Firewall locks up, possibly unbound config
-
@gertjan, thanks for the advice but I think it is an interface quirk, reinforced a bit by this thread. The device is SLC and should be relatively robust. Do you see anything problematic in the smart data? Suggest any other test (other than # diskinfo -cti and ZFS scrub)?
SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 9 Power_On_Hours 0x0012 100 100 000 Old_age Always - 377 12 Power_Cycle_Count 0x0012 100 100 000 Old_age Always - 61 163 (Max. erase count) 0x0000 100 100 000 Old_age Offline - 392 164 (Avg. erase count) 0x0000 100 100 000 Old_age Offline - 36 166 (Total bad block count) 0x0000 100 100 000 Old_age Offline - 0 167 (SSD Protect Mode) 0x0022 100 100 000 Old_age Always - 0 168 (SATA PHY Error Count) 0x0012 100 100 000 Old_age Always - 0 175 (Bad Cluster Table Ct) 0x0000 100 100 000 Old_age Offline - 0 192 (Unexpected Pwr Loss Ct)0x0012 100 100 000 Old_age Always - 11 194 Temperature_Celsius 0x0023 070 070 000 Pre-fail Always - 30 231 (% left) 0x0013 100 100 000 Pre-fail Always - 98 241 Total_LBAs_Written 0x0012 100 100 000 Old_age Always - 1264503843 (parenthetic attribute names are from the OEM (Fortassa) data sheet or ODM (Apacer for ID 231) information. SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Extended offline Completed without error 00% 354 - # 2 Extended offline Completed without error 00% 306 - SMART Selective self-test log data structure revision number 0 Note: revision number not 1 implies that no selective self-test has ever been run SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testingI set the following parameters and rebooted:
camcontrol tags ada0 -N 25 vfs.zfs.cache_flush_disable="1" -> /boot/loader.conf hint.ahcich.0.sata_rev=2 -> /boot/device.hintsCurrent uptime: 23 hours. Closing in on the 27 hour record so far.
-
@gessel Bummer, but some progress. Once again it hung, after 35 hours this time. It threw the same errors, including perhaps usefully, that an autotrim operation was in progress.
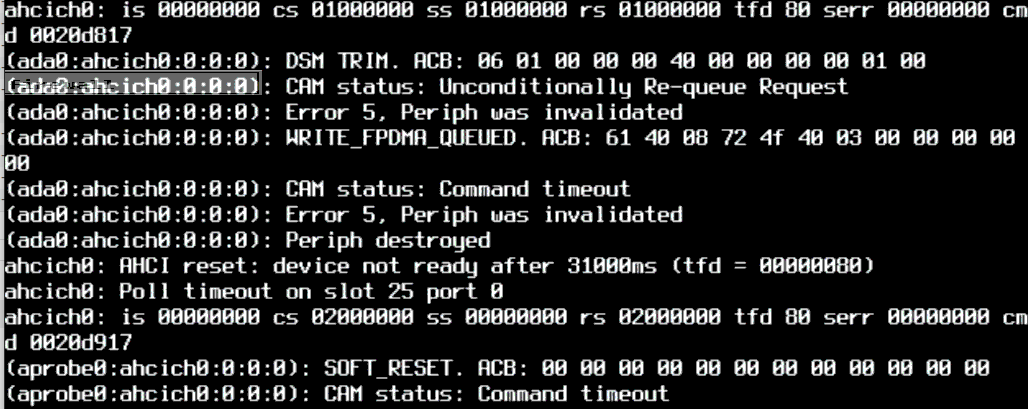
One I get control back, I'll disable autotrim. I'm still suspect of the negotiated command tag queue, but perhaps this firmware (SFPS925A) doesn't properly support TRIM, a possibility supported by the Product Change Notices from Apacer for the SFPS928A update.
I've written both Fortasa and Apacer to see if they have any archives of the firmware update. Will update with any further progress.
