Problems With WAN Loss Cobnection
-
@Gertjan said in Problems With WAN Loss Cobnection:
You've de-acticativated the monitoring 'action', so even when pings don't come back anymore, pfSense won't pull the interface (WAN) down.
The FreeBSD (intel) igc NIC driver is one of the most stable drivers out there. You and I share the same code - as I'm using it also. It's - should be - rock solid.
That said, IF the NIC is actually an Intel NIC ...If pings stop coming back, start looking upstream.
Btw :
@dcuadrados said in Problems With WAN Loss Cobnection:
kernel: swp_pager_getswapspace(1): failed
without consulting, I tend to says : pfSense prepares to use the swap.
That's a sign you running out of free RAM.
That's a major issue.
A native pfSense installation does have a swap space. When it starts to be used, drop the load on your system.edit : wait : I consulted. It's worse. You've run out of swap space.
And that bad. Consider that a mayday situation.
You're doing huge (?) things with your firewall. That, by itself, could make the system unstable.@dcuadrados said in Problems With WAN Loss Cobnection:
watchdog service
And you're not using it, I hope. The service watch dog is a whole problem by itself.
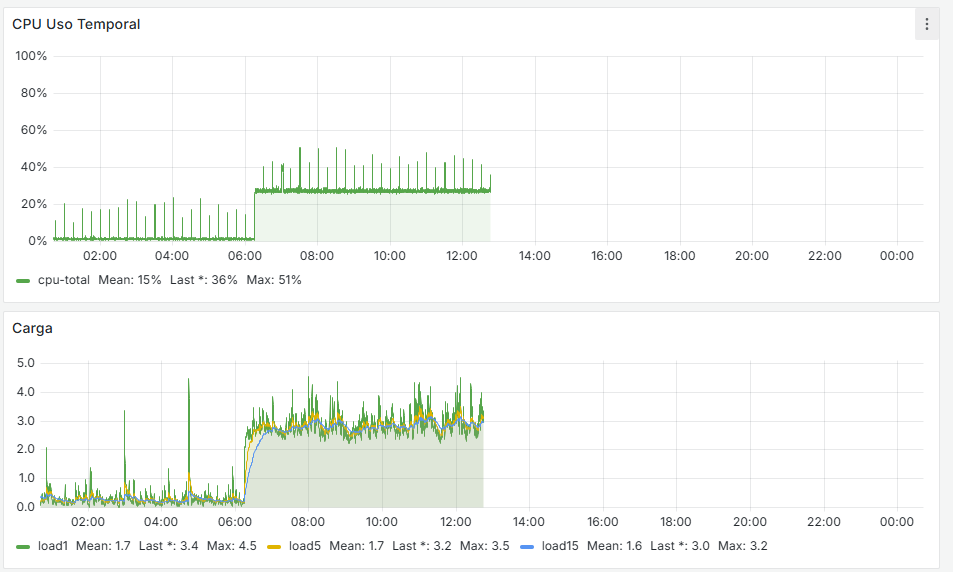
I'm looking into why the SWAP is being used — maybe too many lists in pfBlocker, which causes a heavy load, although generally the RAM usage is always below 30%, and some systems have 8 GB and others 16 GB.
Regarding the network card:
igc0@pci0:1:0:0: class=0x020000 rev=0x03 hdr=0x00 vendor=0x8086 device=0x15f3 subvendor=0x8086 subdevice=0x0000 vendor = 'Intel Corporation' device = 'Ethernet Controller I225-V' class = network subclass = ethernet igc1@pci0:2:0:0: class=0x020000 rev=0x03 hdr=0x00 vendor=0x8086 device=0x15f3 subvendor=0x8086 subdevice=0x0000 vendor = 'Intel Corporation' device = 'Ethernet Controller I225-V' class = network subclass = ethernet igc2@pci0:3:0:0: class=0x020000 rev=0x03 hdr=0x00 vendor=0x8086 device=0x15f3 subvendor=0x8086 subdevice=0x0000 vendor = 'Intel Corporation' device = 'Ethernet Controller I225-V' class = network subclass = ethernet igc3@pci0:4:0:0: class=0x020000 rev=0x03 hdr=0x00 vendor=0x8086 device=0x15f3 subvendor=0x8086 subdevice=0x0000 vendor = 'Intel Corporation' device = 'Ethernet Controller I225-V' class = network subclass = ethernetThis is what I have. I'm going to look into the SWAP and memory usage and try to reduce the load.
Regarding the watchdog service — why do you say it's a problem?
-
Generally the Service Watchdog should only ever be used for troubleshooting. It can end up restarting things unecessarily. In the worst case it can get stuck in a loop restarting services if the system is too busy to get them restarted before it triggers again. It should never be used on Snort or Suricata.
But, yes, exhausting the SWAP implies something is using a huge amount of RAM or you have a very large number of crash reports. Both are bad!
And, I'd also guess it's pfBlocker reloading the lists. But that would be a lot of large lists. -
@stephenw10 OK, I'm going to review everything to see if the errors go away, and I’ll monitor how everything behaves.
