2.4.5 High latency and packet loss, not in a vm
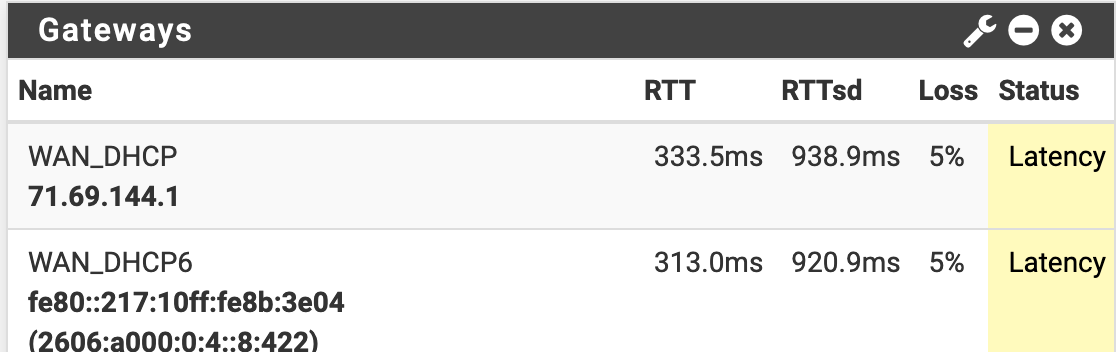
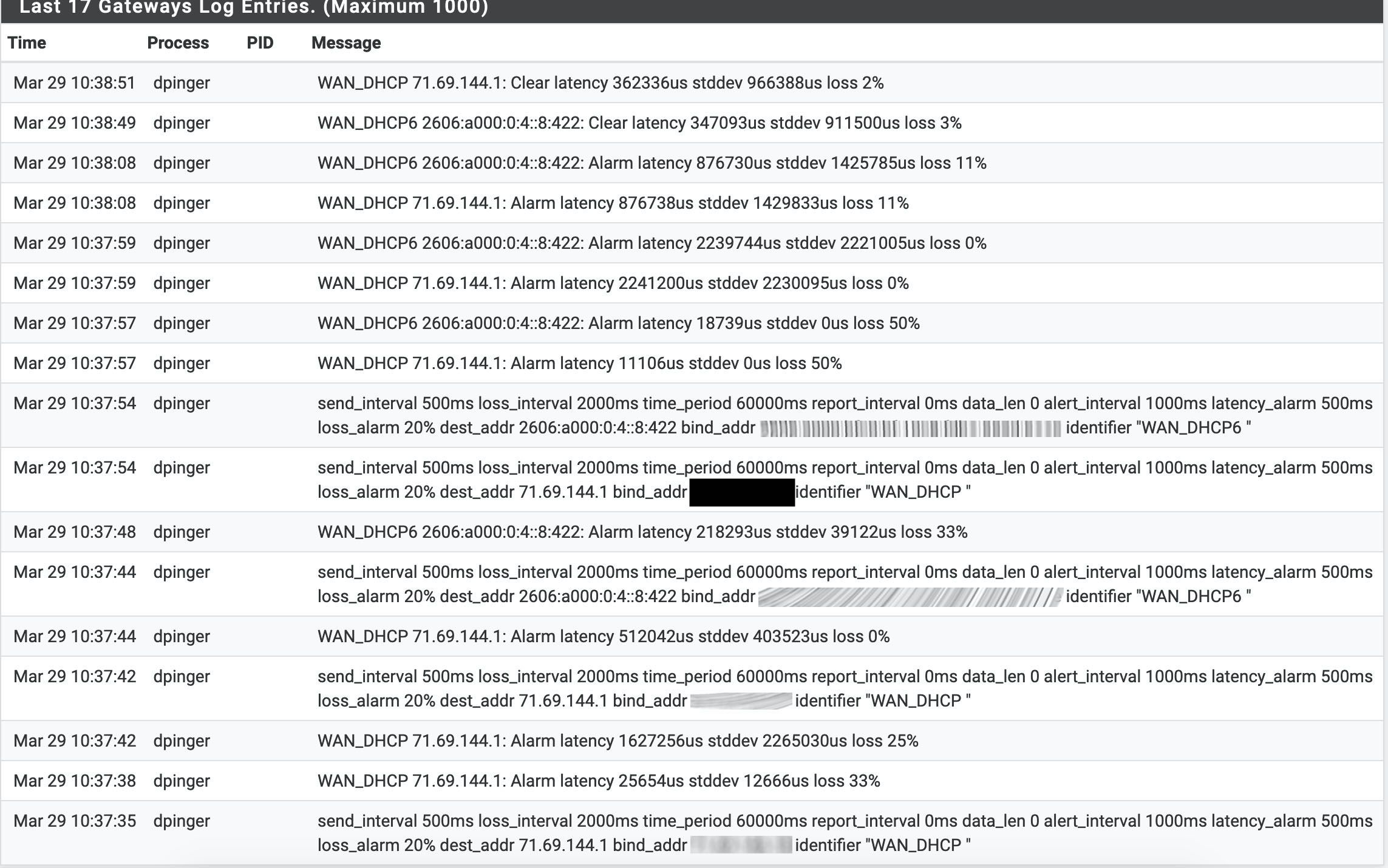
-
Delayed by pf. Pings between vlans see the latency when tables are reloaded.
