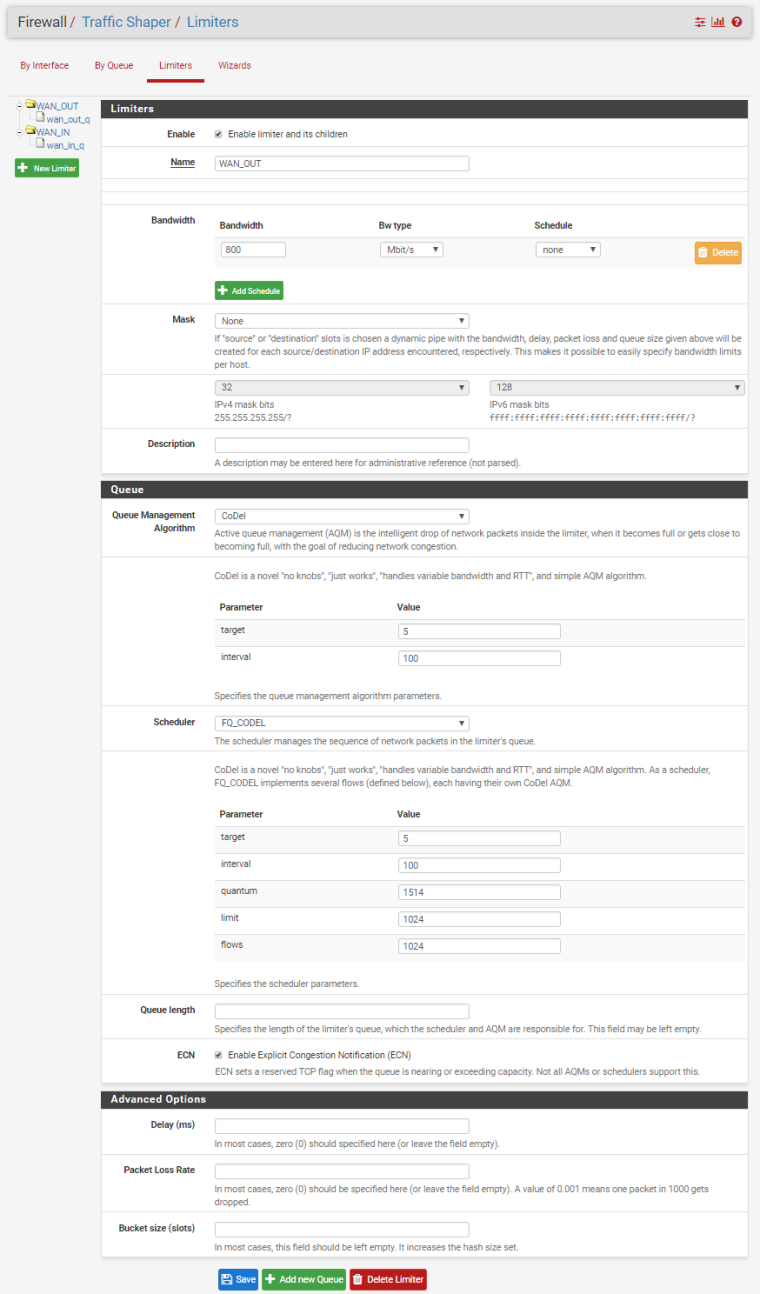
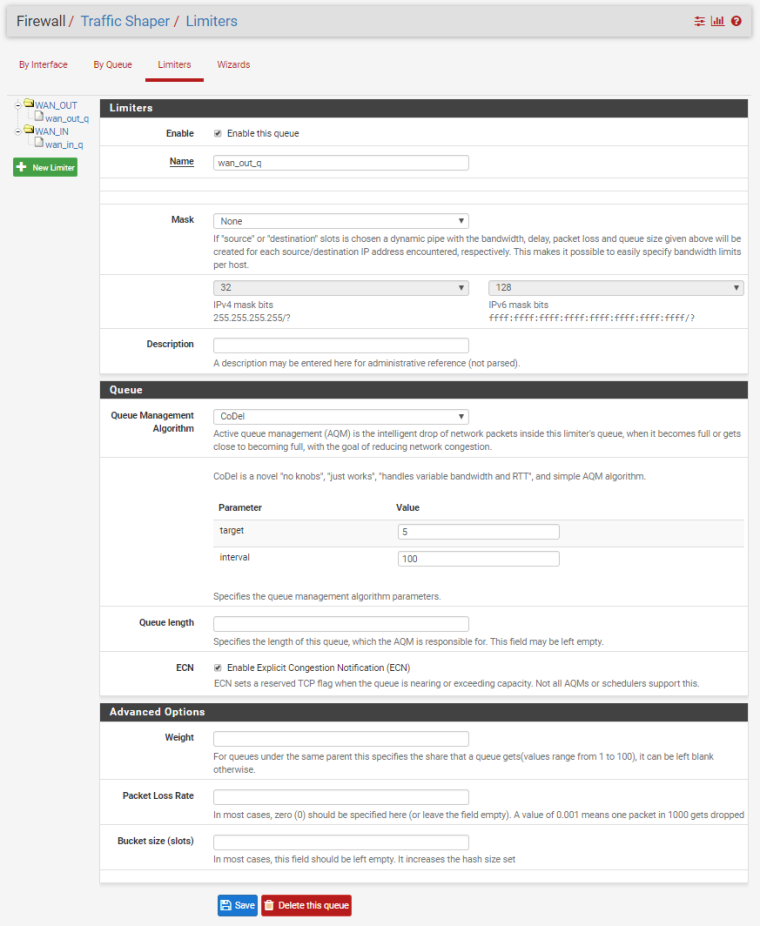
[2.4.4-RELEASE][admin@pfSense.localdomain]/root: cat /tmp/rules.limiter pipe 1 config bw 800Mb codel target 5ms interval 100ms ecn sched 1 config pipe 1 type fq_codel target 5ms interval 100ms quantum 1514 limit 1024 flows 1024 ecn queue 1 config pipe 1 codel target 5ms interval 100ms ecn pipe 2 config bw 800Mb codel target 5ms interval 100ms ecn sched 2 config pipe 2 type fq_codel target 5ms interval 100ms quantum 1514 limit 1024 flows 1024 ecn queue 2 config pipe 2 codel target 5ms interval 100ms ecn [2.4.4-RELEASE][admin@pfSense.localdomain]/root:[2.4.4-RELEASE][admin@pfSense.localdomain]/root: ipfw sched show 00001: 800.000 Mbit/s 0 ms burst 0 q65537 50 sl. 0 flows (1 buckets) sched 1 weight 0 lmax 0 pri 0 droptail sched 1 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 1514 limit 1024 flows 1024 ECN Children flowsets: 1 BKT Prot ___Source IP/port____ ____Dest. IP/port____ Tot_pkt/bytes Pkt/Byte Drp 0 ip 0.0.0.0/0 0.0.0.0/0 39516 47775336 134 174936 