-
All the symptoms you describe here could be a bad drive. The firewall continuing to pass traffic but services slowly dying is exactly what happens when it cannot access the drive.
Those console logs just confirm it for me. You need to swap out the drive.Steve
-
@stephenw10 Indeed it could be, though my experience with SSD failure is binary while rotating disks tend to go through more dramatic death throes. It could be a bad/flaky interconnect (not a cable for an mSATA but possibly oxidized lands on the board). However, they are also all consistent with issues that popped up around the time this drive was produced (2015/2016ish) with autotrim and command queuing with certain drive configurations.
If I had hands on, I'd try swapping drives around - same brand/revision and alternate drives; alas, I do not have hands so that I might get more directly to the root cause.
In lieu of that, I've done the following and rebooted and verified the changes were accepted. This done, it is time to wait and see. Should this fail, I'll revert to my trusty IBM x336 until I can get my hands on that little box.
: less /boot/device.hints ... hint.ahcich.0.sata_rev=2: less /boot/loader.conf.local legal.intel_ipw.license_ack=1 legal.intel_iwi.license_ack=1 vfs.zfs.cache_flush_disable="1" vfs.zfs.trim.enabled="0": less /usr/local/etc/rc.d/camcontrol.sh #!/bin/sh CAMCONTROL=/sbin/camcontrol $CAMCONTROL tags ada0 -N 1 > /dev/null $CAMCONTROL negotiate ada0 -T disable > /dev/null $CAMCONTROL reset ada0 > /dev/null exit 0which yields after reboot:
: sysctl vfs.zfs.trim.enabled vfs.zfs.trim.enabled: 0 : sysctl vfs.zfs.cache_flush_disable vfs.zfs.cache_flush_disable: 1 : dmesg | grep -i transfers ada0: 300.000MB/s transfers (SATA 2.x, UDMA6, PIO 8192bytes) : camcontrol tags ada0 -v (pass0:ahcich0:0:0:0): dev_openings 2 : camcontrol negotiate ada0 -v ... (pass0:ahcich0:0:0:0): tagged queueing: disabledTransfer rates aren't much changed, but IOPS are hammered by these changes, definitely not HiPro, but we just need stability. Fingers crossed.
-
Mmm, I have seen bad SSDs behave almost exactly like this. pfSense will keep running even when it loses it's boot drive entirely. Services fail as they try to load or save data to the drive, eventually everything fails. After power cycling the SSD re-appears and seems good for some time until it fails again.
Usually you see no errors logged because logging is the first thing to fail. But you would see that nothing has been logged and that's a pretty telling symptom. -
@stephenw10 For sure, you're 100% correct. It is just a suboptimal cause compared to a driver/firmware incompatibility issue, which is also possible and would yield the same symptoms. Since replacing the drive isn't practical, I'm for the latter (and that it can be mitigated fairly easily).
I may well be looking to confirm that bias, but when I've had SSDs fail, they just stop working completely or fail in a way that shows up in SMART data. I haven't yet had one fail in a way that throws no SMART errors (different storage system on the drive so as long as the controller isn't hung it should get written) nor have i had one that got flaky in the way that rotating media often does as it gets near EOL or gets a platter divot that causes crashes when the head crosses that track but not otherwise.
It could very well be a power transistor or voltage regulator or some other power electronic bit that works within tolerance mostly but not always. That would be sad. There are some potentially relevant issues with SFPS925A firmware (items 2 and 3 from the H1 Product Change Notice seem relevant):
- Enhanced reliability on mapping table for L95B Nand flash
- Fixed DCO set always disable TRIM command during TRIM operating
- Fixed TRIM command hang issue when burning testing under Win10 environment
- Enhanced table fail handling when UNC happened for L95B Nand flash
- Added HW VA- dummy write support
- Added HW VA- security erase support ( pattern : 0x21 / 0x00)
- Enhanced DLMC flexibility
- Modified NAND access mechanism for Micron L95B flash characteristic. To enhance data reliability.
