WireGuard in pfSense 2.5 Performance
-
Never mind, I checked myself and putting
1420in the MSS field in the GUI results inmax-mss 1380in the rules. -
@dem I wonder if this is worth opening a redmine issue for. I can't see a reason why the max-mss shouldn't be set to to 1380 by default (1420-40) (...and rewording the GUI might be useful as well).
-
According to the report that I found the problem and submitted, wireguard has bugs in the linux kernel, I don't know if freebsd pfsense is involved. This is about mtu icmp and other issues
[wireguard kernel bug(link url)
-
@yon-0 So it does look like issues with path discovery, icmp, etc. That would make sense. I still think at least in the interim, that an MSS clamp should be enabled by default in pfSense until there is an upstream fix.
-
-
@rcmcdonald91
They are still working on repairing...
commit ee576c47db60432c37e54b1e2b43a8ca6d3a8dca upstream. The icmp{,v6}_send functions make all sorts of use of skb->cb, casting it with IPCB or IP6CB, assuming the skb to have come directly from the inet layer. But when the packet comes from the ndo layer, especially when forwarded, there's no telling what might be in skb->cb at that point. As a result, the icmp sending code risks reading bogus memory contents, which can result in nasty stack overflows such as this one reported by a user: panic+0x108/0x2ea __stack_chk_fail+0x14/0x20 __icmp_send+0x5bd/0x5c0 icmp_ndo_send+0x148/0x160 In icmp_send, skb->cb is cast with IPCB and an ip_options struct is read from it. The optlen parameter there is of particular note, as it can induce writes beyond bounds. There are quite a few ways that can happen in __ip_options_echo. For example: // sptr/skb are attacker-controlled skb bytes sptr = skb_network_header(skb); // dptr/dopt points to stack memory allocated by __icmp_send dptr = dopt->__data; // sopt is the corrupt skb->cb in question if (sopt->rr) { optlen = sptr[sopt->rr+1]; // corrupt skb->cb + skb->data soffset = sptr[sopt->rr+2]; // corrupt skb->cb + skb->data // this now writes potentially attacker-controlled data, over // flowing the stack: memcpy(dptr, sptr+sopt->rr, optlen); } In the icmpv6_send case, the story is similar, but not as dire, as only IP6CB(skb)->iif and IP6CB(skb)->dsthao are used. The dsthao case is worse than the iif case, but it is passed to ipv6_find_tlv, which does a bit of bounds checking on the value. This is easy to simulate by doing a `memset(skb->cb, 0x41, sizeof(skb->cb));` before calling icmp{,v6}_ndo_send, and it's only by good fortune and the rarity of icmp sending from that context that we've avoided reports like this until now. For example, in KASAN: BUG: KASAN: stack-out-of-bounds in __ip_options_echo+0xa0e/0x12b0 Write of size 38 at addr ffff888006f1f80e by task ping/89 CPU: 2 PID: 89 Comm: ping Not tainted 5.10.0-rc7-debug+ #5 Call Trace: dump_stack+0x9a/0xcc print_address_description.constprop.0+0x1a/0x160 __kasan_report.cold+0x20/0x38 kasan_report+0x32/0x40 check_memory_region+0x145/0x1a0 memcpy+0x39/0x60 __ip_options_echo+0xa0e/0x12b0 __icmp_send+0x744/0x1700 Actually, out of the 4 drivers that do this, only gtp zeroed the cb for the v4 case, while the rest did not. So this commit actually removes the gtp-specific zeroing, while putting the code where it belongs in the shared infrastructure of icmp{,v6}_ndo_send. This commit fixes the issue by passing an empty IPCB or IP6CB along to the functions that actually do the work. For the icmp_send, this was already trivial, thanks to __icmp_send providing the plumbing function. For icmpv6_send, this required a tiny bit of refactoring to make it behave like the v4 case, after which it was straight forward. -
Here is real world performance using a custom pfSense 2.5 at home... it is an older HP EliteDesk 800 G1, quad core i5-4570, 12GB RAM, 40GB SSD. I added a second intel NIC for WAN.
My pfSense at home is on a Telus gigabit purefibre connection 1Gbps up/down. Remote site with WireGuard is an SG-5100 21.02 on Telus managed business fibre symmetrical 1Gbps up/down.