From one vlan to another:
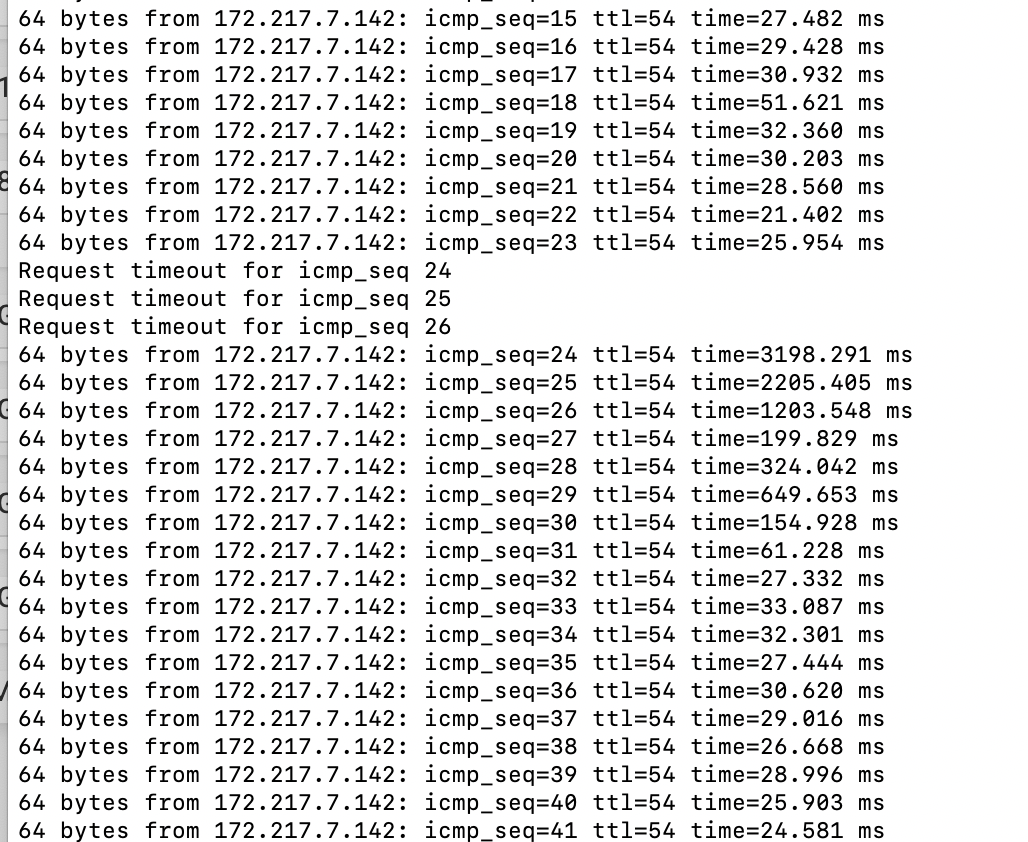
-
That is not a packet capture.
-
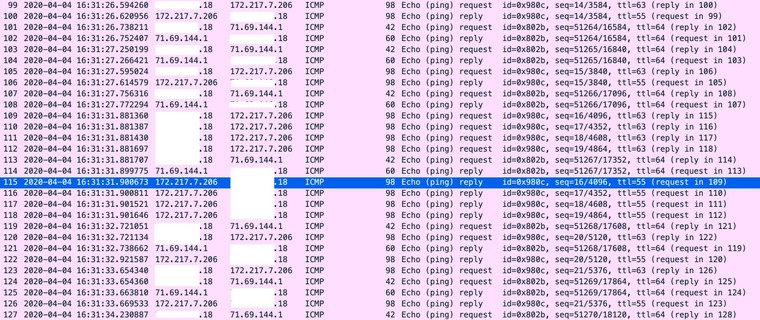
I am aware of that. Standby for a packet capture.