-
Good evening:
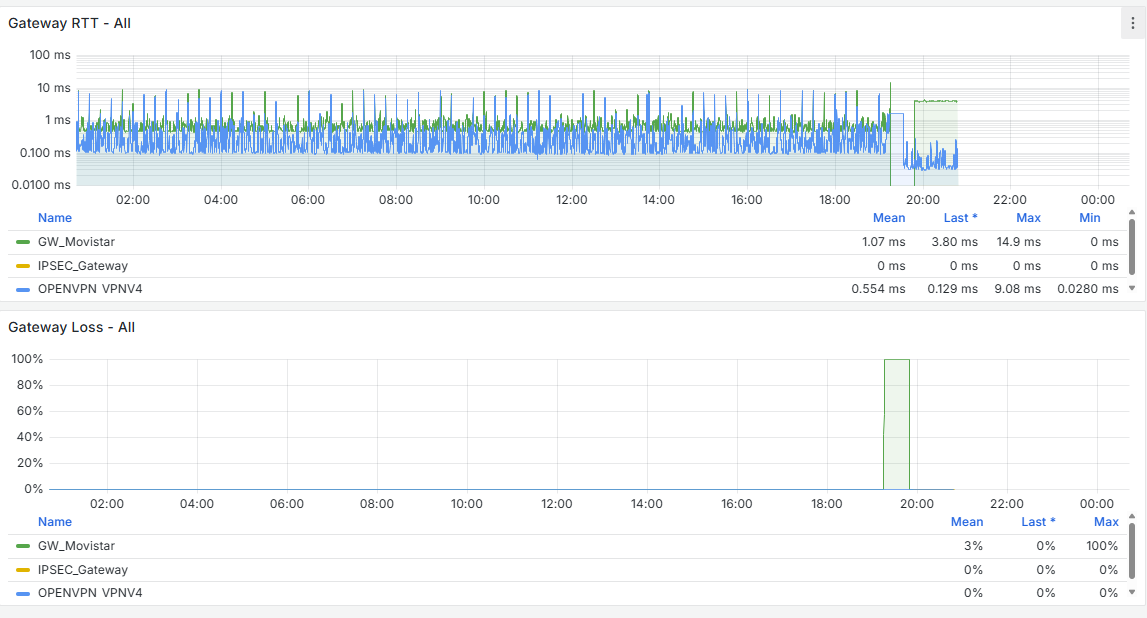
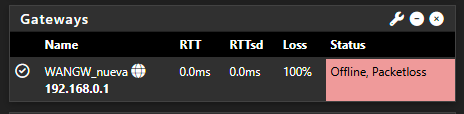
The same thing just happened to me — the WAN is marked as offline. The monitoring is set to ping the router itself, 192.168.0.1. I change it to 8.8.8.8 just now
The system starts getting overloaded at 20:44, and at 20:45 it reports this:
2025-06-25 21:25:00.750831+02:00 dpinger 18527 send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% alarm_hold 10000ms dest_addr 10.10.11.1 bind_addr 10.10.11.1 identifier "OPENVPN_NET_VPNV4 " 2025-06-25 21:25:00.714661+02:00 dpinger 17993 send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% alarm_hold 10000ms dest_addr 8.8.8.8 bind_addr 192.168.0.254 identifier "WANGW_nueva " 2025-06-25 21:25:00.699415+02:00 dpinger 60730 exiting on signal 15 2025-06-25 21:25:00.656404+02:00 dpinger 61082 exiting on signal 15 2025-06-25 20:45:19.129992+02:00 dpinger 60730 WANGW_nueva 192.168.0.1: Alarm latency 200us stddev 527us loss 21%In the general logs I only see this:
2025-06-25 20:45:19.249573+02:00 snort 70534 [1:2403366:101155] ET CINS Active Threat Intelligence Poor Reputation IP TCP group 34 [Classification: Misc Attack] [Priority: 2] {TCP} 20.65.177.212:50259 -> 192.168.0.254:11740 2025-06-25 20:44:52.902718+02:00 snort 70534 [1:2403344:101155] ET CINS Active Threat Intelligence Poor Reputation IP TCP group 23 [Classification: Misc Attack] [Priority: 2] {TCP} 20.168.0.84:49415 -> 192.168.0.254:9529 2025-06-25 20:44:25.727669+02:00 snort 17463 [1:2029509:2] ET POLICY Observed DNS Query for Suspicious TLD (.management) [Classification: Potential Corporate Privacy Violation] [Priority: 1] {UDP} 10.10.10.2:53452 -> 10.10.10.1:53 2025-06-25 20:44:12.110295+02:00 snort 70534 [1:2010937:3] ET SCAN Suspicious inbound to mySQL port 3306 [Classification: Potentially Bad Traffic] [Priority: 2] {TCP} 64.62.197.53:42048 -> 192.168.0.254:3306 2025-06-25 20:44:12.051880+02:00 snort 70534 [1:2402000:7407] ET DROP Dshield Block Listed Source group 1 [Classification: Misc Attack] [Priority: 2] {TCP} 64.62.197.53:42048 -> 192.168.0.254:3306 2025-06-25 20:43:45.293063+02:00 snort 70534 [1:2402000:7407] ET DROP Dshield Block Listed Source group 1 [Classification: Misc Attack] [Priority: 2] {TCP} 91.196.152.221:9960 -> 192.168.0.254:21295 2025-06-25 20:43:26.798973+02:00 snort 70534 [1:2403486:101155] ET CINS Active Threat Intelligence Poor Reputation IP TCP group 94 [Classification: Misc Attack] [Priority: 2] {TCP} 57.129.64.10:33405 -> 192.168.0.254:8451 2025-06-25 20:42:08.685717+02:00 snort 70534 [1:2402000:7407] ET DROP Dshield Block Listed Source group 1 [Classification: Misc Attack] [Priority: 2] {TCP} 65.49.1.169:49230 -> 192.168.0.254:143 2025-06-25 20:41:37.879948+02:00 snort 70534 [1:2403330:101155] ET CINS Active Threat Intelligence Poor Reputation IP TCP group 16 [Classification: Misc Attack] [Priority: 2] {TCP} 20.106.196.31:41654 -> 192.168.0.254:1080 2025-06-25 20:41:31.596387+02:00 snort 70534 [1:4000000:1] Intento SSH [Classification: Misc activity] [Priority: 3] {TCP} 204.76.203.83:51406 -> 192.168.0.254:22 2025-06-25 20:41:25.329334+02:00 snort 17463 [1:71074:1] microsoft [Classification: Misc activity] [Priority: 3] {TCP} 10.10.10.2:55470 -> 13.85.23.206:443 2025-06-25 20:41:15.101913+02:00 snort 70534 [1:2402000:7407] ET DROP Dshield Block Listed Source group 1 [Classification: Misc Attack] [Priority: 2] {TCP} 198.235.24.101:56931 -> 192.168.0.254:5985 2025-06-25 20:41:09.858778+02:00 snort 17463 [1:71074:1] microsoft [Classification: Misc activity] [Priority: 3] {TCP} 10.10.10.130:61457 -> 52.167.222.13:443 2025-06-25 20:40:55.527774+02:00 snort 17463 [1:71074:1] microsoft [Classification: Misc activity] [Priority: 3] {TCP} 10.10.10.2:55462 -> 20.73.194.208:443 2025-06-25 20:40:06.266021+02:00 snort 70534 [1:2402000:7407] ET DROP Dshield Block Listed Source group 1 [Classification: Misc Attack] [Priority: 2] {TCP} 204.76.203.220:36665 -> 192.168.0.254:17000 2025-06-25 20:40:03.159113+02:00 snort 70534 [1:2403466:101155] ET CINS Active Threat Intelligence Poor Reputation IP TCP group 84 [Classification: Misc Attack] [Priority: 2] {TCP} 47.251.68.250:12393 -> 192.168.0.254:12112 ...So basically just Snort blocks.
