SG3100 keeps locking up after latest update
-
@steveits thanks.
Test results aren't clear. Unless there are other ideas, it looks like I may have to swap hardware.
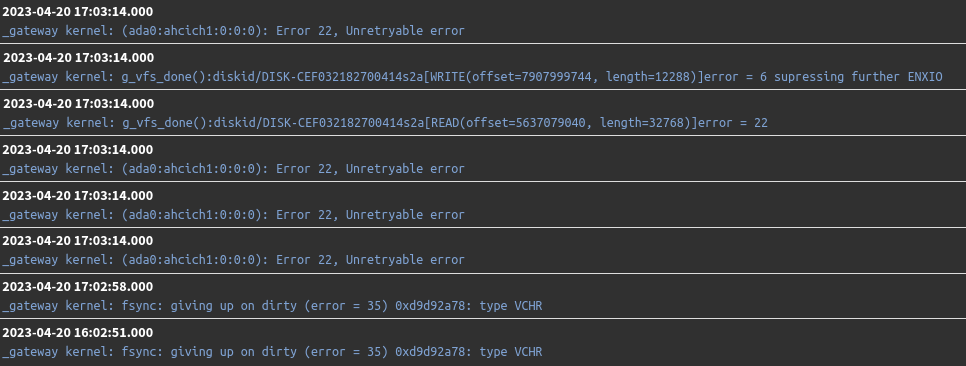
mmctest appeared normal. S.M.A.R.T. test reported overall self-assessment test "passed" but summary reported "warning":smartctl 7.3 2022-02-28 r5338 [FreeBSD 14.0-CURRENT arm] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org === START OF READ SMART DATA SECTION === SMART Error Log Version: 1 Warning: ATA error count 0 inconsistent with error log pointer 3 ATA Error Count: 0 CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error -1 occurred at disk power-on lifetime: 0 hours (0 days + 0 hours) When the command that caused the error occurred, the device was in an unknown state. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 00 00 00 00 00 00 00 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 00 00 44 00 05 00 00 00 6d+15:43:32.864 NOP [Abort queued commands] 55 00 05 00 00 00 aa 04 00:06:33.221 [RESERVED] 00 00 11 00 78 01 00 00 16d+15:13:24.797 NOP [Abort queued commands] 55 00 0f a0 00 00 aa 00 00:03:16.611 [RESERVED] 00 00 aa 55 02 00 01 00 08:31:10.848 NOP [Abort queued commands] Error -2 occurred at disk power-on lifetime: 402 hours (16 days + 18 hours) When the command that caused the error occurred, the device was in an unknown state. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 01 ff 00 00 37 01 00 Device Fault; Error: Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 00 00 00 00 01 00 00 00 00:18:34.112 NOP [Abort queued commands] 00 00 00 00 00 00 00 00 00:01:05.536 NOP [Abort queued commands] 00 01 58 03 00 00 8f 92 00:08:47.214 NOP [Don't abort queued commands] [OBS-ACS-2] 00 00 01 00 00 00 00 10 15:34:59.218 NOP [Abort queued commands] 01 00 06 00 00 00 cf 00 2d+02:13:34.312 [RESERVED] Error -4 occurred at disk power-on lifetime: 0 hours (0 days + 0 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 00 00 00 00 00 00 00 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- b0 d5 01 01 4f c2 40 08 00:00:00.000 SMART READ LOG b0 d5 01 01 4f c2 40 08 00:00:00.000 SMART READ LOG b0 d5 01 00 4f c2 40 08 00:00:00.000 SMART READ LOG b0 d0 01 00 4f c2 40 08 00:00:00.000 SMART READ DATA ec 00 01 00 00 00 40 08 00:00:00.000 IDENTIFY DEVICEExtended
smartctl 7.3 2022-02-28 r5338 [FreeBSD 14.0-CURRENT arm] (local build) Copyright (C) 2002-22, Bruce Allen, Christian Franke, www.smartmontools.org === START OF READ SMART DATA SECTION === SMART Extended Comprehensive Error Log Version: 1 (1 sectors) Device Error Count: 13 (device log contains only the most recent 4 errors) CR = Command Register FEATR = Features Register COUNT = Count (was: Sector Count) Register LBA_48 = Upper bytes of LBA High/Mid/Low Registers ] ATA-8 LH = LBA High (was: Cylinder High) Register ] LBA LM = LBA Mid (was: Cylinder Low) Register ] Register LL = LBA Low (was: Sector Number) Register ] DV = Device (was: Device/Head) Register DC = Device Control Register ER = Error register ST = Status register Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 13 [0] log entry is empty Error 12 [3] log entry is empty Error 11 [2] log entry is empty Error 10 [1] occurred at disk power-on lifetime: 0 hours (0 days + 0 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER -- ST COUNT LBA_48 LH LM LL DV DC -- -- -- == -- == == == -- -- -- -- -- 00 -- 00 00 00 00 00 00 00 00 00 00 00 Commands leading to the command that caused the error were: CR FEATR COUNT LBA_48 LH LM LL DV DC Powered_Up_Time Command/Feature_Name -- == -- == -- == == == -- -- -- -- -- --------------- -------------------- b0 00 d5 01 01 00 00 4f 00 c2 01 40 08 00:00:00.000 SMART READ LOG 2f 00 00 01 01 00 00 00 00 00 03 40 08 00:00:00.000 READ LOG EXT 2f 00 00 01 01 00 00 00 00 00 00 40 08 00:00:00.000 READ LOG EXT b0 00 d0 01 01 00 00 4f 00 c2 00 40 08 00:00:00.000 SMART READ DATA ec 00 00 01 01 00 00 00 00 00 00 40 08 00:00:00.000 IDENTIFY DEVICEDevice stats logs
Device Statistics (GP Log 0x04) Page Offset Size Value Flags Description 0x01 ===== = = === == General Statistics (rev 1) == 0x01 0x008 4 41 --- Lifetime Power-On Resets 0x01 0x010 4 1565 --- Power-on Hours 0x01 0x018 6 88793676 --- Logical Sectors Written 0x01 0x020 6 2179588462 --- Number of Write Commands 0x01 0x028 6 2631079764 --- Logical Sectors Read 0x01 0x030 6 239503858 --- Number of Read Commands 0x04 ===== = = === == General Errors Statistics (rev 1) == 0x04 0x008 4 0 --- Number of Reported Uncorrectable Errors 0x04 0x010 4 7 --- Resets Between Cmd Acceptance and Completion 0x05 ===== = = === == Temperature Statistics (rev 1) == 0x05 0x008 1 45 --- Current Temperature 0x05 0x010 1 14 --- Average Short Term Temperature 0x05 0x018 1 74 --- Average Long Term Temperature 0x05 0x020 1 45 --- Highest Temperature 0x05 0x028 1 45 --- Lowest Temperature 0x05 0x030 1 -1 --- Highest Average Short Term Temperature 0x05 0x038 1 0 --- Lowest Average Short Term Temperature 0x05 0x040 1 -1 --- Highest Average Long Term Temperature 0x05 0x048 1 0 --- Lowest Average Long Term Temperature 0x05 0x050 4 0 --- Time in Over-Temperature 0x05 0x058 1 100 --- Specified Maximum Operating Temperature 0x05 0x060 4 0 --- Time in Under-Temperature 0x05 0x068 1 0 --- Specified Minimum Operating Temperature 0x06 ===== = = === == Transport Statistics (rev 1) == 0x06 0x008 4 366 --- Number of Hardware Resets 0x06 0x018 4 0 --- Number of Interface CRC Errors 0x07 ===== = = === == Solid State Device Statistics (rev 1) == 0x07 0x008 1 86 --- Percentage Used Endurance Indicator |||_ C monitored condition met ||__ D supports DSN |___ N normalized value -
@tuser11 said in SG3100 keeps locking up after latest update:
0x01 0x010 4 1565 --- Power-on Hours
0x01 0x018 6 88793676 --- Logical Sectors Written
0x01 0x020 6 2179588462 --- Number of Write CommandsThat's how may write command per hour ?
....
Or 386 write commands per second ? -
@gertjan said in SG3100 keeps locking up after latest update:
@tuser11 said in SG3100 keeps locking up after latest update:
0x01 0x010 4 1565 --- Power-on Hours
0x01 0x018 6 88793676 --- Logical Sectors Written
0x01 0x020 6 2179588462 --- Number of Write CommandsThat's how may write command per hour ?
....
Or 386 write commands per second ?I'm not 100% sure and could not find a reference to confirm what "Value" is in relation to "Offset" and "Size". "Value" by itself is not correct for "Power-on Hours" because the device has been in production for roughly 4 years and 6 months.
-
Mmm, that does look like a disk issue with the SSD. If you see it again I would just replace it.