0 00002: 800.000 Mbit/s 0 ms burst 0 q65538 50 sl. 0 flows (1 buckets) sched 2 weight 0 lmax 0 pri 0 droptail sched 2 type FQ_CODEL flags 0x0 0 buckets 1 active FQ_CODEL target 5ms interval 100ms quantum 1514 limit 1024 flows 1024 ECN Children flowsets: 2 0 ip 0.0.0.0/0 0.0.0.0/0 384086 482821168 163 232916 0 [2.4.4-RELEASE][admin@pfSense.localdomain]/root:[2.4.4-RELEASE][admin@pfSense.localdomain]/root: pfctl -vvsr | grep limiter @86(1539633367) match out on igb0 inet all label "USER_RULE: WAN_OUT limiter" dnqueue(1, 2) @87(1539633390) match in on igb0 inet all label "USER_RULE: WAN_IN limiter" dnqueue(2, 1) [2.4.4-RELEASE][admin@pfSense.localdomain]/root: -
@dtaht I noticed that I get tons of bufferbloat when on 2.4 ghz, when compared to 5 ghz. On 5ghz I get no bufferbloat and it maxes out the speed of 150 mbits down. On 2.4 ghz I get a B score with 500+ ms in bufferbloat and speed is limited to 80 mbits down. Upload of 16 mbits works just fine on either band. Any way to create a tired system for 2.4 ghz clients to use different queue?