In the DNS Resolver logs I see:
2025-06-25 20:45:23.427610+02:00 unbound 51421 [51421:2] info: 10.10.10.130 client.wns.windows.com. A IN 2025-06-25 20:45:23.366522+02:00 unbound 51421 [51421:3] info: 10.10.10.130 client.wns.windows.com. A IN 2025-06-25 20:45:22.211546+02:00 unbound 51421 [51421:3] info: 10.10.10.130 geo.prod.do.dsp.mp.microsoft.com. A IN 2025-06-25 20:45:21.934996+02:00 unbound 51421 [51421:2] info: 10.10.10.130 settings-win.data.microsoft.com. A IN 2025-06-25 20:45:21.839643+02:00 unbound 51421 [51421:2] info: 10.10.10.130 licensing.mp.microsoft.com. A IN 2025-06-25 20:45:21.170553+02:00 unbound 51421 [51421:3] info: 10.10.10.130 _ldap._tcp.dc._msdcs.topalia.es. SRV IN 2025-06-25 20:45:20.926628+02:00 unbound 51421 [51421:2] info: 10.10.10.130 settings-win.data.microsoft.com. A IN 2025-06-25 20:45:20.860774+02:00 unbound 51421 [51421:2] info: 10.10.10.130 settings-win.data.microsoft.com. A IN 2025-06-25 20:45:20.830911+02:00 unbound 51421 [51421:3] info: 10.10.10.130 licensing.mp.microsoft.com. A IN 2025-06-25 20:45:20.764018+02:00 unbound 51421 [51421:3] info: 10.10.10.130 licensing.mp.microsoft.com. A IN 2025-06-25 20:45:20.547495+02:00 unbound 51421 [51421:2] info: 10.10.10.130 _ldap._tcp.dc._msdcs.topalia.es. SRV IN 2025-06-25 20:45:20.201110+02:00 unbound 51421 [51421:2] info: 10.10.10.130 geo.prod.do.dsp.mp.microsoft.com. A IN 2025-06-25 20:45:20.138644+02:00 unbound 51421 [51421:0] info: 10.10.10.130 _ldap._tcp.dc._msdcs.topalia.es. SRV IN 2025-06-25 20:45:19.583488+02:00 unbound 51421 [51421:2] info: 10.10.10.130 _ldap._tcp.dc._msdcs.topalia.es. SRV IN ...Honestly, I don’t know where else to look — I’m lost at this point...
-
You're running Snort on WAN? In blocking mode?
Can you see what the per core CPU usage is when this happens? Like is one core stuck at 100%? Try using at the CLI:
top -HaSP -
@stephenw10 yes i use snort in wan in blocking mode,
-
Are you hosting services behind the firewall? You have port forwards or routed traffic?
Otherwise running Snort on WAN if generally pretty useless. You just see alerts for all the drive-by traffic hitting the WAN and it's all blocked by the firewall anyway.
-
@stephenw10 I have OpenVPN and some services (ACME) published, although I try to limit access using GeoIP. Could Snort be the cause of the blocks?
-
@dcuadrados said in Problems With WAN Loss Cobnection:
The system starts getting overloaded at 20:44, and at 20:45 it reports this:
The first (== last events) lines are dpinger reloading, as a WAN event happened.
These events were (the previous two events) : it was killed. The most common reason is : the WAN went down.
The initial event (line at the bottom) : dpinger ... pings every 500 ms the ping-destination. You picked "8.8.8.8". packets; 21 %, didn't come back anymore.
WAN uplink saturated ? remember : ping or the ICMP protocol has a low priority, so any upstream (ISP or further along) router can decide to drop these packets. The result will be : your ISP connection goes down.
That's why picking "8.8.8.8" is a quick and very dirty, easy solution.
Way better would be to pick a nearby, closer to you, 'main' ISP router. Find one is not many hops (a hop is a router) away, and that replies to ping.@dcuadrados said in Problems With WAN Loss Cobnection:
yes i use snort in wan in blocking mode,
That's like driving on the highway during the night, and you cut the head light to see how far you can go ....
Or standing in the middle of the Florence supermax prison in Colorado, and start insulting everybody. You'll be a head-line within minutes.Consider this : we, the small players in the Internet world, with our pfSense, we shall not pay attention or 'scan' incoming WAN traffic that wasn't directed to our LAN(s)devices, or : filter traffic that wasn't a reply to a request coming from our LAN device, or : don't touch/look/scan/use/do something with useless random WAN traffic on your WAN interface.
Imagine : I know your WAN IP. I - just me - start sending many packets to your WAN IP with content that is known to trigger for example 'snort'. Every packet that get hit and detected by snort will consume 'millions' of extra CPU cycles : your pfSense goes in 100 % over drive mode. Every positive detected packet will get a line in the log, one for every packet - see your example.
I'll send you loads of small packets with a payload that make snort trigger : I'll saturate your disk.So, just me, with my 5 Gbits /sec upload can saturate your pfSense easily.
Now you start to understand why you shouldn't use snort on WAN.
The default firewall behavior will be : black hole the traffic : this is fast, easy to implement (it's the default method) and you're not at risk.
True, you can't tell anymore that the Internet is a dark place. But guess what : we already knew that.That said, no one isn't forbidding you to do whatever you want with your pfSense.
I'll hope you get the humor now : you post on the forum that you have WAN issues ...*
No sh*t .....
.....@dcuadrados said in Problems With WAN Loss Cobnection:
although I try to limit access using GeoIP
That's the way to go : it's fast, clean, you use pf as it was inteded to be sued.
Not 100 % foolproof of course, as this method allows your neighbor, using nearly the same WAN as you, so your GeoIP rules will accept the traffic.@dcuadrados said in Problems With WAN Loss Cobnection:
services (ACME) published
? How so ? You're using the build in http mode ? That method, and the rock bottom manual one, are 'last resort' solutions. Any other DNS API method is to be preferred, by far.
Normally, you should pick a registrar, the one from who you rent your domain name from, with the condition it offers you a DNS API method. Way easier. No open ports. No risk.@dcuadrados said in Problems With WAN Loss Cobnection:
I have OpenVPN
OpenVPN server, right ?
That's an exception. The OpenVPN server port (UDP 1194) doesn't need to be protected. It's meant to be used like that, it can handle the incoming rubbish.
That said, I do, as you, have a WAN GEO IP filter rule that only accepts connection from 'Europe' so as long as I stay in Europe, I can connect. The rest of the planet : nope.@dcuadrados said in Problems With WAN Loss Cobnection:
Could Snort be the cause of the blocks?
Possible.