- Optimize internal error handling flow for corner case.
- Add Toshiba 15nm 32Gb NAND support.
- Modified Identify state reply after COMRESET.
(from http://eflash.apacerus.com/spec/PCN/Apacer_PCN_mSATA%20H1_SFPS928A%20firmware%20launch_20160906_SFPS925A.pdf)
Time will tell.
-
Yup, might as well try that first if you can.
-
@stephenw10 Over 2 days uptime now. Optimism feels risky.
-
@gessel well dang it. 2 days, 15 hours uptime and then.
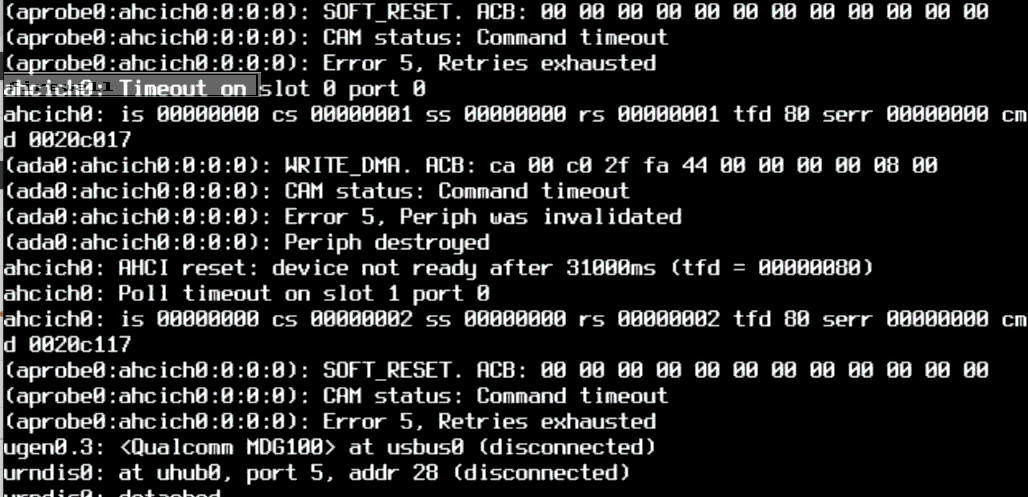
Next step, try a wiggly reseat of the mSATA disk. If that fails, revert to the tried and true Big Blue.
-
 N NogBadTheBad referenced this topic on
N NogBadTheBad referenced this topic on
-
@gessel I too have an alert from this China IP block 183.136.225.29
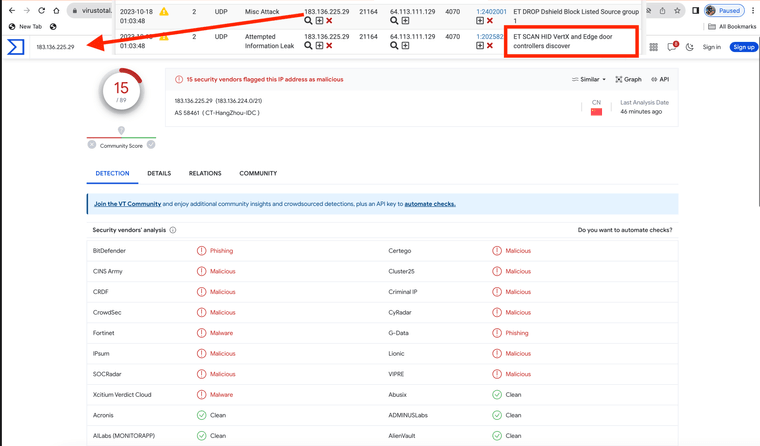
https://forum.netgate.com/topic/183488/et-scan-hid-vertx-and-edge-door-controllers-discover
Virus total shows it is an invasive actor.
183.136.225.31 also