-
EDIT:
Turns out you CAN configure these queues, but you have to do so after the fact. We don't know the ID ahead of time, these are generated automatically. So we would have to make the patch handle a new number space, possibly reserved or pre-calculated, to use for configuring these queues.
Here's a re-iteration of the flow diagram for dummynet:
(flow_mask|sched_mask) sched_mask +---------+ weight Wx +-------------+ | |->-[flow]-->--| |-+ -->--| QUEUE x | ... | | | | |->-[flow]-->--| SCHEDuler N | | +---------+ | | | ... | +--[LINK N]-->-- +---------+ weight Wy | | +--[LINK N]-->-- | |->-[flow]-->--| | | -->--| QUEUE y | ... | | | | |->-[flow]-->--| | | +---------+ +-------------+ | +-------------+ -
@strangegopher said in Playing with fq_codel in 2.4:
@dtaht I noticed that I get tons of bufferbloat when on 2.4 ghz, when compared to 5 ghz. On 5ghz I get no bufferbloat and it maxes out the speed of 150 mbits down. On 2.4 ghz I get a B score with 500+ ms in bufferbloat and speed is limited to 80 mbits down. Upload of 16 mbits works just fine on either band. Any way to create a tired system for 2.4 ghz clients to use different queue?
The problem with wifi is that it can have a wildly variable rate. (Move farther from the AP). We wrote up that fq_codel design (for linux) here: https://arxiv.org/pdf/1703.00064.pdf and it was covered in english here: https://lwn.net/Articles/705884/
There was a bsd dev working on it last I heard. OSX has it, I'd love it if they pushed their solution back into open source.
So while you can attach a limiter to 80 mbit on the wifi device that won't work if your rate falls below that as you move farther away.
-
@mattund said in Playing with fq_codel in 2.4:
EDIT:
Turns out you CAN configure these queues, but you have to do so after the fact. We don't know the ID ahead of time, these are generated automatically. So we would have to make the patch handle a new number space, possibly reserved or pre-calculated, to use for configuring these queues.
Here's a re-iteration of the flow diagram for dummynet:
(flow_mask|sched_mask) sched_mask +---------+ weight Wx +-------------+ | |->-[flow]-->--| |-+ -->--| QUEUE x | ... | | | | |->-[flow]-->--| SCHEDuler N | | +---------+ | | | ... | +--[LINK N]-->-- +---------+ weight Wy | | +--[LINK N]-->-- | |->-[flow]-->--| | | -->--| QUEUE y | ... | | | | |->-[flow]-->--| | | +---------+ +-------------+ | +-------------+Even with that diagram I'm confused. :) I think some of the intent here is to get per host and per flow fair queuing + aqm which to me is something that
uses the fairq scheduler per IP, each instance of which has a fq_codel qdisc.But I still totally don't get what folk are describing as codel + fq_codel.
...
My biggest open question however is that we are hitting cpu limits on various higher speeds, and usually the way to improve that is to increase the token bucket size. Is there a way to do that here?
-
@dtaht @strangegopher There's also this https://www.bufferbloat.net/projects/make-wifi-fast/wiki/
-
@pentangle said in Playing with fq_codel in 2.4:
@dtaht @strangegopher There's also this https://www.bufferbloat.net/projects/make-wifi-fast/wiki/
That website (I'm the co-author) is a bit out of date. We didn't get funding last year... or this year. Still, the google doc at the bottom of that page is worth reading.... lots more can be done to make wifi better.