Imagine this situation : snort detects a bad packet, so it puts the source IP into it's 'snort' alias table, and asks pf to reload the rules (and tables) => reloading the firewall rule set.
Now, you receive 'many' such bad packets.
The firewall will get reloaded as often. It will actually spend its time reloading, not filtering.
What do you think will happen with your quality of your uplink connectivity ?So, you can use snort of course.
But first : get a big uplink, like a 5+ Gbit / sec connection. I say "5"so you'll know your connection is bigger as the vast majority of the other Internet users.
Get a good NIC, with the same or better speed.
Get a good processor, go Xeon, assume the electricity bill. Get an airco to chill things down.
Get a big classic plated, spinning drive. Not a ssd or whatever thing.
Go 'iron mode'. So no VM ...
Now you can use snort and detect the bad onesBtw : your system will still go down when you get DDOSsed ....
Don't do this : The Man Who Angered Anonymous And Lived To Regret It. -
@Gertjan said in Problems With WAN Loss Cobnection:
DNS API
Thank you very much for your response. I had been meaning to set up ACME for a while, but honestly, I hadn’t done it out of laziness. I’ve now configured it, although I had the port open for only 30 minutes and restricted to IPs from the USA. But this way is definitely better—and it also lets me remove a pfBlocker list.
Regarding SNORT, I’m going to remove it from the WAN. To be honest, I set it up back in the day, but it really doesn’t make much sense—especially since all incoming WAN traffic is blocked by default, and what is open is only allowed for IPs from Spain (and if someone travels, we open access for that country).
In pfBlocker, under IP > Inbound Firewall Rules, it might also be a good idea to remove WAN.
As for the monitoring IPs, I’ll look for one that’s closer, although 8.8.8.8 replies in 5ms. I’ll try with another one. For now, I’m going to test all these possible solutions you’ve suggested. Thanks again for everything!
-
Yeah I would at least try disabling Snort on WAN and see what happens. If OpenVPN is the only service externally available that's not s big risk.
Running Snort like that means the alerts are pretty much useless because you will be seeing them continually. But more importantly it also increases the CPU loading significantly in the event of a flood of traffic. That makes it much more likely to start dropping packets if a CPU core is maxed out.
-
@stephenw10 perfect, i just delete WAN interface from Snort and only use LAN

-
Now you behave as the responsible Internet user !

As soon as snort sees that you send out suspected traffic, you can deal with it locally.
If some device is requesting suspected traffic from the Internet : same thing : go visit the user. -
@Gertjan I’m going to monitor the behavior, hoping for stable WAN performance with no more disconnections or freezes. I’ll keep you updated if anything comes up, and thank you so much for everything!
-
@dcuadrados said in Problems With WAN Loss Cobnection:
no more [WAN] disconnections
Your pfSEnse LAN is connected to switch. This connection normally never goes down.
Exactly the same thing is true for the WAN NIC. It will stay up forever.For the LAN switch, to do things even better, hook it up,to same UPS as the one pfSense uses, now even power won't bother you anymore.
Do the same thing for the WAN upstream device.That said, there is something else, to consdier for the WAN interface.
You, as an admin, gave pfSense the order to 'reset' the WAN interface if the ping test starts to fail.
If ping pacquets don't come back, something is wrong on the router to the ping destination.
This could be (hopefully) a local issue, so pulling down the WAN will 'inform' the upstream device to re create the connection. This was valid in the past when people where using cable modems and kind of upstream ISP devices, but way less an issue these days. If the connection goes down or bad because a satellite is hiding behind a cloud, you can have the WAN interface pulled down as many times as you want, it won't un-hide the satellite.
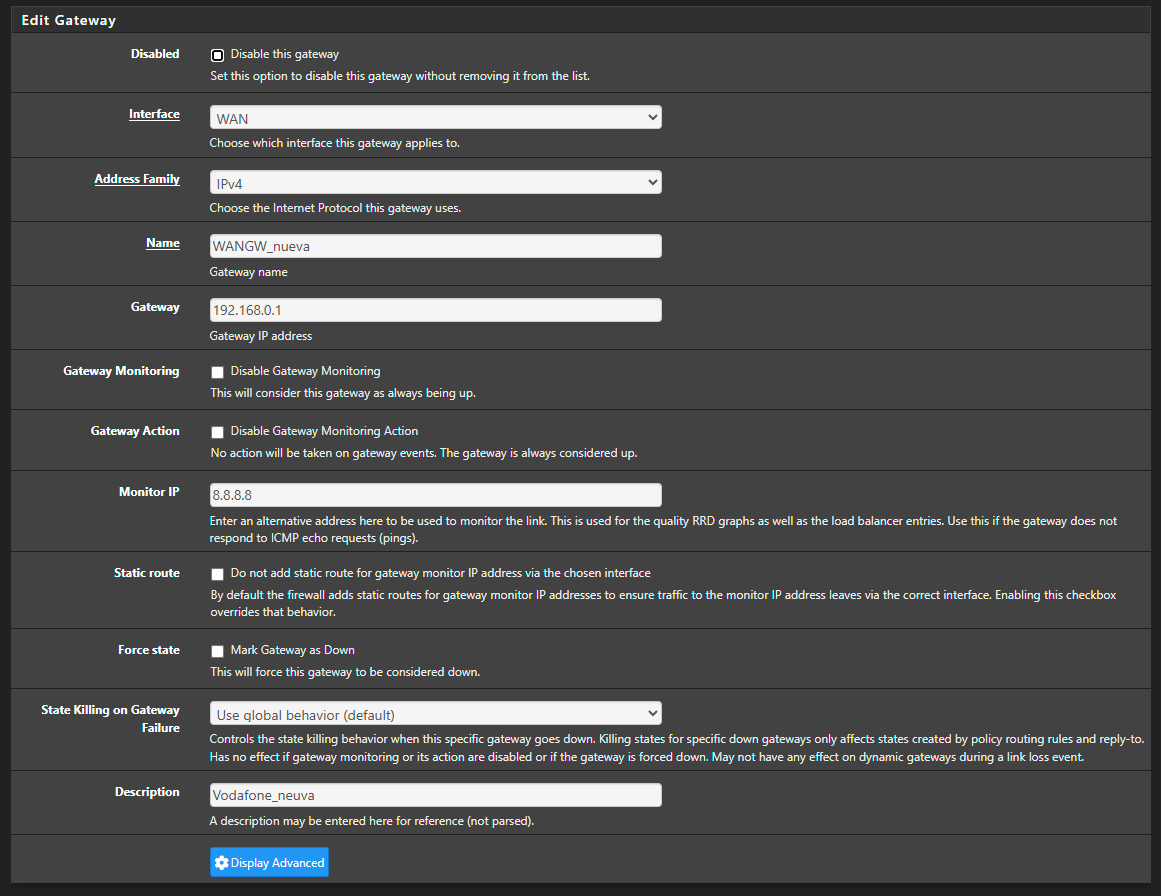
You can, depending on your type of connection, de activate the dpinger action :
Uncheck :
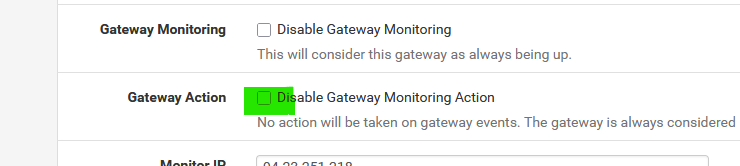
and from now on pfSense won't touch the WA interface anymore.
