HA CARP - IPv6 Two masters
-
Have you tried changing to addresses that CAN NOT be shortened to have a :: ?
Yes I did. No difference.
-
Did you put base/skew back to the default or not?
-
-
Well, cut loose with more. Screen shots, pcaps, whatever. IPv6 CARP works.
-
I disabled "DHCP Snooping" on the directly connected switch. That was somehow blocking stuff. Seems to be working OK now. I can no longer reproduce the issue. Will post if I can.
-
Amazing. It was a setting on the switch. Simply amazing.
Glad you found it.
-
So the problem is kind of back.
Same situation. Secondary pfsense become master for both IPv6 CARP groups, both report as master. The weird thing now is that if I shut down the secondary pfsense box IPv6 stops working completely. The primary box reports CARP status "Master"(as it always does), but the address is not reachable on the local LAN.
IGMP / DHCP snooping is disabled on the two switches between test PC and firewalls. The IPv4 CARP works fine.
-
Again, it sounds like something at layer 2.
Either of the nodes will show MASTER if it does not receive the heartbeats from the other node. Solving dual MASTER is generally as simple as fixing the reason(s) that one node is not seeing the heartbeats from the other node.
-
It most definitely not L2 issue. The devices can see each other. Confirmed with tcpdump.( tcpdump -i igb0 -ttt -n proto CARP). There are 2 VHIDs on this interface.
Master:
00:00:00.000094 IP 217.117.yyy.xxx > 224.0.0.18: VRRPv2, Advertisement, vrid 1, prio 1, authtype none, intvl 1s, length 36
00:00:01.004961 IP 217.117.yyy.xxx > 224.0.0.18: VRRPv2, Advertisement, vrid 1, prio 1, authtype none, intvl 1s, length 36
00:00:00.000103 IP6 fe80::ec4:7aff:feac:821a > ff02::12: ip-proto-112 36
00:00:01.005069 IP6 fe80::ec4:7aff:feac:821a > ff02::12: ip-proto-112 36Backup:
00:00:00.000064 IP 217.117.yyy.xxx > 224.0.0.18: VRRPv2, Advertisement, vrid 1, prio 1, authtype none, intvl 1s, length 36
00:00:01.004781 IP 217.117.yyy.xxx > 224.0.0.18: VRRPv2, Advertisement, vrid 1, prio 1, authtype none, intvl 1s, length 36
00:00:00.000062 IP6 fe80::ec4:7aff:feac:821a > ff02::12: ip-proto-112 36
00:00:01.004907 IP6 fe80::ec4:7aff:feac:821a > ff02::12: ip-proto-112 36What I did is to download a config backup from each unit and a do a restore from config. That fixed the issue for me. There were no changes made to the underlying switching network.
I also hit this bug with 2.4.3-Release-P1. That left me with one extra VHID on each interface stuck in "INIT" state. Rebooting the firewall is the only way I found to fix it.
P.S. - Yesterday I also tried shutting down the "Backup" unit and fully un-plugging it from the network. While the IPv6 CARP interface on the LAN was showing as "up" and "master" on the only firewall left, IPv6 connectivity was not working until I rebooted the firewall.
-
This post is deleted! -
Happens on other interfaces too(igb2.12):
Master:
00:00:00.000000 IP 172.28.0.1 > 224.0.0.18: VRRPv2, Advertisement, vrid 6, prio 1, authtype none, intvl 1s, length 36
00:00:01.009252 IP 172.28.0.1 > 224.0.0.18: VRRPv2, Advertisement, vrid 6, prio 1, authtype none, intvl 1s, length 36Backup:
00:00:00.000000 IP 172.28.0.1 > 224.0.0.18: VRRPv2, Advertisement, vrid 6, prio 1, authtype none, intvl 1s, length 36
00:00:01.010086 IP 172.28.0.1 > 224.0.0.18: VRRPv2, Advertisement, vrid 6, prio 1, authtype none, intvl 1s, length 36Interface shows "Master" on both devices.