Here is screenshot during 70GB of files transferred over SMB from a local Windows 2016 Server to an OMV NAS on remote end, which took about 13 minutes.
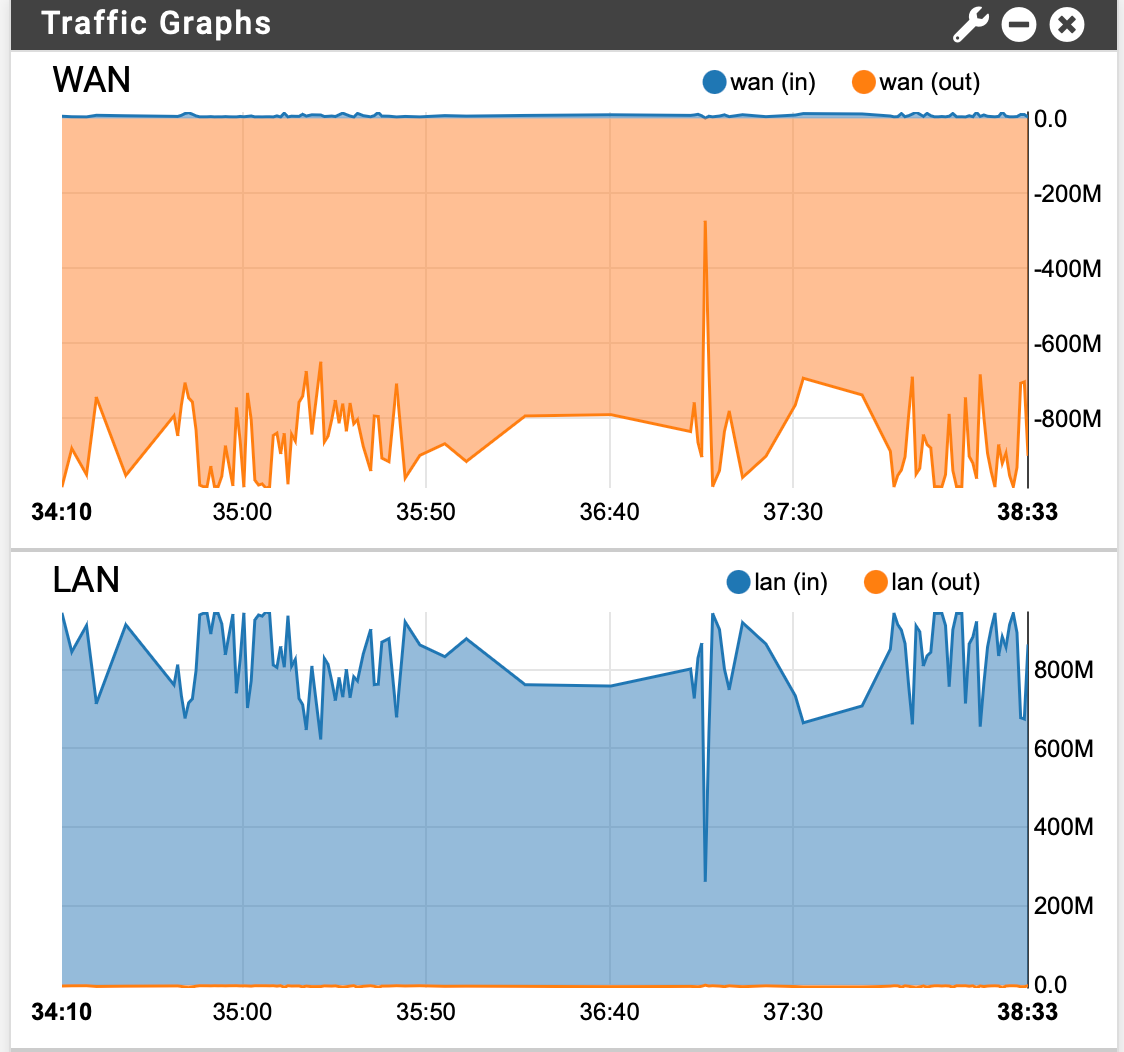
-
@brians Thanks for sharing! Would you be mind running iperf3 tests and share those as well? That'd remove any bottlenecks from SMB protocol or your NAS disks. You seem to have a very good setup since both locations share the same ISP, so I am curious to see iperf3 tests. Thanks!