-
@stephenw10 just an FYI, our lockups have continued. We even swapped SG-3100 boxes (we had a cold spare). So it looks like the issue either isn't related to v23.01 (we are on 23.05.1 now) or we're just seeing a higher number of lockups. https://forum.netgate.com/topic/182065/troubleshooting-repeated-sg-3100-lockups
-
Are you still seeing the same disk errors?
-
@stephenw10 Nope, no disk errors
-
Hmm so just stops responding entirely? Nothing on the console? Can you log the console output across an outage to see if anything is shown when it happens?
-
Just curious but can you downgrade to a 22.X code. See if the problem follows
-
@stephenw10 Nope, USB console unresponsive when connected until after reboot. I'm not sure how to log console output across an outage. I don't have a computer I can leave connected to the unit. I was hoping remote syslog would give me all data I needed in this situation but was wrong.
-
@michmoor while I agree it's a fair step of elimination (owner discussed this as soon as we realized the issues are across 2 different SG-3100 units), I'm against downgrading and not having latest security patches on a device we depend on for network security.
-
@tuser11 Two devices does make it seem unlikely to be hardware. But yet specific to your setup since others haven't had the issue. Our 3100 has 32 days' uptime because that's when I installed 23.05.1.
OK new random thought: is there a chance of a ground loop? Do you have two buildings connected with a wire? Or two power feeds/grounds in a building?
-
@SteveITS funny you should mention a ground loop issue. I do not know if we have a ground loop issue. Basic equipment and APCs equipment show no ground or wiring faults. All test we've done ourselves and by a third party electrician revealed stable power, correct wiring and solid ground. We even had the main outside disconnect panel replaced beginning of this year to resolve some corrosion related problems found. Sometimes we have random issues with voltage that cause different UPSs in the building to randomly go on backup or cycle between AC/DC as if stuck in a power loop.
Yes, we do have 2 buildings physically connected and connected with a wire. Our electrical problems are....well lets just say I'm grateful for so many UPS's and APC being so kind about honoring their warranty considering the failure rate here is abnormal.
Could a power problem sneak past our UPS and damage our equipment? We haven't had any abnormal hardware failures downstream of the UPSs beyond the SG-3100. Dell PowerEdge Servers, Switches, NAS, all good.
Or better yet, are you thinking there may be a ground issue with some other equipment that the SG-3100 is sensitive to?
-
It's possible. Does the 2nd 3100 still stop responding if you run it somewhere else?
To log the console output would require something there connected to it. That could be something else that happens to be there, a server etc. Or a laptop perhaps or a RasPi maybe.
How practical that might be would depend on how often this happens I guess. -
@tuser11 said in SG3100 keeps locking up after latest update:
Yes, we do have 2 buildings physically connected and connected with a wire
If they have separate grounds, then what happens is, that wire carries the voltage difference between the grounds. We actually measured voltage on one once but it was long ago. IIRC it was burning out switch ports. Fiber is ideal to connect buildings.
That said, the first two sites I found say it's only an issue with shielded twisted pair and UTP is not a probem, which isn't my recollection at all, but it's been a long time since I've run into a situation not using fiber.
https://www.truecable.com/blogs/cable-academy/how-to-fix-a-ground-loop
https://networkencyclopedia.com/ground-loop/Often an actual Ethernet cable isn't fed through a UPS and even if it is it's likely looking for a 1000v surge not 10 volts.
-
@stephenw10 the other SG-3100 is offline in a box. I'm going to see if i can connect a USB from the SG-3100 to one of the Dell Servers and pass it through to a virtual machine that i can leave a putty session running on. As long as i have a static IP i can plug my laptop into the same switch and get access to that virtual machine even if SG-3100 goes offline. If that doesn't work I'll setup a pi or similar.
-
@SteveITS said in SG3100 keeps locking up after latest update:
https://www.truecable.com/blogs/cable-academy/how-to-fix-a-ground-loop
Good tip, i will look into this more as i just setup a Ethernet to an outdoor building near the house at home. Would hate to see these issues start creeping up at home.
-
R rcoleman-netgate referenced this topic on
-
I had some locking up issues a while back on my sg-3100 that turned out to be a bad power supply. When you swapped for your spare, did you also change PSUs?
-
@netplumbers Good tip. I don't remember. I looked through my logs and i have a log of changing hard drive and later changing the SG-3100 unit. No notes about changing the power supply. With that said, I'm going to assume I didn't and change it anyway tomorrow.
-
@netplumbers Unfortunately the power supply swap was already done and just wasn't in my notes. When I went to swap the power supply today, the supply in the box from the old system had our internal asset ID written on it from the old system. So the power supply in production is the newest supply with less than 4 months of use.