It's still possible that the device on the other side of the WAN cable pulls the connection down : that's ok, and you can't do anything about it. (except maybe looking for a more stable ISP, if one exist).The the issue is more upstream, you can't do anything about it, except waiting.
Keep in mind that ICMP (ping) packets also can get lost (dropped) if you saturate the connection.
Solution : stop doing so - or, for example, create 'pipes' where you can prioritize ICMP packets.
Or call you ISP and ask them for the "max" they can make available to you. -
@Gertjan Thank you so much for everything. I’m going to see if, with the current configuration, the WAN dropouts stop. Obviously, as you said, if the ISP goes down there’s not much that can be done—but in those cases, it usually comes back on its own if the ISP is completely down.
I’ll see how things go now with the changes made and hope for better performance. I’ll keep you updated. Thanks a million!
-
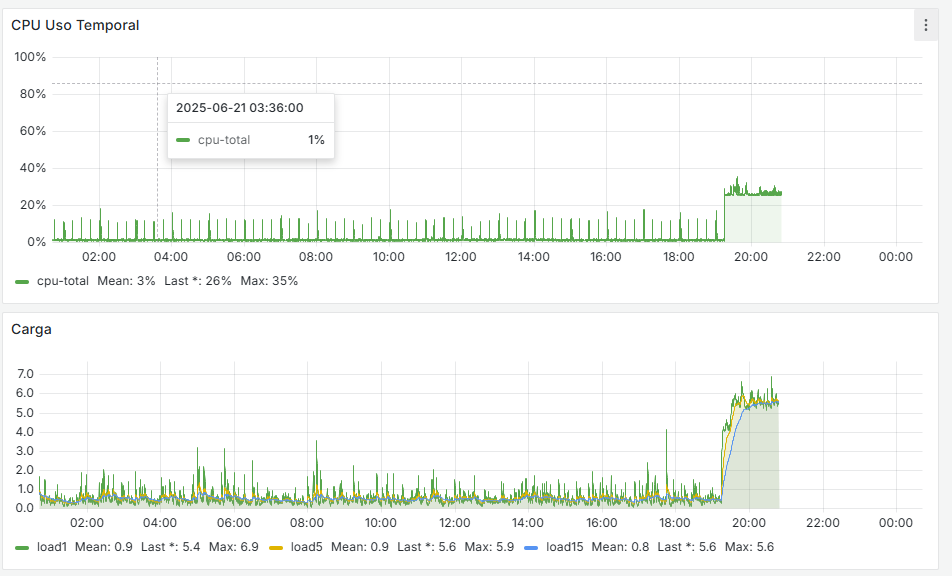
It’s happening again… I have two systems right now with the same issue. It’s honestly very frustrating. The logs show this:
Jun 26 23:47:14 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:13 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:13 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:12 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:12 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:11 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:11 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:10 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:10 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:09 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:09 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:08 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:08 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:07 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:07 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:06 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:06 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:05 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:04 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:04 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:03 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:03 dpinger 12135 GW_Movistar 8.8.8.8: sendto error: 13 Jun 26 23:47:02 dpinger 12135 GW_Movistar 8.8.8.8: Alarm latency 0us stddev 0us loss 100% Jun 26 23:47:00 dpinger 12135 send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% alarm_hold 10000ms dest_addr 8.8.8.8 bind_addr 192.168.1.254 identifier "GW_Movistar "Other FW:
2025-06-26 23:41:59.210553+02:00 dpinger 39125 WANGW_nueva 8.8.8.8: Alarm latency 0us stddev 0us loss 100% 2025-06-26 23:41:57.200434+02:00 dpinger 39125 send_interval 500ms loss_interval 2000ms time_period 60000ms report_interval 0ms data_len 1 alert_interval 1000ms latency_alarm 500ms loss_alarm 20% alarm_hold 10000ms dest_addr 8.8.8.8 bind_addr 192.168.0.254 identifier "WANGW_nueva " 2025-06-26 23:41:57.187617+02:00 dpinger 38486 exiting on signal 15 2025-06-26 23:15:19.233616+02:00 dpinger 38486 WANGW_nueva 8.8.8.8: Alarm latency 13213us stddev 3126us loss 22%I have remote access to them, and Uptime Kuma reports they are up, but the WAN is down and they have no internet access. I’ve already removed Snort from the WAN—it's only on the LAN now. I really don’t know what else it could be. Could it be due to using floating rules? I can’t think of anything else that might be causing this. These are the rules:
top -HaSP:
PID USERNAME PRI NICE SIZE RES STATE C TIME WCPU COMMAND 0 root -60 - 0B 1344K CPU2 2 43:40 100.00% [kernel{if_io_tqg_2}] 11 root 187 ki31 0B 64K CPU0 0 22.9H 99.56% [idle{idle: cpu0}] 11 root 187 ki31 0B 64K RUN 3 22.8H 90.45% [idle{idle: cpu3}] 11 root 187 ki31 0B 64K CPU1 1 23.0H 85.55% [idle{idle: cpu1}] 47858 root 20 0 1063M 934M bpf 1 6:06 0.29% /usr/local/bin/snort -R _10641 -M -D -q --suppress-config-log --daq pcap --daq-mode passive --treat-drop-as-alert -l /var/log/snort/snort_igc010641 --pid-path /var/run --nolock-pidfile --no-interface-pidfile -G 1 8220 root 20 0 17M 5156K CPU3 3 0:01 0.28% top -HaSP 61672 unbound 20 0 547M 496M kqread 1 2:53 0.19% /usr/local/sbin/unbound -c /var/unbound/unbound.conf{unbound} 33872 root 20 0 5655M 230M uwait 0 8:29 0.14% /usr/local/bin/telegraf -config=/usr/local/etc/telegraf.conf{telegraf} 7 root -16 - 0B 16K pftm 3 1:15 0.13% [pf purge] 33872 root 20 0 5655M 230M uwait 0 3:27 0.12% /usr/local/bin/telegraf -config=/usr/local/etc/telegraf.conf{telegraf} 0 root -60 - 0B 1344K - 1 1:49 0.08% [kernel{if_config_tqg_0}] 0 root -60 - 0B 1344K - 1 0:04 0.08% [kernel{softirq_1}] 0 root -60 - 0B 1344K - 3 0:03 0.05% [kernel{softirq_3}] 28381 root 20 0 22M 12M select 0 0:00 0.03% sshd: admin@pts/0 (sshd) 0 root -60 - 0B 1344K - 3 1:40 0.03% [kernel{if_io_tqg_3}] 97202 root 20 0 1187M 1005M bpf 1 7:06 0.03% /usr/local/bin/snort -R _5949 -M -D -q --suppress-config-log --daq pcap --daq-mode passive --treat-drop-as-alert -l /var/log/snort/snort_igc15949 --pid-path /var/run --nolock-pidfile --no-interface-pidfile -G 594 33872 root 20 0 5655M 230M uwait 3 3:17 0.03% /usr/local/bin/telegraf -config=/usr/local/etc/telegraf.conf{telegraf} 33872 root 20 0 5655M 230M kqread 0 3:15 0.02% /usr/local/bin/telegraf -config=/usr/local/etc/telegraf.conf{telegraf} 33872 root 20 0 5655M 230M kqread 0 3:02 0.02% /usr/local/bin/telegraf -config=/usr/local/etc/telegraf.conf{telegraf} 57489 root 20 0 13M 2908K kqread 0 0:24 0.02% /usr/bin/tail_pfb -n0 -F /var/log/filter.log 9 root -16 - 0B 48K psleep 3 0:27 0.02% [pagedaemon{dom0}] 44329 root 20 0 13M 2908K kqread 1 0:05 0.02% tail -F -n 0 /var/log/auth.log 46933 root 20 0 13M 2748K select 0 0:04 0.01% tail: system.fileargs (tail) 58244 root 20 0 13M 2748K select 3 0:18 0.01% tail_pfb: system.fileargs (tail_pfb) 73593 root 20 0 13M 3876K bpf 0 0:37 0.01% /usr/local/sbin/filterlog -i pflog0 -p /var/run/filterlog.pid 39125 root 20 0 17M 3160K nanslp 0 0:00 0.01% /usr/local/bin/dpinger -S -r 0 -i WANGW_nueva -B 192.168.0.254 -p /var/run/dpinger_WANGW_nueva~192.168.0.254~8.8.8.8.pid -u /var/run/dpinger_WANGW_nueva~192.168.0.254~8.8.8.8.sock -C /etc/rc.gateway_alarm -d 1 -s 0 root -60 - 0B 1344K - 0 0:03 0.01% [kernel{softirq_0}] 8 root -16 - 0B 16K - 3 0:14 0.01% [rand_harvestq] 33872 root 20 0 5655M 230M uwait 0 3:34 0.01% /usr/local/bin/telegraf -config=/usr/local/etc/telegraf.conf{telegraf} 57781 root 20 0 83M 63M piperd 3 117:59 0.01% /usr/local/bin/php_pfb -f /usr/local/pkg/pfblockerng/pfblockerng.inc filterlog 2 root -60 - 0B 64K WAIT 0 0:18 0.01% [clock{clock (0)}] 0 root -60 - 0B 1344K - 0 2:02 0.01% [kernel{if_io_tqg_0}] 44643 root 20 0 13M 3196K kqread 1 0:07 0.01% /usr/sbin/syslogd -O rfc5424 -s -c -c -l /var/dhcpd/var/run/log -P /var/run/syslog.pid -f /etc/syslog.conf 33872 root 20 0 5655M 230M uwait 3 1:22 0.01% /usr/local/bin/telegraf -config=/usr/local/etc/telegraf.conf{telegraf} 34247 root 20 0 102M 28M uwait 1 0:01 0.01% /usr/local/libexec/ipsec/charon --use-syslog{charon} 32522 root 20 0 24M 9160K select 1 0:07 0.01% /usr/local/sbin/ntpd -g -c /var/etc/ntpd.conf -p /var/run/ntpd.pid{ntpd} 0 root -12 - 0B 1344K - 3 1:45 0.01% [kernel{z_wr_iss_2}] 12 root -64 - 0B 224K WAIT 1 0:30 0.00% [intr{irq129: ahci0}] 34247 root 20 0 102M 28M uwait 3 0:02 0.00% /usr/local/libexec/ipsec/charon --use-syslog{charon} 12 root -60 - 0B 224K WAIT 3 0:39 0.00% [intr{swi1: netisr 3}] 6013 root 20 0 1184M 974M bpf 1 0:04 0.00% /usr/local/bin/snort -R _57509 -M -D -q --suppress-config-log --daq pcap --daq-mode passive --treat-drop-as-alert -l /var/log/snort/snort_ovpns157509 --pid-path /var/run --nolock-pidfile --no-interface-pidfile -G 58427 root 20 0 22M 10M kqread 3 0:15 0.00% /usr/local/sbin/lighttpd_pfb -f /var/unbound/pfb_dnsbl_lighty.conf 628 root 