-
@xparanoik
I waited until after work to do.
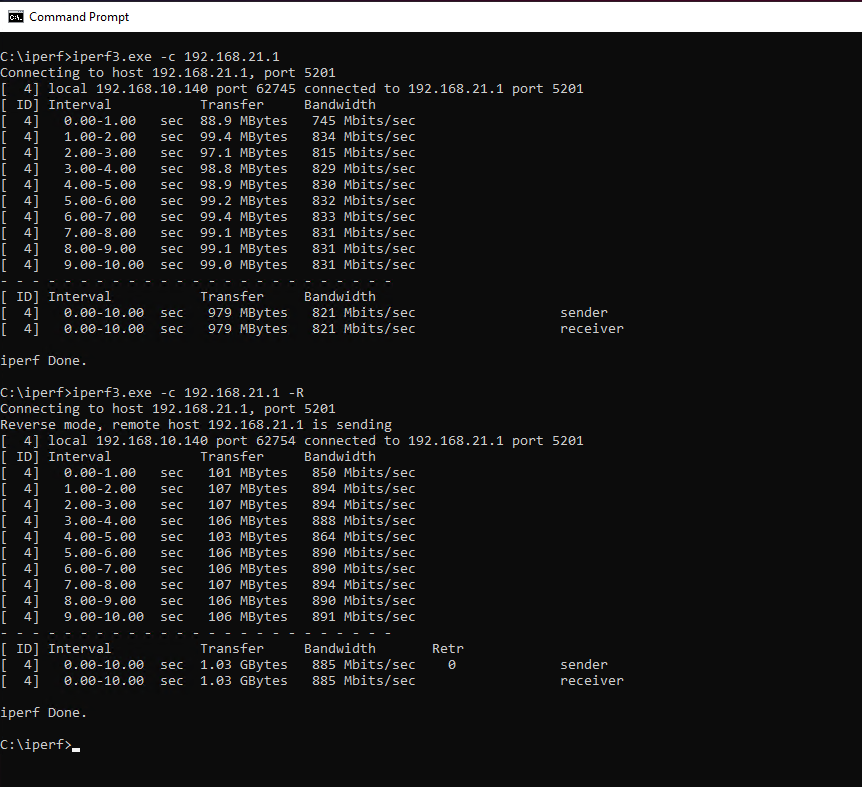
This is from a Windows 10 PC 192.168.10.140 at home connected to pfsense at work 192.168.21.1In past testing sometimes I get a bit higher send from my house in the 900's but today didn't seem to.
-
@brians Nice, thanks for sharing
-
WireGuard performance should soon be much improved:
https://www.phoronix.com/scan.php?page=news_item&px=FreeBSD-New-WireGuard
-
Oof. Not exactly a shining endorsement. I feel bad for Netgate here. They paid for Wireguard in FreeBSD because nobody else gave a damn and then a month after release, the protocol creator shows up and redoes it all for free.
-
@kom ugh... I’ll be anxiously biting my nails. The next 24-48 hrs are delicate for everyone involved.
-
https://lists.zx2c4.com/pipermail/wireguard/2021-March/006499.html
JFC, this is not shaping up to be professional conversation and collaboration. Netgate/pfSense I am so disappointed... Argh...
-
This post is deleted! -
@kom why feel bad for netgate?
netgate decided to spend money on one of their products & got a working "thingy" as a result ... netgate's goal has been meta month later someone else claims they'll supply an even better "thingy" for free.
this doesn't even matter to netgate because the decision to spend money on "thingy" is in the past. the money is gonewhat does matter:
we get a shit-throwing competition on reddit / phoronix & a mailing list
all this for FREE ... opensource entertainment at it's finest -
@heper It seems that Netgate should have coordinated with Jason D. and perhaps get his input on the patches they planned to submit, then this could have been avoided.
-
Netgate is being completely trashed in the comments of the Ars article. It seems that Netgate Scott's msg to Donenfeld isn't being received very well.
-
@xparanoik
Only the parties involved can comment on that.... Shoulda woulda coulda are pointless when uttered by outsiders -
@heper But my suggestion is still objectively a positive thing, assume the opposite is exactly what happeneed as said by Jason himself (and confirmed via other means, such as other mailing list threads).