igb1:
Master:
00:00:00.431700 IP 172.29.100.1 > 224.0.0.18: VRRPv2, Advertisement, vrid 2, prio 1, authtype none, intvl 1s, length 36
00:00:00.000072 IP6 fe80::ec4:7aff:feac:821b > ff02::12: ip-proto-112 36
00:00:00.964265 IP6 fe80::ec4:7aff:feab:3725 > ff02::12: ip-proto-112 36
00:00:00.040245 IP6 fe80::ec4:7aff:feac:821b > ff02::12: ip-proto-112 36
00:00:00.000067 IP 172.29.100.1 > 224.0.0.18: VRRPv2, Advertisement, vrid 2, prio 1, authtype none, intvl 1s, length 36Backup:
00:00:01.004330 IP 172.29.100.1 > 224.0.0.18: VRRPv2, Advertisement, vrid 2, prio 1, authtype none, intvl 1s, length 36
00:00:00.000053 IP6 fe80::ec4:7aff:feac:821b > ff02::12: ip-proto-112 36
00:00:00.185346 IP6 fe80::ec4:7aff:feab:3725 > ff02::12: ip-proto-112 36
00:00:00.819555 IP6 fe80::ec4:7aff:feac:821b > ff02::12: ip-proto-112 36
00:00:00.000135 IP 172.29.100.1 > 224.0.0.18: VRRPv2, Advertisement, vrid 2, prio 1, authtype none, intvl 1s, length 36For some reason the "Backup" unit is also receiving it's own advertisements, but only on IPv6.
Seems setting "advskew" to 100 on primary one, waiting for backup unit to get the config and rebooting the backup unit fixes the issue with the advertisements. Pending further testing of course.
-
You should be decoding those as CARP, not VRRP so we can see what is going on in a more clear fashion. You can:
-
Set the protocol to CARP then view the capture in Diagnostics > Packet Capture. That will result in tcpdump decoding as CARP.
-
Set wireshark to decode as CARP by right-clicking a VRRP packet and using Decode As to decode protocol 112 as CARP instead of VRRP.

You should never have to touch advbase/advskew. They should be 1/0 on the primary which should sync to 1/100 on the secondary.
I do recall one issue with IPv6 CARP and the way the VIPs are defined. I cannot remember if it was leading zeroes, capital hex digits or what. How are you specifying your CARP VIPs?
For some reason the “Backup” unit is also receiving it’s own advertisements, but only on IPv6.
If they both think they are MASTER on a VIP they will both be advertising. If you look at the MAC addresses in the capture, you will likely see that the secondary is not receiving its own advertisements, but that it is sending them along with the primary.
-
-
Yes, I agree. I saw a suggestion about that. Need to add "-T carp" to the tcpdump command for it work:
tcpdump -npi igb1 -T carp -e | egrep "224.0.0.18|ff02::12:"for example. The "egrep" is there because if I just use "expression" carp, it does not dump the IPv6 traffic.
Back to my problem. I've reverted to 1/0(and via config sync 1/100 on backup).
How I am able to reproduce the problem:
- Make a change on any CARP VIP
- Reboot primary
However if I reboot the backup unit after I've made a change on CARP, everything works as advertised. Going to do some more dumping to try to figure it out.
-
I don't know of any fixes regarding this, but if you are rebooting these units you should be on 2.4.3_1.
https://www.netgate.com/docs/pfsense/highavailability/redundant-firewalls-upgrade-guide.html
-
I've rebuild these units from scratch since the move from 2.3.5 to 2.4.x. We had issues with other things as well, so I decided to re-do them from blank(new) devices.
Haven't had time for a real investigation yet.
