High CPU usage from egrep in pfSense+ v25.07.1
-
I've been experiencing a lot of high-CPU usage with my pfSense+ install over the past little while, possibly since I upgraded to the most recent two releases.
I'm running pfSense in a Virtual Machine with passed-through NIC's. It's running on an EPIC Milan based system with 16 threads (8 cores + 8 HT).
The CPU usage was normally around 20-30%. Now it's around 70-80% almost all the time. I did a little bit of diagnosis with this command:
top -aSH -sl
Which gives me the following output:
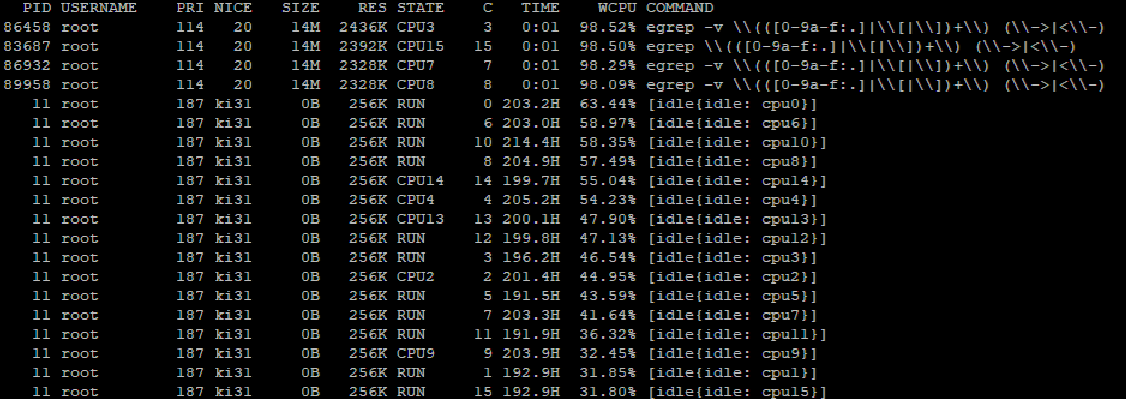
And it's consistently like this, every second (literally) I am seeing several egrep processes at the top using 100% of a thread and I believe this is the reason for the high CPU usage.
A little bit more background info if it helps:
- I have 200,000 states active in the firewall.
- I have local logging and rrd graphing enabled (although disabling both did not change the situation at all).
- I am not using pfBlockerNG or any other plugin to my knowledge that would cause this, I do have RRD Summary plugin installed though.
- I do have a lot of interfaces and VPN's active, around 30 in total.
- I do have two WAN's and both are in use.
Apart from the high CPU usage the firewall is working normally, WebUI is fully accessible, packets are moving as they should though the speed is a few gigabits lower than it should be when the CPU hits 100% load under high activity.
Any ideas what could be causing this and how I can resolve it? - Also I apologise if this is not the correct subforum to post in I didn't see a support specific area.
-
Do you have the dashboard open when it shows that? What widgets do you have on the dashboard?
Try running:
ps -auxwwdand see if you can catch the egrep. That should show what's calling it. -
Thank you for replying Stephen.
The high CPU usage is there whether I have the dashboard open or not. Widget wise I'm using:
- System Information
- Interfaces
- Wireguard
- Service Status
- Gateways
- Interface Statistics
- OpenVPN
- Traffic Graphs
- HAProxy
When I run that command I'm never seeing the high CPU usage show up at the top. I'm not sure why. But it persists with the other commands view and when viewing CPU usage on the Dashboard it's always above 70%.
Here is the full output of the log incase you see something here I don't. I would have put the log into the post here directly but the forum wouldn't allow such a long message so I attached it as a file.
-
But you can see where those egrep commands are from:
root 97895 0.0 0.0 14648 1852 - SN Thu10 14:35.18 |-- /bin/sh /var/db/rrd/updaterrd.sh root 6717 0.0 0.0 14648 1840 - SN 13:54 0:00.00 | `-- /bin/sh /var/db/rrd/updaterrd.sh root 7095 0.0 0.0 13988 2160 - SN 13:54 0:00.00 | |-- cat /tmp/pfctl_ss_out root 7358 0.0 0.0 14080 2336 - RN 13:54 0:00.05 | |-- egrep -v \\(([0-9a-f:.]|\\[|\\])+\\) (\\->|<\\-) root 7368 0.0 0.0 14420 2612 - SNC 13:54 0:00.00 | |-- wc -l root 7596 0.0 0.0 14024 2220 - SN 13:54 0:00.00 | `-- sed s/ //gSo it's the RRD graph data being pulled from the pfctl 'show states' output. I.e. the graph data for the state count values.
With 200K states that's going to be high but I wouldn't expect it to be anything like what you're seeing.
The top output you showed has the egrep processes but only for 1s. Do those last longer or just repeated 1s processes?
You can hit 'q' in top to freeze the output and then copy paste it out rather than using a screenshot. -
@stephenw10 Indeed, they last only a second. Here is the output, thank you for the pause information.