-
@dtaht said in Playing with fq_codel in 2.4:
My biggest open question however is that we are hitting cpu limits on various higher speeds, and usually the way to improve that is to increase the token bucket size. Is there a way to do that here?
Yes, it appears we can.
https://www.freebsd.org/cgi/man.cgi?query=ipfw
burst size If the data to be sent exceeds the pipe's bandwidth limit (and the pipe was previously idle), up to size bytes of data are allowed to bypass the dummynet scheduler, and will be sent as fast as the physical link allows. Any additional data will be transmitted at the rate specified by the pipe bandwidth. The burst size depends on how long the pipe has been idle; the effec- tive burst size is calculated as follows: MAX( size , bw * pipe_idle_time). -
um, er, no, I think. That's the queue size. We don't need to muck with that.
A linux "limiter" has a token bucket size and burst and cburst and quantum parameters to control how much data gets dumped into the next pipe in line per virtual interrupt.
A reasonable explanation here
https://unix.stackexchange.com/questions/100785/bucket-size-in-tbf
Or http://linux-ip.net/articles/Traffic-Control-HOWTO/classful-qdiscs.html
I'm so totally not familar with what's in bsd, but... what I wanted to set was the bucket size... the burst value, the cburst value. You are setting the token rate only, so far as I can tell. At higher rates, you need bigger buckets.
from some bsd stuff elsehwere
A token bucket has
token rate'' andbucket size''.
Tokens accumulate in a bucket at the averagetoken rate'', up to thebucket size''.
A driver can dequeue a packet as long as there are positive
tokens, and after a packet is dequeued, the size of the packet is
subtracted from the tokens.
Note that this implementation allows the token to be negative as a
deficit in order to make a decision without prior knowledge of the
packet size.
It differs from a typical token bucket that compares the packet
size with the remaining tokens beforehand.The bucket size controls the amount of burst that can dequeued at a time, and controls a greedy device trying dequeue packets as much as possible. This is the primary purpose of the token bucket regulator, and thus, the token rate should be set to the actual maximum transmission rate of the interface. -
@dtaht thanks for the correction - I've edited my previous submission. It appears we can edit burst in ipfw/dummynet so I can play with that.
-
@uptownvagrant That's closer, but we do want to dump it into the next pipe inline. Reading that seems to indicate it bypasses everything? A quantum? A bucket size?
Worth trying anyway...
-
Not to derail this thread any more off of the FQ_CODEL topic, but I thought I should mention this insane setup is actually working on my end; I think you especially will find this amusing:
| pfSense vRouter | | "edge" vRouter | | | | linux 4.9 | | | | br0: | | (no shaping) | --WAN0--> |eth1...(cake)...eth2|(vNIC)|i350|--(LAGG)-> Cable Modem | | | br1: | | | --WAN1--> |eth3...(cake)...eth4|(vNIC)|i350|---------> DSL ModemDriving home, I was laughing, thinking this was a dumb idea but, uh, it's kind of keeping up OK. For when you want the best of both worlds (pfSense's firewalling and out-of-tree Cake cloned off Git). So far I'm noticing great stability and of course, next to no bufferbloat.
These are both in the same virtual host, so they just pass traffic between eachother over virtual "Internal" interfaces, and the Linux-based vRouter has been stripped down to the bare minimums, and under load is reporting next to no CPU usage at all, on a 147M connection. I'll have to get some flent results while I'm at this. I might actually stick with it honestly.
-
-
Hi @gsakes and @mattund: The setups you have described sound intriguing and it might be something I want to try as well down the road when I have some spare time and access to an additional machine:
Could you guys talk a little more about how this is setup? Does the Linux machine in front take in all the WAN traffic, shape it and pass it through to pfSense? Are there then two sets of firewalls traffic must traverse (one on pfSense and on the Linux box) or just one? I'm just trying to understand the architecture a bit better and how one would setup up something like what you have described.
Thanks in advance.