I just did a dump and viewed on Wireshark. It's complaining that the packet if "malformed"
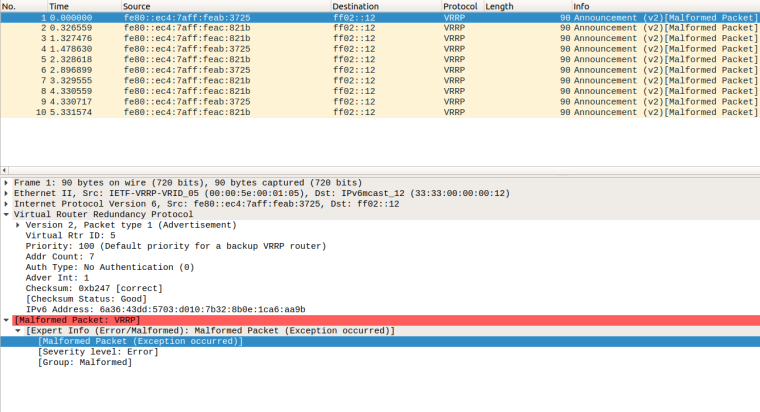
IPv4 for comparison:
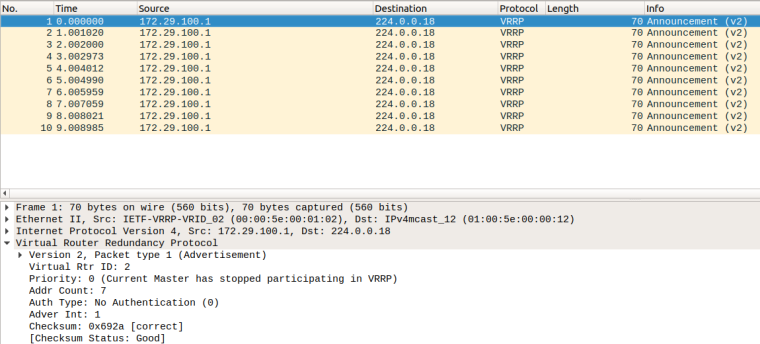
At least by the looks of it, the backup unit is receiving the advertisements, but failing to release "master.
-
That's probably because it is not VRRP, it is CARP. They are similar but different protocols.
I say again: Right-click on one of the packets, Select Decode As, and tell it to decode protocol 112 as CARP.

It would be nice if Wireshark did that automatically but it doesn't.
-
Also, try this:
In Firewall > Virtual IPs, when you define your IPv6 CARP VIPs, do NOT use any capital hex digits. (Do not enter FE80::EC4:7AFF:FEAB:3724, enter fe80::ec4:7aff:feab:3724).
Also, do NOT enter any insignificant, leading zeroes in any of the colon-delimited groups (Do not enter fe80::0ec4:7aff:feab:3724, enter fe80::ec4:7aff:feab:3724).
Thinking there is a parsing problem in the CARP code there. It looks like they are synced OK but something is happening on the ifconfig on the secondary when the CARP VIP is added to the interface. The above workarounds should clear whatever is happening up. (That's why many people never see this because they invariably enter IP addresses the way that works.) ETA: There it is: https://redmine.pfsense.org/issues/6579
ETA: When I created both of these problematic IPv6 address formats, I had to reboot the secondary to get them to go back into BACKUP status after "correcting" the VIP definitions on the primary and they synced over. It looks like the VIPs cannot be properly reapplied after they are in the broken state. It might work if the VHIDs are manually removed from the interfaces with ifconfig but I didn't pursue it. A simple restart of the secondary node is generally a hitless event if configured correctly.
-
You were correct. The backup unit goes off into some broken state unless you reboot it. I had initially the short-hand notation, but it seemed to not make a difference. This explains a lot. Any chance You can elaborate on how to delete VIPs/CARPs with ifconfig? I could not find any examples.
For other people struggling with this, easiest way I found was to past the IP here. Use the "compressed format":
https://subnettingpractice.com/ipv6_subnetting.html
-
I would have to research it as well. The easiest thing to do is just reboot the secondary.
The primary seems unaffected by this and rebooting the secondary should be a non-event.
The FreeBSD ifconfig man page states:
Whenever a last address that refers to a particular vhid is removed from an interface, the vhid is automatically removed from interface and destroyed.So this should not be possible. I could not find a way to delete that VHID after it was in this state short of a reboot. I didn't look really closely at it.
-
I'm seeing exactly this problem on 2 pairs of (vm) firewalls running 2.4.3-RELEASE-p1 (amd64) - carp works perfectly on v4, but v6 gets into master-master state. Rebooting the secondary solves it.
Both pairs are new builds with config restored.
Happy to provide any debug info that would help.
Thanks
Ed