-
If you are not able to test in a way that allows you to post actual pcaps I don't know how much good it is going to do anyone.
It is past the point of trying to convince people this is a problem (in apparently edge cases). Now it's about trying to compile information so it can be identified and corrected.
-
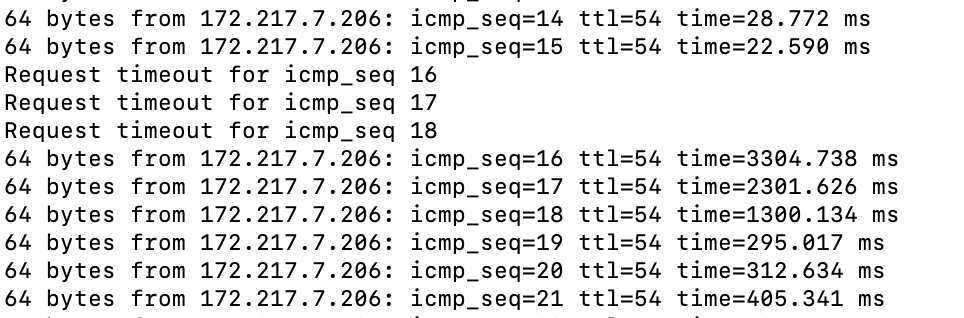
That is a pcap, in wireshark with my public ip blanked out. I would be happy to send you the file if you would like but I'll decline to post it publicly, some knuckle head will just decide to go fishing around at my public ip.
-
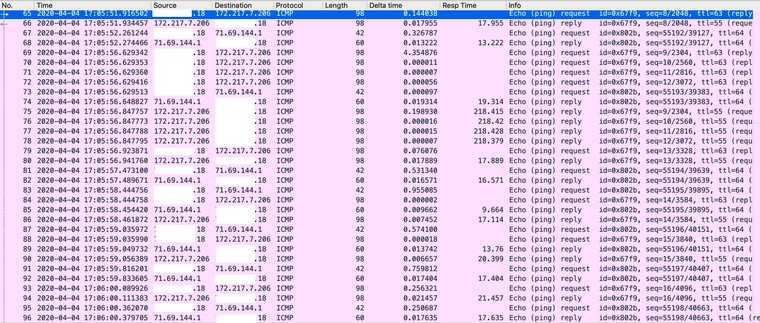
I find adding the 'time difference' and 'response time' columns useful here.
That will show if the request is delayed. And what the actual response time on the wire is. Like:

-
I just don't think this data is very helpful at diagnosing exactly what is happening.
-
@stephenw10 said in 2.4.5 High latency and packet loss, not in a vm:
I see delta time but not response time as column choices. Maybe it would be more expedient for me to send the pcap. I have used wireshark exactly once, this time. :)
OK, I see now. Custom column and then icmp.resptime. Does that make any sense if it's not sorted by the icmp seq number?