20 0 108M 32M kqread 0 0:03 0.00% php-fpm: master process (/usr/local/lib/php-fpm.conf) (php-fpm) 0 root -16 - 0B 1344K - 3 0:22 0.00% [kernel{z_wr_int_1}] 2 root -60 - 0B 64K WAIT 1 0:04 0.00% [clock{clock (1)}] 61672 unbound 20 0 547M 496M kqread 3 2:11 0.00% /usr/local/sbin/unbound -c /var/unbound/unbound.conf{unbound} 39125 root 20 0 17M 3160K nanslp 0 0:00 0.00% /usr/local/bin/dpinger -S -r 0 -i WANGW_nueva -B 192.168.0.254 -p /var/run/dpinger_WANGW_nueva~192.168.0.254~8.8.8.8.pid -u /var/run/dpinger_WANGW_nueva~192.168.0.254~8.8.8.8.sock -C /etc/rc.gateway_alarm -d 1 -s 16 root -60 - 0B 80K - 1 0:03 0.00% [usb{usbus0}] 33872 root 68 0 5655M 230M uwait 0 3:35 0.00% /usr/local/bin/telegraf -config=/usr/local/etc/telegraf.conf{telegraf} 6013 root 20 0 1184M 974M nanslp 1 0:02 0.00% /usr/local/bin/snort -R _57509 -M -D -q --suppress-config-log --daq pcap --daq-mode passive --treat-drop-as-alert -l /var/log/snort/snort_ovpns157509 --pid-path /var/run --nolock-pidfile --no-interface-pidfile -G 0 root -16 - 0B 1344K - 3 0:02 0.00% [kernel{z_null_int}] 47858 root 20 0 1063M 934M nanslp 0 0:02 0.00% /usr/local/bin/snort -R _10641 -M -D -q --suppress-config-log --daq pcap --daq-mode passive --treat-drop-as-alert -l /var/log/snort/snort_igc010641 --pid-path /var/run --nolock-pidfile --no-interface-pidfile -G 1 2 root -60 - 0B 64K WAIT 3 0:05 0.00% [clock{clock (3)}] 97202 root 20 0 1187M 1005M nanslp 3 0:02 0.00% /usr/local/bin/snort -R _5949 -M -D -q --suppress-config-log --daq pcap --daq-mode passive --treat-drop-as-alert -l /var/log/snort/snort_igc15949 --pid-path /var/run --nolock-pidfile --no-interface-pidfile -G 594 0 root -60 - 0B 1344K - 1 1:56 0.00% [kernel{if_io_tqg_1}] 6 root -8 - 0B 896K mmp->m 1 0:01 0.00% [zfskern{mmp_thread_enter}] 21 root 16 - 0B 16K syncer 1 0:01 0.00% [syncer] 0 root -16 - 0B 1344K - 3 0:01 0.00% [kernel{z_flush_int}]My system tuneables:
Tunable Name Description Value net.inet.ip.intr_queue_maxlen Cola de interrupciones ampliada 3000 net.inet6.ip6.intr_queue_maxlen Cola de interrupciones IPv6 3000 hw.igc.max_interrupt_rate Tasa de interrupciones del driver IGC 12000 hw.igc.rx_process_limit Limitar el procesamiento de RX en el driver IGC -1 net.inet.tcp.soreceive_stream Ajuste TCP 1 net.isr.maxthreads Hilos ISR (paralelismo de red) 1 net.isr.bindthreads Vincular hilos ISR a CPUs 1 net.isr.dispatch Distribución directa del tráfico ISR direct net.inet.rss.enabled RSS habilitado 1 net.inet.rss.bits RSS Bits (distribuir en múltiples núcleos) 2 hw.ix.flow_control Desactivar Flow Control (i225/i226) 0 dev.igc.0.fc Desactivar Flow Control en interfaces i225/i226 WAN 0 dev.igc.1.fc Desactivar Flow Control en interfaces i225/i226 LAN 0 kern.ipc.nmbclusters Aumentar tamaño del buffer de red (mbufs) 1000000 kern.ipc.nmbclusters Clusters de memoria (recomendado por Netgate) 1000000 net.inet.ip.portrange.first 1024 net.inet.tcp.blackhole Do not send RST on segments to closed ports 2 net.inet.udp.blackhole Do not send port unreachables for refused connects 1 net.inet.ip.random_id Assign random ip_id values 1 net.inet.tcp.drop_synfin Drop TCP packets with SYN+FIN set 1 net.inet.ip.redirect Enable sending IP redirects 1 net.inet6.ip6.redirect Send ICMPv6 redirects for unforwardable IPv6 packets 1 net.inet6.ip6.use_tempaddr Create RFC3041 temporary addresses for autoconfigured addresses 0 net.inet6.ip6.prefer_tempaddr Prefer RFC3041 temporary addresses in source address selection 0 net.inet.tcp.syncookies Use TCP SYN cookies if the syncache overflows 1 net.inet.tcp.recvspace Initial receive socket buffer size 65228 net.inet.tcp.sendspace Initial send socket buffer size 65228 net.inet.tcp.delayed_ack Delay ACK to try and piggyback it onto a data packet 0 net.inet.udp.maxdgram Maximum outgoing UDP datagram size 57344 net.link.bridge.pfil_onlyip Only pass IP packets when pfil is enabled 0 net.link.bridge.pfil_member Packet filter on the member interface 1 