PID USERNAME PRI NICE SIZE RES STATE C TIME WCPU COMMAND 5305 root 114 20 14M 2324K CPU5 5 0:01 97.94% egrep -v \\(([0-9a-f:.]|\\[|\\])+\\) (\\->|<\\-) 1763 root 114 20 14M 2324K CPU1 1 0:01 97.91% egrep -v \\(([0-9a-f:.]|\\[|\\])+\\) (\\->|<\\-) 6277 root 114 20 14M 2328K CPU13 13 0:01 97.91% egrep -v \\(([0-9a-f:.]|\\[|\\])+\\) (\\->|<\\-) 1424 root 114 20 14M 2320K CPU15 15 0:01 97.75% egrep \\(([0-9a-f:.]|\\[|\\])+\\) (\\->|<\\-) 11 root 187 ki31 0B 256K CPU0 0 207.0H 54.05% [idle{idle: cpu0}] 11 root 187 ki31 0B 256K RUN 10 218.3H 48.24% [idle{idle: cpu10}] 11 root 187 ki31 0B 256K CPU4 4 208.9H 47.82% [idle{idle: cpu4}] 11 root 187 ki31 0B 256K RUN 8 208.6H 45.40% [idle{idle: cpu8}] 11 root 187 ki31 0B 256K CPU7 7 206.5H 44.63% [idle{idle: cpu7}] 11 root 187 ki31 0B 256K RUN 2 204.7H 44.06% [idle{idle: cpu2}] 11 root 187 ki31 0B 256K CPU12 12 203.1H 43.89% [idle{idle: cpu12}] 11 root 187 ki31 0B 256K CPU6 6 206.4H 42.12% [idle{idle: cpu6}] 11 root 187 ki31 0B 256K RUN 15 195.6H 40.35% [idle{idle: cpu15}] 11 root 187 ki31 0B 256K RUN 3 199.1H 40.01% [idle{idle: cpu3}] 11 root 187 ki31 0B 256K RUN 13 203.1H 39.98% [idle{idle: cpu13}] 11 root 187 ki31 0B 256K CPU14 14 203.2H 39.81% [idle{idle: cpu14}] 11 root 187 ki31 0B 256K CPU9 9 206.8H 37.60% [idle{idle: cpu9}] 11 root 187 ki31 0B 256K RUN 11 194.7H 33.27% [idle{idle: cpu11}] 11 root 187 ki31 0B 256K RUN 5 194.1H 31.14% [idle{idle: cpu5}] 11 root 187 ki31 0B 256K RUN 1 195.6H 30.36% [idle{idle: cpu1}]They last very briefly but are repeating almost every second or every other second etc
-
Hmm, OK. That should only run every 60s....

It looks like you have numerous updaterrd processes running. Does this problem continue across a reboot?
-
@stephenw10 Before rebooting the CPU usage was 75% on the Dashboard, after rebooting its 11%.
I do believe I saw high CPU usage like this last week before a reboot too. Perhaps its a cumulative issue?
-
Yes it could be something starting more and more updaterrd processes for some reason.
How many do you see from:
ps -auxwwd | grep updaterrd?For example:
[25.07.1-RELEASE][root@fw1.stevew.lan]/root: ps -auxwwd | grep updaterrd root 61441 0.0 0.1 4728 2296 0 S+ 17:23 0:00.01 | `-- grep updaterrd root 52916 0.0 0.1 5260 2728 - IN Mon23 2:19.79 |-- /bin/sh /var/db/rrd/updaterrd.sh root 68822 0.0 0.1 5260 2728 - IN Mon23 2:20.28 |-- /bin/sh /var/db/rrd/updaterrd.shAlso for reference:
[25.07.1-RELEASE][root@fw1.stevew.lan]/root: wc -l /tmp/pfctl_ss_out 1185 /tmp/pfctl_ss_out [25.07.1-RELEASE][root@fw1.stevew.lan]/root: time sh -c "cat /tmp/pfctl_ss_out | egrep -v '\(([0-9a-f:.]|[|])+\) (\->|<\-)' | wc -l | sed 's/ //g'" 779 0.026u 0.039s 0:00.04 125.0% 60+292k 0+0io 0pf+0wYou might try that against your far larger states file to check how long it takes.
-
Here is the result of that command:
root 64317 0.0 0.0 14728 3340 - S 18:36 0:00.00 | | `-- sh -c ps -auxwwd | grep updaterrd 2>&1 root 64926 0.0 0.0 14160 2800 - S 18:36 0:00.00 | | `-- grep updaterrd root 23043 0.0 0.0 14648 3324 - IN 17:24 0:08.08 |-- /bin/sh /var/db/rrd/updaterrd.sh root 48380 0.0 0.0 14648 3328 - SN 17:55 0:04.80 |-- /bin/sh /var/db/rrd/updaterrd.shThe other command output:
2.09 real 2.01 user 0.05 sysStates right now 188K with 22% CPU usage consistently. By comparison directly after the reboot it was at 178K states and 11% usage.
-
The actual time taken to parse the file is what counts there. On the 1K states I have you can see it takes 39ms and runs every 60s so not significant.
-
Apologies, I cropped out the time response, it takes 4098ms.
-
Hmm, that's a significant time....
-
I guess it sort of makes sense if you take your time of 39ms for 1K states and times it by 188 you get almost 8 seconds.
If we take away the overheads and assume a lot of efficiencies from performing one large egrep as opposed to opening a theorhetical 188 files and performing 188 egreps I could see how it could be 4 seconds for 188K states.
-
Yup, I'm running on a 3100 too which is probably many times slower than your CPU.
Either way it looks like it's probably the multiple process spawning causing the issue. Let's see if they start to multiply again over time.