-
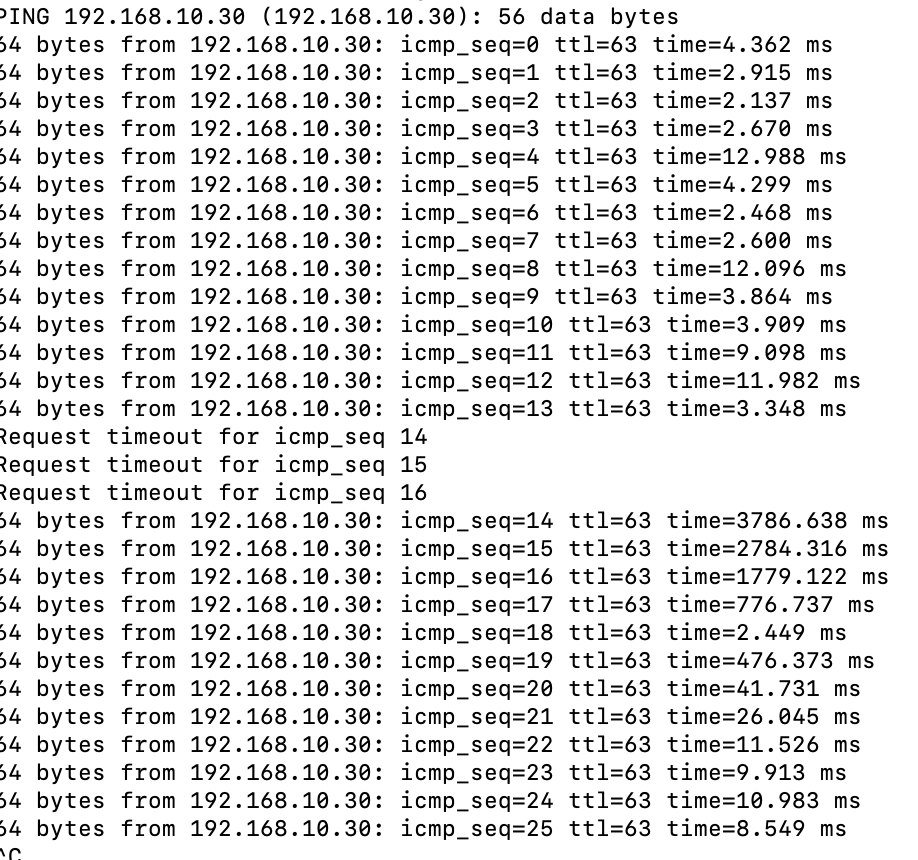
I hope this is more useful. If not I'll try again.
-
I'll add this to the mix. I changed the average time in the gateway settings. That's the time dpinger averages over. When changing the setting, saving and then applying it the interface locked up for an extended time (minutes).
So, I ssh'd in, ran top and did it again:
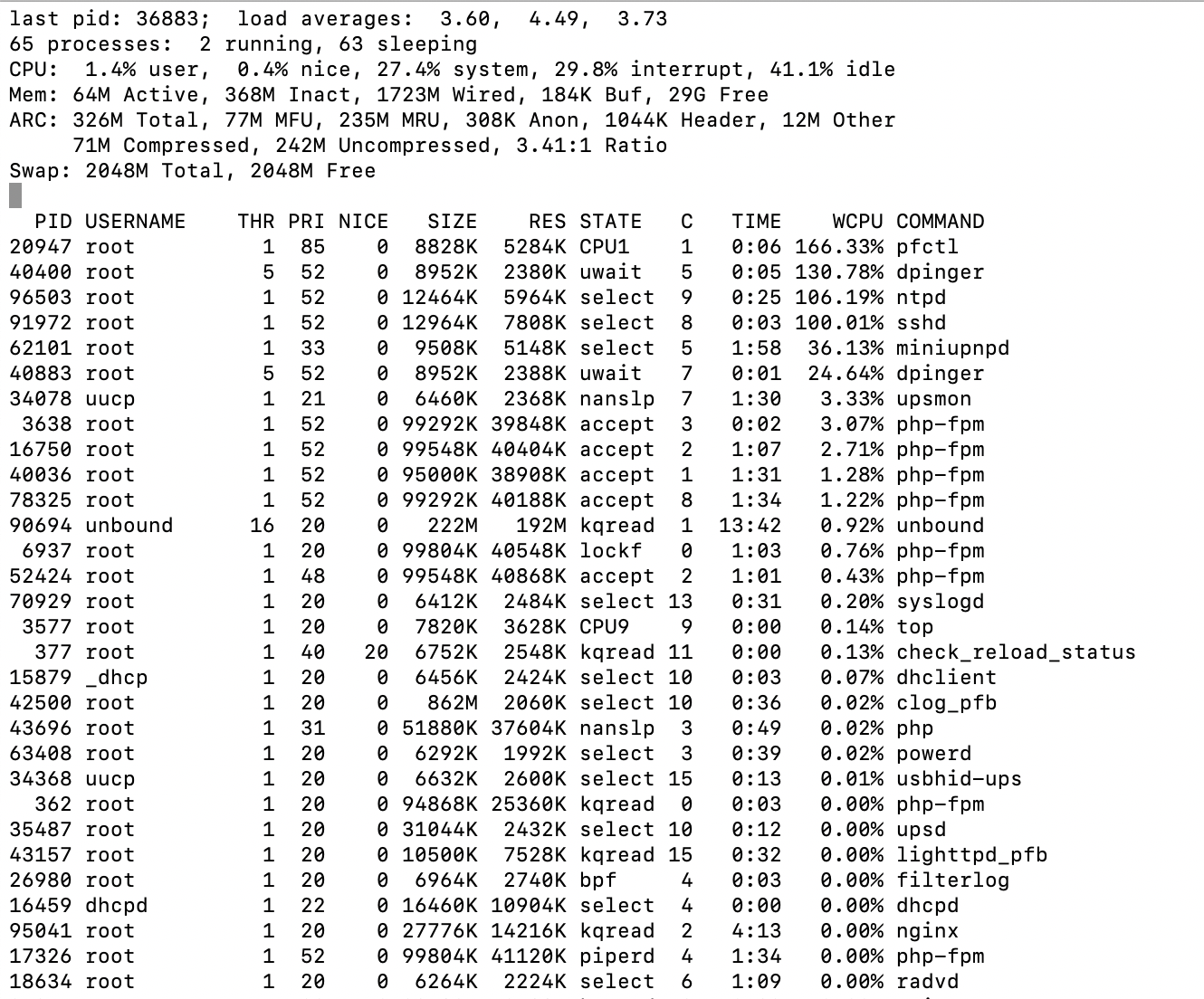
I can see dpinger using some resources, but why pfctl, ntpd and sshd? I'm not sure if that means anything, but it sure appears odd to me.