net.link.bridge.pfil_bridge Packet filter on the bridge interface 0 net.link.tap.user_open Enable legacy devfs interface creation for all users 1 net.link.vlan.mtag_pcp Retain VLAN PCP information as packets are passed up the stack 1 kern.randompid Random PID modulus. Special values: 0: disable, 1: choose random value 347 hw.syscons.kbd_reboot enable keyboard reboot 0 net.inet.tcp.log_debug Log errors caused by incoming TCP segments 0 net.inet.tcp.tso Enable TCP Segmentation Offload 1 net.inet.icmp.icmplim Maximum number of ICMP responses per second 0 vfs.read_max Cluster read-ahead max block count 32 kern.ipc.maxsockbuf Maximum socket buffer size 4262144 net.inet.ip.process_options Enable IP options processing ([LS]SRR, RR, TS) 0 kern.random.harvest.mask Entropy harvesting mask 351 net.route.netisr_maxqlen maximum routing socket dispatch queue length 1024 net.inet.udp.checksum compute udp checksum 1 net.inet.icmp.reply_from_interface ICMP reply from incoming interface for non-local packets 1 net.inet6.ip6.rfc6204w3 Accept the default router list from ICMPv6 RA messages even when packet forwarding is enabled 1 net.key.preferred_oldsa 0 net.inet.carp.senderr_demotion_factor Send error demotion factor adjustment 0 net.pfsync.carp_demotion_factor pfsync's CARP demotion factor adjustment 0 net.raw.recvspace 65536 net.raw.sendspace 65536 net.inet.raw.recvspace Maximum space for incoming raw IP datagrams 131072 net.inet.raw.maxdgram Maximum outgoing raw IP datagram size 131072 kern.corefile Process corefile name format string /root/%N.core kern.crypto.iimb.enable_aescbc enable AES-CBC cipher 1 kern.crypto.iimb.enable_multiq enable multi-Q 1 kern.crypto.iimb.use_task use taskq 0 kern.crypto.iimb.arch Set architecture auto kern.crypto.iimb.prefetch prefetch key for jobs 1 kern.crypto.iimb.max_jobs max number of jobs in batch 256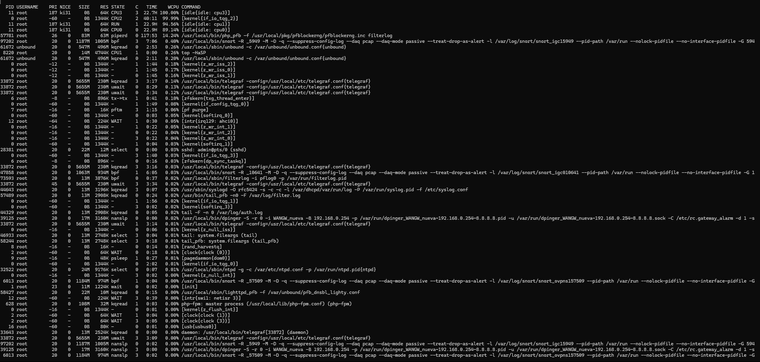
loader.conf:
kern.cam.boot_delay=10000 kern.geom.label.disk_ident.enable="0" kern.geom.label.gptid.enable="0" kern.ipc.nmbclusters="1000000" kern.ipc.nmbjumbo9="524288" kern.ipc.nmbjumbop="524288" opensolaris_load="YES" zfs_load="YES" opensolaris_load="YES" zfs_load="YES" kern.cam.boot_delay=10000 kern.geom.label.disk_ident.enable="0" kern.geom.label.gptid.enable="0" kern.ipc.nmbclusters="1000000" kern.ipc.nmbjumbo9="524288" kern.ipc.nmbjumbop="524288" kern.geom.label.disk_ident.enable="0" kern.geom.label.gptid.enable="0" cryptodev_load="YES" zfs_load="YES" kern.ipc.semopm=100 kern.ipc.semmni=128 kern.ipc.semmns=32000 kern.ipc.shmmni=4096 loader_conf_files="/boot/loader.conf.lua" boot_serial="NO" autoboot_delay="3" debug.ddb.capture.bufsize="524288" hw.e6000sw.default_disabled=1 hw.hn.vf_transparent="0" hw.hn.use_if_start="1" net.link.ifqmaxlen="128" machdep.hwpstate_pkg_ctrl="0" net.pf.states_hashsize="524288"Networking:
Rules:
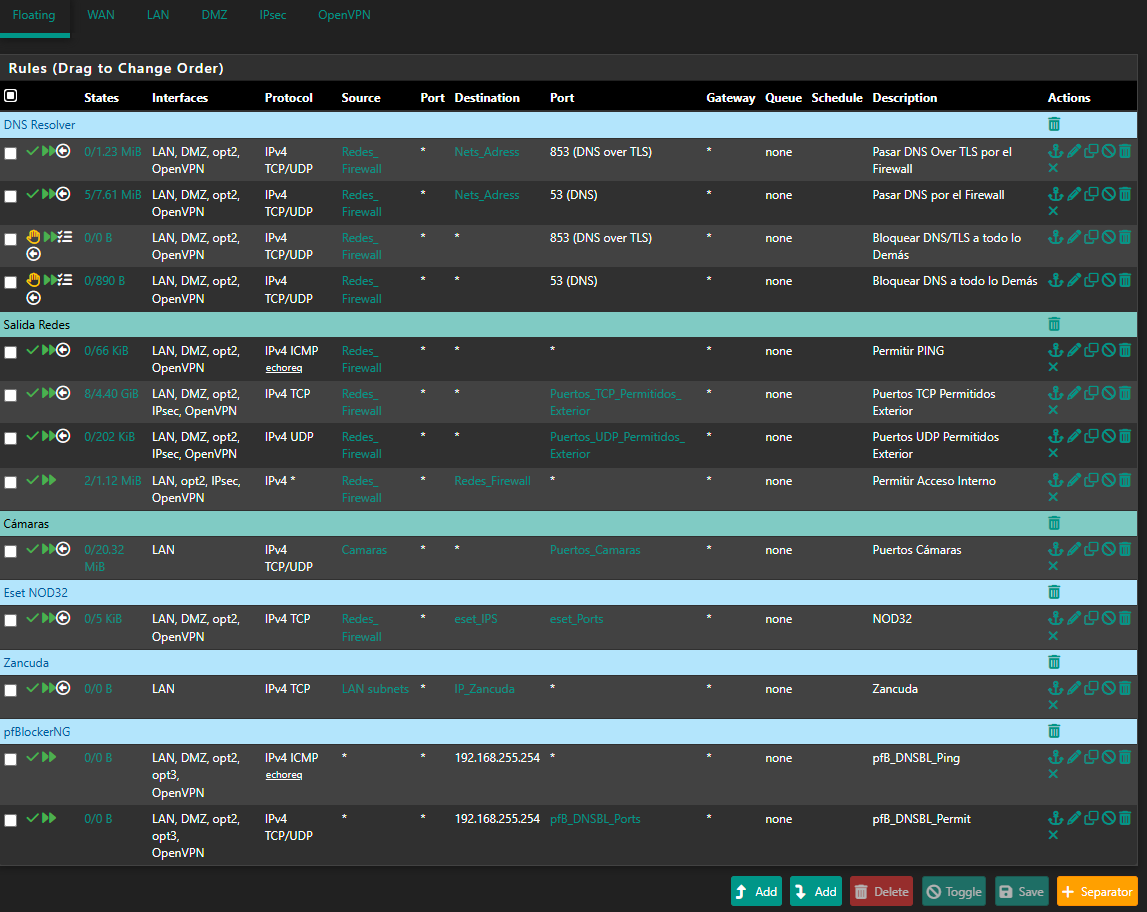
WAN:
-
sendto error 13 is 'permission denied' which doesn't make much sense unless it's being blocked upstream. I might imagine something triggering on the monitoring pings and blocking your IP.
Try running packet capture on WAN whilst in that state. Do you see icmp denied packets being returned from upstream?
-
@stephenw10 I no longer have access—it’s completely frozen. Until it’s restarted, I won’t be able to connect, which means I won’t have access until tomorrow. I don’t know what it could be—whether it’s Snort, the rules, pfBlocker, or some misconfiguration. The best thing would be to reformat everything, leave it clean without any rules, and start adding them little by little. Clearly, it’s a configuration issue—some mistake on my part. There’s no other explanation.
-
Are all three devices behind the same ISP devices? This could be the upstream device blocking the traffic if it has some DOS prevention for example. Though if that was the case I'd expect it to remain blocked for some time whether or not pfSense is rebooted. Assuming it pulls the same WAN IP.