-
This looks so much like the problem I had, even before PFS 2.45. The symptoms. Latency spikes, then packet loss over and over. I had just created my first VLAN and gave the VLAN interface a static IPV6 in one of the 64s I should have. But no route and this horrible latency and packet drop. I followed the info HERE and created a 'Configuration Override' on the WAN IPV6 and set my VLAN static IPV6 and that was the only way to get darn ATT to route IPV6 from my VLAN. It made it trouble free after I spent almost a week pulling out my hair. So just wondering, can you guys ping (route) from your LAN or from the VLANS in ipv6? I am seeing ipv4 pings but did I miss the ipv6 pings...
I'm on 2.45 with no issues, and am using the latest PFBLOCKERNG. It just looks so familiar... -
I can ping ipv6 without issue. I get a /56 from my isp.
The only thing that has changed in my configuration is the pfsense version.
I have offered to share my config.xml to test on matching hardware. My Supermicro hardware is the same as a box Netgate sells other than not being Netgate branded.
This is an frustrating problem, more so for Netgate than anyone else I'm sure.
-
Can you see what is calling pfctl if you run, say:
ps -auxdww | grep pfctl. -
root 25572 33.5 0.0 8828 4888 - R 09:34 0:04.12 | | `-- /sbin/pfctl -o basic -f /tmp/rules.debug
-
I was able to run ps auxdww >> psoutput a few times before the shell locked up.
Here it is: (removed)
-
Thanks, that could be useful.
Interesting there are things there using far more CPU than I would ever expect.You might want to remove it though if those public IPs are static.
Steve
-
@stephenw10 Dynamic. No open ports, so they can bang away all they want ;)
-
I have some spare cycles, I suppose a lot of people do. You, however, are slammed.
If it would be helpful I'm willing to run through a methodical sequence of configurations and test to try to get a handle on the issue(s).
If you provided an outline of configurations like: Generic install, no ipv6, Test. Make big table(s). Test. Turn on ipv6, test. Make big ipv6 tables. Test. Like that.
I can give it some hours over the next day or two and see if that helps get a handle on the issue(s).
I would ask that the tests be specific and the data needed be spelled out clearly so my gaps in experience doesn't reduce the usefulness of the exercise.
I have a Supermicro 5018D-FN4T (32GB ECC) which is the same as Netgates XG-1541. I have been doing zfs (single ssd) UEFI installs.
I wonder if there is something apparently unrelated going on that is common with the installations that are experiencing these issues. Something simple like UPnP or the like. I wouldn't think so, but it would be nice to know exactly what is what as each service is configured in a methodical sequence.
Anyhow, just a thought.
-
The fact that pfctl is running for so long and using so many cycles implies it's having a very hard time loading the ruleset for some reason.
I would manually check the /tmp/rules.debug file. Make sure it's not absolutely huge for example.
If it isn't then start disabling things that add anything to it. So UPnP, and packages like pfBlocker.Steve
-
Nothing in there that shouldn't be. I have disabled everything including pfblocker. Made a big url alias and the problem persists.
To me, I could be wrong, it looks like big tables big issue. Small tables small issue. Small tables don't cause a dramatic issue so it appears as if everything is ok when it isn't.
My curiosity to find out what is going on is waning. If there is anything I can do to help I'd be happy to do so. Otherwise I'll go back to 2.4.4-p3 or onto something else.